 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAfterburner: Reinforcement Learning Facilitates Self-Improving Code Efficiency Optimization
May 29, 2025



Large Language Models (LLMs) generate functionally correct solutions but often fall short in code efficiency, a critical bottleneck for real-world deployment. In this paper, we introduce a novel test-time iterative optimization framework to address this, employing a closed-loop system where LLMs iteratively refine code based on empirical performance feedback from an execution sandbox. We explore three training strategies: Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO), and Group Relative Policy Optimization~(GRPO). Experiments on our Venus dataset and the APPS benchmark show that SFT and DPO rapidly saturate in efficiency gains. In contrast, GRPO, using reinforcement learning (RL) with execution feedback, continuously optimizes code performance, significantly boosting both pass@1 (from 47% to 62%) and the likelihood of outperforming human submissions in efficiency (from 31% to 45%). Our work demonstrates effective test-time code efficiency improvement and critically reveals the power of RL in teaching LLMs to truly self-improve code efficiency.
EffiBench-X: A Multi-Language Benchmark for Measuring Efficiency of LLM-Generated Code
May 19, 2025



Existing code generation benchmarks primarily evaluate functional correctness, with limited focus on code efficiency and often restricted to a single language like Python. To address this gap, we introduce EffiBench-X, the first multi-language benchmark designed to measure the efficiency of LLM-generated code. EffiBench-X supports Python, C++, Java, JavaScript, Ruby, and Golang. It comprises competitive programming tasks with human-expert solutions as efficiency baselines. Evaluating state-of-the-art LLMs on EffiBench-X reveals that while models generate functionally correct code, they consistently underperform human experts in efficiency. Even the most efficient LLM-generated solutions (Qwen3-32B) achieve only around \textbf{62\%} of human efficiency on average, with significant language-specific variations. LLMs show better efficiency in Python, Ruby, and JavaScript than in Java, C++, and Golang. For instance, DeepSeek-R1's Python code is significantly more efficient than its Java code. These results highlight the critical need for research into LLM optimization techniques to improve code efficiency across diverse languages. The dataset and evaluation infrastructure are submitted and available at https://github.com/EffiBench/EffiBench-X.git and https://huggingface.co/datasets/EffiBench/effibench-x.
Effi-Code: Unleashing Code Efficiency in Language Models
Oct 14, 2024



As the use of large language models (LLMs) for code generation becomes more prevalent in software development, it is critical to enhance both the efficiency and correctness of the generated code. Existing methods and models primarily focus on the correctness of LLM-generated code, ignoring efficiency. In this work, we present Effi-Code, an approach to enhancing code generation in LLMs that can improve both efficiency and correctness. We introduce a Self-Optimization process based on Overhead Profiling that leverages open-source LLMs to generate a high-quality dataset of correct and efficient code samples. This dataset is then used to fine-tune various LLMs. Our method involves the iterative refinement of generated code, guided by runtime performance metrics and correctness checks. Extensive experiments demonstrate that models fine-tuned on the Effi-Code show significant improvements in both code correctness and efficiency across task types. For example, the pass@1 of DeepSeek-Coder-6.7B-Instruct generated code increases from \textbf{43.3\%} to \textbf{76.8\%}, and the average execution time for the same correct tasks decreases by \textbf{30.5\%}. Effi-Code offers a scalable and generalizable approach to improving code generation in AI systems, with potential applications in software development, algorithm design, and computational problem-solving. The source code of Effi-Code was released in \url{https://github.com/huangd1999/Effi-Code}.
Hybrid-Parallel: Achieving High Performance and Energy Efficient Distributed Inference on Robots
May 29, 2024



The rapid advancements in machine learning techniques have led to significant achievements in various real-world robotic tasks. These tasks heavily rely on fast and energy-efficient inference of deep neural network (DNN) models when deployed on robots. To enhance inference performance, distributed inference has emerged as a promising approach, parallelizing inference across multiple powerful GPU devices in modern data centers using techniques such as data parallelism, tensor parallelism, and pipeline parallelism. However, when deployed on real-world robots, existing parallel methods fail to provide low inference latency and meet the energy requirements due to the limited bandwidth of robotic IoT. We present Hybrid-Parallel, a high-performance distributed inference system optimized for robotic IoT. Hybrid-Parallel employs a fine-grained approach to parallelize inference at the granularity of local operators within DNN layers (i.e., operators that can be computed independently with the partial input, such as the convolution kernel in the convolution layer). By doing so, Hybrid-Parallel enables different operators of different layers to be computed and transmitted concurrently, and overlap the computation and transmission phases within the same inference task. The evaluation demonstrate that Hybrid-Parallel reduces inference time by 14.9% ~41.1% and energy consumption per inference by up to 35.3% compared to the state-of-the-art baselines.
SOAP: Enhancing Efficiency of Generated Code via Self-Optimization
May 24, 2024



