 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayerFusion: Harmonized Multi-Layer Text-to-Image Generation with Generative Priors
Dec 05, 2024



Large-scale diffusion models have achieved remarkable success in generating high-quality images from textual descriptions, gaining popularity across various applications. However, the generation of layered content, such as transparent images with foreground and background layers, remains an under-explored area. Layered content generation is crucial for creative workflows in fields like graphic design, animation, and digital art, where layer-based approaches are fundamental for flexible editing and composition. In this paper, we propose a novel image generation pipeline based on Latent Diffusion Models (LDMs) that generates images with two layers: a foreground layer (RGBA) with transparency information and a background layer (RGB). Unlike existing methods that generate these layers sequentially, our approach introduces a harmonized generation mechanism that enables dynamic interactions between the layers for more coherent outputs. We demonstrate the effectiveness of our method through extensive qualitative and quantitative experiments, showing significant improvements in visual coherence, image quality, and layer consistency compared to baseline methods.
MetaShadow: Object-Centered Shadow Detection, Removal, and Synthesis
Dec 03, 2024



Shadows are often under-considered or even ignored in image editing applications, limiting the realism of the edited results. In this paper, we introduce MetaShadow, a three-in-one versatile framework that enables detection, removal, and controllable synthesis of shadows in natural images in an object-centered fashion. MetaShadow combines the strengths of two cooperative components: Shadow Analyzer, for object-centered shadow detection and removal, and Shadow Synthesizer, for reference-based controllable shadow synthesis. Notably, we optimize the learning of the intermediate features from Shadow Analyzer to guide Shadow Synthesizer to generate more realistic shadows that blend seamlessly with the scene. Extensive evaluations on multiple shadow benchmark datasets show significant improvements of MetaShadow over the existing state-of-the-art methods on object-centered shadow detection, removal, and synthesis. MetaShadow excels in image-editing tasks such as object removal, relocation, and insertion, pushing the boundaries of object-centered image editing.
XQ-GAN: An Open-source Image Tokenization Framework for Autoregressive Generation
Dec 02, 2024



Image tokenizers play a critical role in shaping the performance of subsequent generative models. Since the introduction of VQ-GAN, discrete image tokenization has undergone remarkable advancements. Improvements in architecture, quantization techniques, and training recipes have significantly enhanced both image reconstruction and the downstream generation quality. In this paper, we present XQ-GAN, an image tokenization framework designed for both image reconstruction and generation tasks. Our framework integrates state-of-the-art quantization techniques, including vector quantization (VQ), residual quantization (RQ), multi-scale residual quantization (MSVQ), product quantization (PQ), lookup-free quantization (LFQ), and binary spherical quantization (BSQ), within a highly flexible and customizable training environment. On the standard ImageNet 256x256 benchmark, our released model achieves an rFID of 0.64, significantly surpassing MAGVIT-v2 (0.9 rFID) and VAR (0.9 rFID). Furthermore, we demonstrate that using XQ-GAN as a tokenizer improves gFID metrics alongside rFID. For instance, with the same VAR architecture, XQ-GAN+VAR achieves a gFID of 2.6, outperforming VAR's 3.3 gFID by a notable margin. To support further research, we provide pre-trained weights of different image tokenizers for the community to directly train the subsequent generative models on it or fine-tune for specialized tasks.
Refine-by-Align: Reference-Guided Artifacts Refinement through Semantic Alignment
Nov 30, 2024


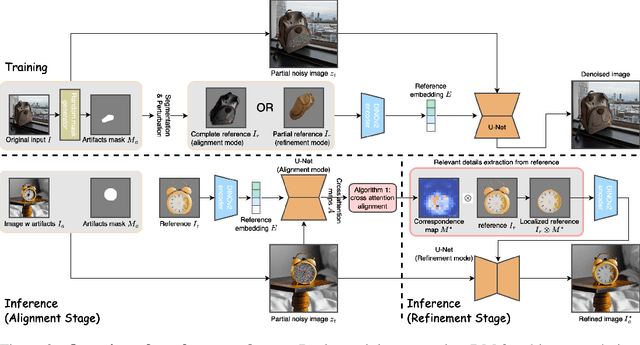
Personalized image generation has emerged from the recent advancements in generative models. However, these generated personalized images often suffer from localized artifacts such as incorrect logos, reducing fidelity and fine-grained identity details of the generated results. Furthermore, there is little prior work tackling this problem. To help improve these identity details in the personalized image generation, we introduce a new task: reference-guided artifacts refinement. We present Refine-by-Align, a first-of-its-kind model that employs a diffusion-based framework to address this challenge. Our model consists of two stages: Alignment Stage and Refinement Stage, which share weights of a unified neural network model. Given a generated image, a masked artifact region, and a reference image, the alignment stage identifies and extracts the corresponding regional features in the reference, which are then used by the refinement stage to fix the artifacts. Our model-agnostic pipeline requires no test-time tuning or optimization. It automatically enhances image fidelity and reference identity in the generated image, generalizing well to existing models on various tasks including but not limited to customization, generative compositing, view synthesis, and virtual try-on. Extensive experiments and comparisons demonstrate that our pipeline greatly pushes the boundary of fine details in the image synthesis models.
Generative Image Layer Decomposition with Visual Effects
Nov 26, 2024



