 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Retrieving Interaction Spaces for Agentic Search
Jun 05, 2026Retrieval for search agents is still inherited from non-agentic information retrieval: a retriever ranks the corpus and the agent reads a small set of returned documents. Recent direct corpus interaction (DCI) work shows that agents can instead interact with the raw corpus through shell tools such as grep and file reads. But unbounded interaction does not scale: every broad shell command is a scan over the whole corpus, and latency degrades sharply as the corpus grows. We argue that the role of retrieval for agentic search is not just to select documents that fit in the LLM context window, but to construct an interaction space: a bounded subset of the corpus the agent can explore with associated tools. Two design consequences follow. The space needs a boundary supplied by retrieval, and the objects within it should be processed for interaction. As a proof of concept, we propose RISE (Retrieving Interaction SpacE): we use BM25 to construct the interaction space; meanwhile, its documents are processed during indexing for shell-style navigation. On BrowseComp-Plus, RISE matches the pure-shell DCI baseline at 78% accuracy with gpt-5.4-mini at roughly one quarter of the per-query cost. At 1M documents, RISE-BM25 reaches 81% on gpt-5.4-mini, whereas DCI on gpt-5.4-nano degrades to 60% with 33 of 100 wall-clock failures.
ORBIT: Scalable and Verifiable Data Generation for Search Agents on a Tight Budget
Apr 02, 2026Search agents, which integrate language models (LMs) with web search, are becoming crucial for answering complex user queries. Constructing training datasets for deep research tasks, involving multi-step retrieval and reasoning, remains challenging due to expensive human annotation, or cumbersome prerequisites. In this work, we introduce ORBIT, a training dataset with 20K reasoning-intensive queries with short verifiable answers, generated using a frugal framework without relying on paid API services. The modular framework relies on four stages: seed creation, question-answer pair generation, and two stages of verification: self and external. ORBIT spans 15 domains and each training pair requires 4-5 reasoning steps, with external search verification required from the complete web. We train Qwen3-4B as the base model on ORBIT using GRPO and evaluate it on Wikipedia question answering tasks. Extensive experiment results demonstrate that ORBIT-4B achieves strong performance among sub-4B LLMs as search agents, proving the utility of synthetic datasets. Our framework, code and datasets are open-sourced and available publicly.
AgentIR: Reasoning-Aware Retrieval for Deep Research Agents
Mar 05, 2026Deep Research agents are rapidly emerging as primary consumers of modern retrieval systems. Unlike human users who issue and refine queries without documenting their intermediate thought processes, Deep Research agents generate explicit natural language reasoning before each search call, revealing rich intent and contextual information that existing retrievers entirely ignore. To exploit this overlooked signal, we introduce: (1) Reasoning-Aware Retrieval, a retrieval paradigm that jointly embeds the agent's reasoning trace alongside its query; and (2) DR-Synth, a data synthesis method that generates Deep Research retriever training data from standard QA datasets. We demonstrate that both components are independently effective, and their combination yields a trained embedding model, AgentIR-4B, with substantial gains. On the challenging BrowseComp-Plus benchmark, AgentIR-4B achieves 68\% accuracy with the open-weight agent Tongyi-DeepResearch, compared to 50\% with conventional embedding models twice its size, and 37\% with BM25. Code and data are available at: https://texttron.github.io/AgentIR/.
LACONIC: Dense-Level Effectiveness for Scalable Sparse Retrieval via a Two-Phase Training Curriculum
Jan 04, 2026While dense retrieval models have become the standard for state-of-the-art information retrieval, their deployment is often constrained by high memory requirements and reliance on GPU accelerators for vector similarity search. Learned sparse retrieval offers a compelling alternative by enabling efficient search via inverted indices, yet it has historically received less attention than dense approaches. In this report, we introduce LACONIC, a family of learned sparse retrievers based on the Llama-3 architecture (1B, 3B, and 8B). We propose a streamlined two-phase training curriculum consisting of (1) weakly supervised pre-finetuning to adapt causal LLMs for bidirectional contextualization and (2) high-signal finetuning using curated hard negatives. Our results demonstrate that LACONIC effectively bridges the performance gap with dense models: the 8B variant achieves a state-of-the-art 60.2 nDCG on the MTEB Retrieval benchmark, ranking 15th on the leaderboard as of January 1, 2026, while utilizing 71\% less index memory than an equivalent dense model. By delivering high retrieval effectiveness on commodity CPU hardware with a fraction of the compute budget required by competing models, LACONIC provides a scalable and efficient solution for real-world search applications.
MAGMaR Shared Task System Description: Video Retrieval with OmniEmbed
Jun 11, 2025