Large language models (LLMs) have shown remarkable progress in code generation, but their generated code often suffers from inefficiency, resulting in longer execution times and higher memory consumption. To address this issue, we propose Self Optimization based on OverheAd Profile (SOAP), a self-optimization framework that utilizes execution overhead profiles to improve the efficiency of LLM-generated code. SOAP first generates code using an LLM, then executes it locally to capture execution time and memory usage profiles. These profiles are fed back to the LLM, which then revises the code to reduce overhead. To evaluate the effectiveness of SOAP, we conduct extensive experiments on the EffiBench, HumanEval, and MBPP with 16 open-source and 6 closed-source models. Our evaluation results demonstrate that through iterative self-optimization, SOAP significantly enhances the efficiency of LLM-generated code. For example, the execution time (ET) of StarCoder2-15B for the EffiBench decreases from 0.93 (s) to 0.12 (s) which reduces 87.1% execution time requirement compared with the initial code. The total memory usage (TMU) of StarCoder2-15B also decreases from 22.02 (Mb*s) to 2.03 (Mb*s), which decreases 90.8% total memory consumption during the execution process. The source code of SOAP was released in https://github.com/huangd1999/SOAP.
EffiBench: Benchmarking the Efficiency of Automatically Generated Code
Feb 15, 2024Code generation models have increasingly become integral to aiding software development, offering assistance in tasks such as code completion, debugging, and code translation. Although current research has thoroughly examined the correctness of code produced by code generation models, a vital aspect, i.e., the efficiency of the generated code, has often been neglected. This paper presents EffiBench, a benchmark with 1,000 efficiency-critical coding problems for assessing the efficiency of code generated by code generation models. EffiBench contains a diverse set of LeetCode coding problems. Each problem is paired with an executable human-written canonical solution. With EffiBench, we empirically examine the capability of 21 Large Language Models (13 open-sourced and 8 closed-sourced) in generating efficient code. The results demonstrate that GPT-4-turbo generates the most efficient code, significantly outperforming Palm-2-chat-bison, Claude-instant-1, Gemini-pro, GPT-4, and GPT-3.5. Nevertheless, its code efficiency is still worse than the efficiency of human-written canonical solutions. In particular, the average and worst execution time of GPT-4-turbo generated code is 1.69 and 45.49 times that of the canonical solutions.
Neuron Sensitivity Guided Test Case Selection for Deep Learning Testing