Recent advancements in large generative models, particularly diffusion-based methods, have significantly enhanced the capabilities of image editing. However, achieving precise control over image composition tasks remains a challenge. Layered representations, which allow for independent editing of image components, are essential for user-driven content creation, yet existing approaches often struggle to decompose image into plausible layers with accurately retained transparent visual effects such as shadows and reflections. We propose $\textbf{LayerDecomp}$, a generative framework for image layer decomposition which outputs photorealistic clean backgrounds and high-quality transparent foregrounds with faithfully preserved visual effects. To enable effective training, we first introduce a dataset preparation pipeline that automatically scales up simulated multi-layer data with synthesized visual effects. To further enhance real-world applicability, we supplement this simulated dataset with camera-captured images containing natural visual effects. Additionally, we propose a consistency loss which enforces the model to learn accurate representations for the transparent foreground layer when ground-truth annotations are not available. Our method achieves superior quality in layer decomposition, outperforming existing approaches in object removal and spatial editing tasks across several benchmarks and multiple user studies, unlocking various creative possibilities for layer-wise image editing. The project page is https://rayjryang.github.io/LayerDecomp.
Baking Gaussian Splatting into Diffusion Denoiser for Fast and Scalable Single-stage Image-to-3D Generation
Nov 21, 2024



Existing feed-forward image-to-3D methods mainly rely on 2D multi-view diffusion models that cannot guarantee 3D consistency. These methods easily collapse when changing the prompt view direction and mainly handle object-centric prompt images. In this paper, we propose a novel single-stage 3D diffusion model, DiffusionGS, for object and scene generation from a single view. DiffusionGS directly outputs 3D Gaussian point clouds at each timestep to enforce view consistency and allow the model to generate robustly given prompt views of any directions, beyond object-centric inputs. Plus, to improve the capability and generalization ability of DiffusionGS, we scale up 3D training data by developing a scene-object mixed training strategy. Experiments show that our method enjoys better generation quality (2.20 dB higher in PSNR and 23.25 lower in FID) and over 5x faster speed (~6s on an A100 GPU) than SOTA methods. The user study and text-to-3D applications also reveals the practical values of our method. Our Project page at https://caiyuanhao1998.github.io/project/DiffusionGS/ shows the video and interactive generation results.
ImageFolder: Autoregressive Image Generation with Folded Tokens
Oct 02, 2024



Image tokenizers are crucial for visual generative models, e.g., diffusion models (DMs) and autoregressive (AR) models, as they construct the latent representation for modeling. Increasing token length is a common approach to improve the image reconstruction quality. However, tokenizers with longer token lengths are not guaranteed to achieve better generation quality. There exists a trade-off between reconstruction and generation quality regarding token length. In this paper, we investigate the impact of token length on both image reconstruction and generation and provide a flexible solution to the tradeoff. We propose ImageFolder, a semantic tokenizer that provides spatially aligned image tokens that can be folded during autoregressive modeling to improve both generation efficiency and quality. To enhance the representative capability without increasing token length, we leverage dual-branch product quantization to capture different contexts of images. Specifically, semantic regularization is introduced in one branch to encourage compacted semantic information while another branch is designed to capture the remaining pixel-level details. Extensive experiments demonstrate the superior quality of image generation and shorter token length with ImageFolder tokenizer.
Removing Distributional Discrepancies in Captions Improves Image-Text Alignment
Oct 01, 2024



In this paper, we introduce a model designed to improve the prediction of image-text alignment, targeting the challenge of compositional understanding in current visual-language models. Our approach focuses on generating high-quality training datasets for the alignment task by producing mixed-type negative captions derived from positive ones. Critically, we address the distribution imbalance between positive and negative captions to ensure that the alignment model does not depend solely on textual information but also considers the associated images for predicting alignment accurately. By creating this enhanced training data, we fine-tune an existing leading visual-language model to boost its capability in understanding alignment. Our model significantly outperforms current top-performing methods across various datasets. We also demonstrate the applicability of our model by ranking the images generated by text-to-image models based on text alignment. Project page: \url{https://yuheng-li.github.io/LLaVA-score/}
Thinking Outside the BBox: Unconstrained Generative Object Compositing
Sep 11, 2024Compositing an object into an image involves multiple non-trivial sub-tasks such as object placement and scaling, color/lighting harmonization, viewpoint/geometry adjustment, and shadow/reflection generation. Recent generative image compositing methods leverage diffusion models to handle multiple sub-tasks at once. However, existing models face limitations due to their reliance on masking the original object during training, which constrains their generation to the input mask. Furthermore, obtaining an accurate input mask specifying the location and scale of the object in a new image can be highly challenging. To overcome such limitations, we define a novel problem of unconstrained generative object compositing, i.e., the generation is not bounded by the mask, and train a diffusion-based model on a synthesized paired dataset. Our first-of-its-kind model is able to generate object effects such as shadows and reflections that go beyond the mask, enhancing image realism. Additionally, if an empty mask is provided, our model automatically places the object in diverse natural locations and scales, accelerating the compositing workflow. Our model outperforms existing object placement and compositing models in various quality metrics and user studies.
Efficient Autoregressive Audio Modeling via Next-Scale Prediction
Aug 16, 2024



Audio generation has achieved remarkable progress with the advance of sophisticated generative models, such as diffusion models (DMs) and autoregressive (AR) models. However, due to the naturally significant sequence length of audio, the efficiency of audio generation remains an essential issue to be addressed, especially for AR models that are incorporated in large language models (LLMs). In this paper, we analyze the token length of audio tokenization and propose a novel \textbf{S}cale-level \textbf{A}udio \textbf{T}okenizer (SAT), with improved residual quantization. Based on SAT, a scale-level \textbf{A}coustic \textbf{A}uto\textbf{R}egressive (AAR) modeling framework is further proposed, which shifts the next-token AR prediction to next-scale AR prediction, significantly reducing the training cost and inference time. To validate the effectiveness of the proposed approach, we comprehensively analyze design choices and demonstrate the proposed AAR framework achieves a remarkable \textbf{35}$\times$ faster inference speed and +\textbf{1.33} Fr\'echet Audio Distance (FAD) against baselines on the AudioSet benchmark. Code: \url{https://github.com/qiuk2/AAR}.