Effective video retrieval remains challenging due to the complexity of integrating visual, auditory, and textual modalities. In this paper, we explore unified retrieval methods using OmniEmbed, a powerful multimodal embedding model from the Tevatron 2.0 toolkit, in the context of the MAGMaR shared task. Evaluated on the comprehensive MultiVENT 2.0 dataset, OmniEmbed generates unified embeddings for text, images, audio, and video, enabling robust multimodal retrieval. By finetuning OmniEmbed with the combined multimodal data--visual frames, audio tracks, and textual descriptions provided in MultiVENT 2.0, we achieve substantial improvements in complex, multilingual video retrieval tasks. Our submission achieved the highest score on the MAGMaR shared task leaderboard among public submissions as of May 20th, 2025, highlighting the practical effectiveness of our unified multimodal retrieval approach. Model checkpoint in this work is opensourced.
Fixing Data That Hurts Performance: Cascading LLMs to Relabel Hard Negatives for Robust Information Retrieval
May 22, 2025



Training robust retrieval and reranker models typically relies on large-scale retrieval datasets; for example, the BGE collection contains 1.6 million query-passage pairs sourced from various data sources. However, we find that certain datasets can negatively impact model effectiveness -- pruning 8 out of 15 datasets from the BGE collection reduces the training set size by 2.35$\times$ and increases nDCG@10 on BEIR by 1.0 point. This motivates a deeper examination of training data quality, with a particular focus on "false negatives", where relevant passages are incorrectly labeled as irrelevant. We propose a simple, cost-effective approach using cascading LLM prompts to identify and relabel hard negatives. Experimental results show that relabeling false negatives with true positives improves both E5 (base) and Qwen2.5-7B retrieval models by 0.7-1.4 nDCG@10 on BEIR and by 1.7-1.8 nDCG@10 on zero-shot AIR-Bench evaluation. Similar gains are observed for rerankers fine-tuned on the relabeled data, such as Qwen2.5-3B on BEIR. The reliability of the cascading design is further supported by human annotation results, where we find judgment by GPT-4o shows much higher agreement with humans than GPT-4o-mini.
General-Reasoner: Advancing LLM Reasoning Across All Domains
May 21, 2025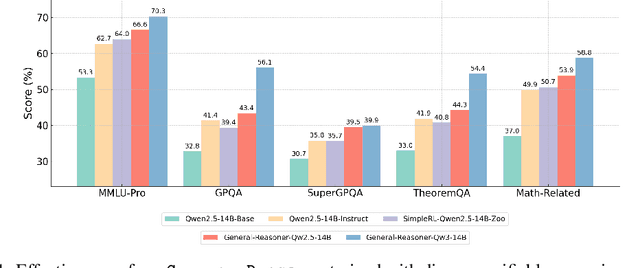
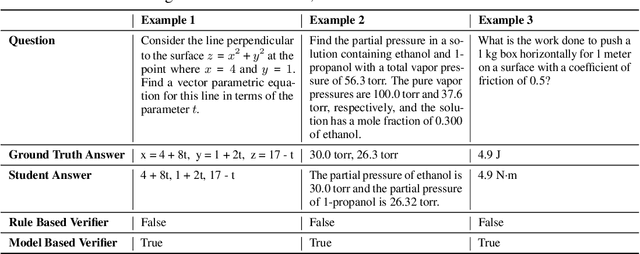

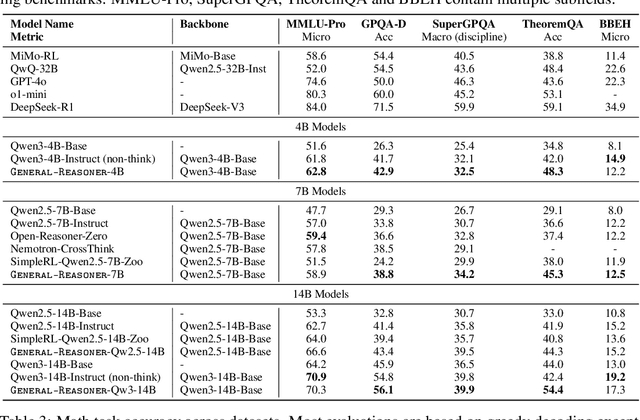
Reinforcement learning (RL) has recently demonstrated strong potential in enhancing the reasoning capabilities of large language models (LLMs). Particularly, the "Zero" reinforcement learning introduced by Deepseek-R1-Zero, enables direct RL training of base LLMs without relying on an intermediate supervised fine-tuning stage. Despite these advancements, current works for LLM reasoning mainly focus on mathematical and coding domains, largely due to data abundance and the ease of answer verification. This limits the applicability and generalization of such models to broader domains, where questions often have diverse answer representations, and data is more scarce. In this paper, we propose General-Reasoner, a novel training paradigm designed to enhance LLM reasoning capabilities across diverse domains. Our key contributions include: (1) constructing a large-scale, high-quality dataset of questions with verifiable answers curated by web crawling, covering a wide range of disciplines; and (2) developing a generative model-based answer verifier, which replaces traditional rule-based verification with the capability of chain-of-thought and context-awareness. We train a series of models and evaluate them on a wide range of datasets covering wide domains like physics, chemistry, finance, electronics etc. Our comprehensive evaluation across these 12 benchmarks (e.g. MMLU-Pro, GPQA, SuperGPQA, TheoremQA, BBEH and MATH AMC) demonstrates that General-Reasoner outperforms existing baseline methods, achieving robust and generalizable reasoning performance while maintaining superior effectiveness in mathematical reasoning tasks.
Tevatron 2.0: Unified Document Retrieval Toolkit across Scale, Language, and Modality
May 05, 2025