Jul 20, 2023Deep Neural Networks~(DNNs) have been widely deployed in software to address various tasks~(e.g., autonomous driving, medical diagnosis). However, they could also produce incorrect behaviors that result in financial losses and even threaten human safety. To reveal the incorrect behaviors in DNN and repair them, DNN developers often collect rich unlabeled datasets from the natural world and label them to test the DNN models. However, properly labeling a large number of unlabeled datasets is a highly expensive and time-consuming task. To address the above-mentioned problem, we propose NSS, Neuron Sensitivity guided test case Selection, which can reduce the labeling time by selecting valuable test cases from unlabeled datasets. NSS leverages the internal neuron's information induced by test cases to select valuable test cases, which have high confidence in causing the model to behave incorrectly. We evaluate NSS with four widely used datasets and four well-designed DNN models compared to SOTA baseline methods. The results show that NSS performs well in assessing the test cases' probability of fault triggering and model improvement capabilities. Specifically, compared with baseline approaches, NSS obtains a higher fault detection rate~(e.g., when selecting 5\% test case from the unlabeled dataset in MNIST \& LeNet1 experiment, NSS can obtain 81.8\% fault detection rate, 20\% higher than baselines).
Two Heads are Better than One: Robust Learning Meets Multi-branch Models
Aug 17, 2022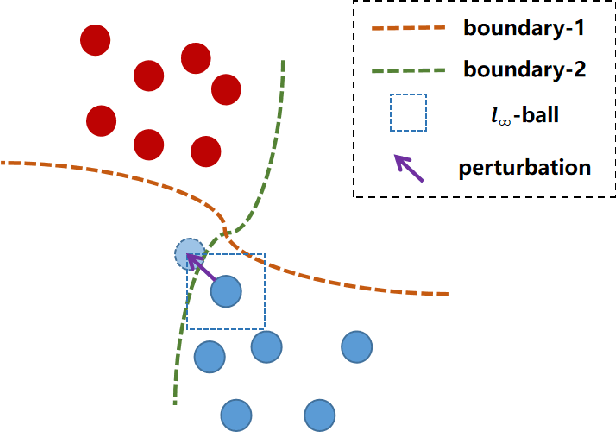
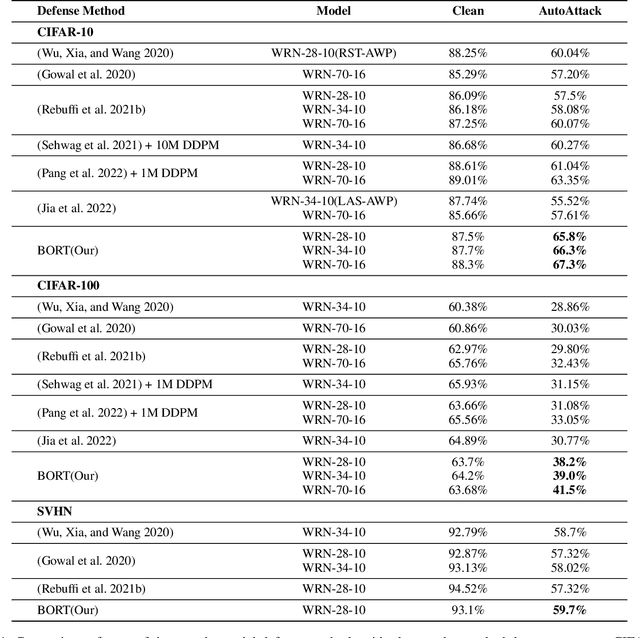
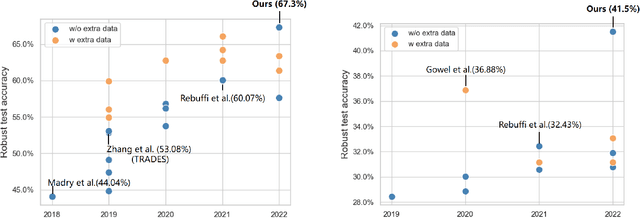
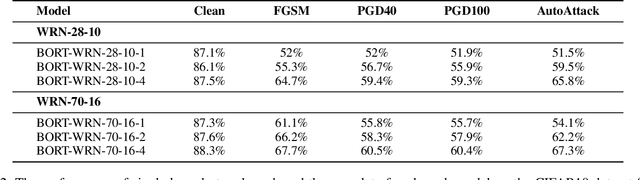
Deep neural networks (DNNs) are vulnerable to adversarial examples, in which DNNs are misled to false outputs due to inputs containing imperceptible perturbations. Adversarial training, a reliable and effective method of defense, may significantly reduce the vulnerability of neural networks and becomes the de facto standard for robust learning. While many recent works practice the data-centric philosophy, such as how to generate better adversarial examples or use generative models to produce additional training data, we look back to the models themselves and revisit the adversarial robustness from the perspective of deep feature distribution as an insightful complementarity. In this paper, we propose Branch Orthogonality adveRsarial Training (BORT) to obtain state-of-the-art performance with solely the original dataset for adversarial training. To practice our design idea of integrating multiple orthogonal solution spaces, we leverage a simple and straightforward multi-branch neural network that eclipses adversarial attacks with no increase in inference time. We heuristically propose a corresponding loss function, branch-orthogonal loss, to make each solution space of the multi-branch model orthogonal. We evaluate our approach on CIFAR-10, CIFAR-100, and SVHN against \ell_{\infty} norm-bounded perturbations of size \epsilon = 8/255, respectively. Exhaustive experiments are conducted to show that our method goes beyond all state-of-the-art methods without any tricks. Compared to all methods that do not use additional data for training, our models achieve 67.3% and 41.5% robust accuracy on CIFAR-10 and CIFAR-100 (improving upon the state-of-the-art by +7.23% and +9.07%). We also outperform methods using a training set with a far larger scale than ours. All our models and codes are available online at https://github.com/huangd1999/BORT.