 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAAP: Capture-Aware Adversarial Patch Attacks on Palmprint Recognition Models
Apr 08, 2026Palmprint recognition is deployed in security-critical applications, including access control and palm-based payment, due to its contactless acquisition and highly discriminative ridge-and-crease textures. However, the robustness of deep palmprint recognition systems against physically realizable attacks remains insufficiently understood. Existing studies are largely confined to the digital setting and do not adequately account for the texture-dominant nature of palmprint recognition or the distortions introduced during physical acquisition. To address this gap, we propose CAAP, a capture-aware adversarial patch framework for palmprint recognition. CAAP learns a universal patch that can be reused across inputs while remaining effective under realistic acquisition variation. To match the structural characteristics of palmprints, the framework adopts a cross-shaped patch topology, which enlarges spatial coverage under a fixed pixel budget and more effectively disrupts long-range texture continuity. CAAP further integrates three modules: ASIT for input-conditioned patch rendering, RaS for stochastic capture-aware simulation, and MS-DIFE for feature-level identity-disruptive guidance. We evaluate CAAP on the Tongji, IITD, and AISEC datasets against generic CNN backbones and palmprint-specific recognition models. Experiments show that CAAP achieves strong untargeted and targeted attack performance with favorable cross-model and cross-dataset transferability. The results further show that, although adversarial training can partially reduce the attack success rate, substantial residual vulnerability remains. These findings indicate that deep palmprint recognition systems remain vulnerable to physically realizable, capture-aware adversarial patch attacks, underscoring the need for more effective defenses in practice. Code available at https://github.com/ryliu68/CAAP.
Paper Espresso: From Paper Overload to Research Insight
Apr 06, 2026The accelerating pace of scientific publishing makes it increasingly difficult for researchers to stay current. We present Paper Espresso, an open-source platform that automatically discovers, summarizes, and analyzes trending arXiv papers. The system uses large language models (LLMs) to generate structured summaries with topical labels and keywords, and provides multi-granularity trend analysis at daily, weekly, and monthly scales through LLM-driven topic consolidation. Over 35 months of continuous deployment, Paper Espresso has processed over 13,300 papers and publicly released all structured metadata, revealing rich dynamics in the AI research landscape: a mid-2025 surge in reinforcement learning for LLM reasoning, non-saturating topic emergence (6,673 unique topics), and a positive correlation between topic novelty and community engagement (2.0x median upvotes for the most novel papers). A live demo is available at https://huggingface.co/spaces/Elfsong/Paper_Espresso.
Afterburner: Reinforcement Learning Facilitates Self-Improving Code Efficiency Optimization
May 29, 2025



Large Language Models (LLMs) generate functionally correct solutions but often fall short in code efficiency, a critical bottleneck for real-world deployment. In this paper, we introduce a novel test-time iterative optimization framework to address this, employing a closed-loop system where LLMs iteratively refine code based on empirical performance feedback from an execution sandbox. We explore three training strategies: Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO), and Group Relative Policy Optimization~(GRPO). Experiments on our Venus dataset and the APPS benchmark show that SFT and DPO rapidly saturate in efficiency gains. In contrast, GRPO, using reinforcement learning (RL) with execution feedback, continuously optimizes code performance, significantly boosting both pass@1 (from 47% to 62%) and the likelihood of outperforming human submissions in efficiency (from 31% to 45%). Our work demonstrates effective test-time code efficiency improvement and critically reveals the power of RL in teaching LLMs to truly self-improve code efficiency.
FGAD: Self-boosted Knowledge Distillation for An Effective Federated Graph Anomaly Detection Framework
Feb 20, 2024Graph anomaly detection (GAD) aims to identify anomalous graphs that significantly deviate from other ones, which has raised growing attention due to the broad existence and complexity of graph-structured data in many real-world scenarios. However, existing GAD methods usually execute with centralized training, which may lead to privacy leakage risk in some sensitive cases, thereby impeding collaboration among organizations seeking to collectively develop robust GAD models. Although federated learning offers a promising solution, the prevalent non-IID problems and high communication costs present significant challenges, particularly pronounced in collaborations with graph data distributed among different participants. To tackle these challenges, we propose an effective federated graph anomaly detection framework (FGAD). We first introduce an anomaly generator to perturb the normal graphs to be anomalous, and train a powerful anomaly detector by distinguishing generated anomalous graphs from normal ones. Then, we leverage a student model to distill knowledge from the trained anomaly detector (teacher model), which aims to maintain the personality of local models and alleviate the adverse impact of non-IID problems. Moreover, we design an effective collaborative learning mechanism that facilitates the personalization preservation of local models and significantly reduces communication costs among clients. Empirical results of the GAD tasks on non-IID graphs compared with state-of-the-art baselines demonstrate the superiority and efficiency of the proposed FGAD method.