Recent advancements in large language models (LLMs) have driven interest in billion-scale retrieval models with strong generalization across retrieval tasks and languages. Additionally, progress in large vision-language models has created new opportunities for multimodal retrieval. In response, we have updated the Tevatron toolkit, introducing a unified pipeline that enables researchers to explore retriever models at different scales, across multiple languages, and with various modalities. This demo paper highlights the toolkit's key features, bridging academia and industry by supporting efficient training, inference, and evaluation of neural retrievers. We showcase a unified dense retriever achieving strong multilingual and multimodal effectiveness, and conduct a cross-modality zero-shot study to demonstrate its research potential. Alongside, we release OmniEmbed, to the best of our knowledge, the first embedding model that unifies text, image document, video, and audio retrieval, serving as a baseline for future research.
ScholarCopilot: Training Large Language Models for Academic Writing with Accurate Citations
Apr 03, 2025Academic writing requires both coherent text generation and precise citation of relevant literature. Although recent Retrieval-Augmented Generation (RAG) systems have significantly improved factual accuracy in general-purpose text generation, their ability to support professional academic writing remains limited. In this work, we introduce ScholarCopilot, a unified framework designed to enhance existing large language models for generating professional academic articles with accurate and contextually relevant citations. ScholarCopilot dynamically determines when to retrieve scholarly references by generating a retrieval token [RET], which is then used to query a citation database. The retrieved references are fed into the model to augment the generation process. We jointly optimize both the generation and citation tasks within a single framework to improve efficiency. Our model is built upon Qwen-2.5-7B and trained on 500K papers from arXiv. It achieves a top-1 retrieval accuracy of 40.1% on our evaluation dataset, outperforming baselines such as E5-Mistral-7B-Instruct (15.0%) and BM25 (9.8%). On a dataset of 1,000 academic writing samples, ScholarCopilot scores 16.2/25 in generation quality -- measured across relevance, coherence, academic rigor, completeness, and innovation -- significantly surpassing all existing models, including much larger ones like the Retrieval-Augmented Qwen2.5-72B-Instruct. Human studies further demonstrate that ScholarCopilot, despite being a 7B model, significantly outperforms ChatGPT, achieving 100% preference in citation quality and over 70% in overall usefulness.
Rank-R1: Enhancing Reasoning in LLM-based Document Rerankers via Reinforcement Learning
Mar 08, 2025



In this paper, we introduce Rank-R1, a novel LLM-based reranker that performs reasoning over both the user query and candidate documents before performing the ranking task. Existing document reranking methods based on large language models (LLMs) typically rely on prompting or fine-tuning LLMs to order or label candidate documents according to their relevance to a query. For Rank-R1, we use a reinforcement learning algorithm along with only a small set of relevance labels (without any reasoning supervision) to enhance the reasoning ability of LLM-based rerankers. Our hypothesis is that adding reasoning capabilities to the rerankers can improve their relevance assessement and ranking capabilities. Our experiments on the TREC DL and BRIGHT datasets show that Rank-R1 is highly effective, especially for complex queries. In particular, we find that Rank-R1 achieves effectiveness on in-domain datasets at par with that of supervised fine-tuning methods, but utilizing only 18\% of the training data used by the fine-tuning methods. We also find that the model largely outperforms zero-shot and supervised fine-tuning when applied to out-of-domain datasets featuring complex queries, especially when a 14B-size model is used. Finally, we qualitatively observe that Rank-R1's reasoning process improves the explainability of the ranking results, opening new opportunities for search engine results presentation and fruition.