From Static to Dynamic: A Continual Learning Framework for Large Language Models
Oct 22, 2023



The vast number of parameters in large language models (LLMs) endows them with remarkable capabilities, allowing them to excel in a variety of natural language processing tasks. However, this complexity also presents challenges, making LLMs difficult to train and inhibiting their ability to continuously assimilate new knowledge, which may lead to inaccuracies in their outputs. To mitigate these issues, this paper presents DynaMind, a novel continual learning framework designed for LLMs. DynaMind incorporates memory mechanisms to assimilate new knowledge and modular operators to enhance the model inference process with the newly assimilated knowledge, consequently improving the accuracies of LLMs' outputs. Benchmark experiments demonstrate DynaMind's effectiveness in overcoming these challenges. The code and demo of DynaMind are available on GitHub: https://github.com/Elfsong/DynaMind.
Anomaly Detection with Generative Adversarial Networks for Multivariate Time Series
Oct 09, 2018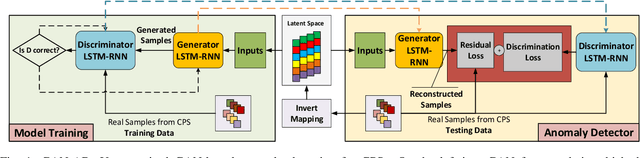
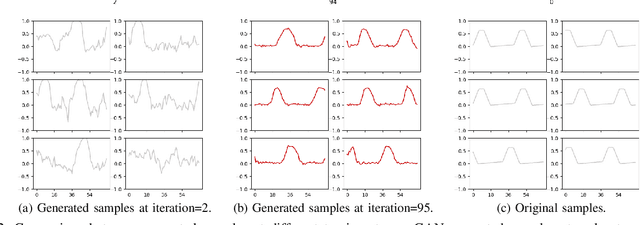
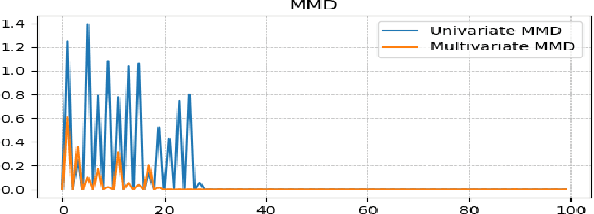
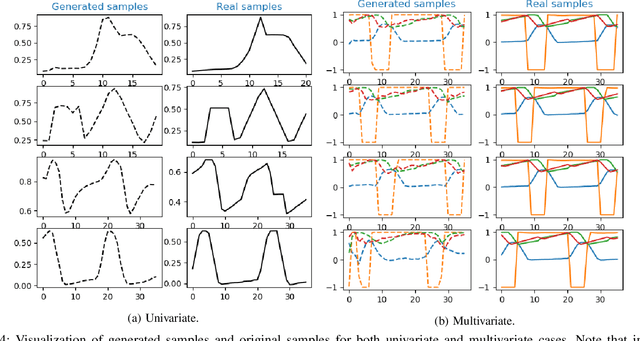
Today's Cyber-Physical Systems (CPSs) are large, complex, and affixed with networked sensors and actuators that are targets for cyber-attacks. Conventional detection techniques are unable to deal with the increasingly dynamic and complex nature of the CPSs. On the other hand, the networked sensors and actuators generate large amounts of data streams that can be continuously monitored for intrusion events. Unsupervised machine learning techniques can be used to model the system behaviour and classify deviant behaviours as possible attacks. In this work, we proposed a novel Generative Adversarial Networks-based Anomaly Detection (GAN-AD) method for such complex networked CPSs. We used LSTM-RNN in our GAN to capture the distribution of the multivariate time series of the sensors and actuators under normal working conditions of a CPS. Instead of treating each sensor's and actuator's time series independently, we model the time series of multiple sensors and actuators in the CPS concurrently to take into account of potential latent interactions between them. To exploit both the generator and the discriminator of our GAN, we deployed the GAN-trained discriminator together with the residuals between generator-reconstructed data and the actual samples to detect possible anomalies in the complex CPS. We used our GAN-AD to distinguish abnormal attacked situations from normal working conditions for a complex six-stage Secure Water Treatment (SWaT) system. Experimental results showed that the proposed strategy is effective in identifying anomalies caused by various attacks with high detection rate and low false positive rate as compared to existing methods.