 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniMMI: A Comprehensive Multi-modal Interaction Benchmark in Streaming Video Contexts
Mar 29, 2025The rapid advancement of multi-modal language models (MLLMs) like GPT-4o has propelled the development of Omni language models, designed to process and proactively respond to continuous streams of multi-modal data. Despite their potential, evaluating their real-world interactive capabilities in streaming video contexts remains a formidable challenge. In this work, we introduce OmniMMI, a comprehensive multi-modal interaction benchmark tailored for OmniLLMs in streaming video contexts. OmniMMI encompasses over 1,121 videos and 2,290 questions, addressing two critical yet underexplored challenges in existing video benchmarks: streaming video understanding and proactive reasoning, across six distinct subtasks. Moreover, we propose a novel framework, Multi-modal Multiplexing Modeling (M4), designed to enable an inference-efficient streaming model that can see, listen while generating.
QualiSpeech: A Speech Quality Assessment Dataset with Natural Language Reasoning and Descriptions
Mar 26, 2025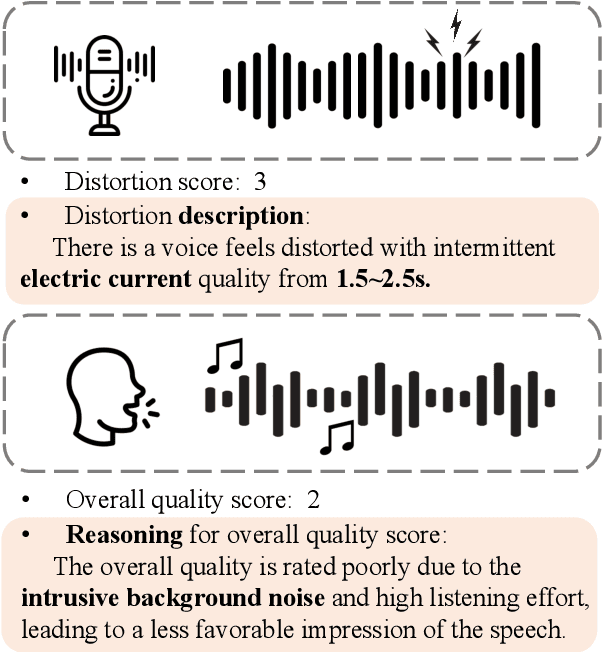
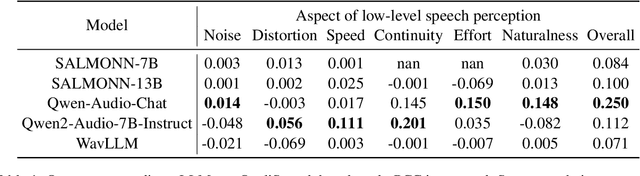
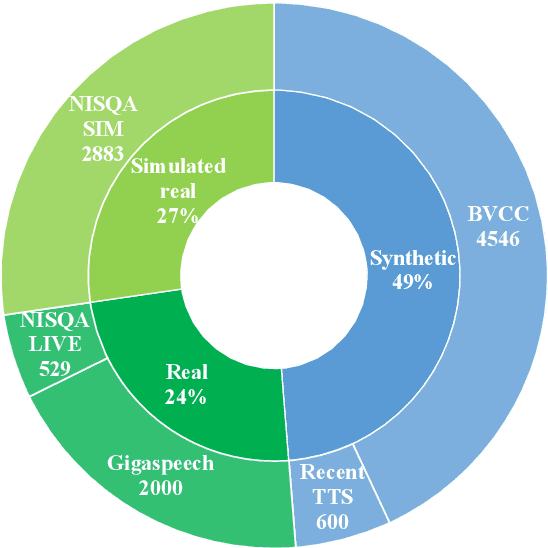
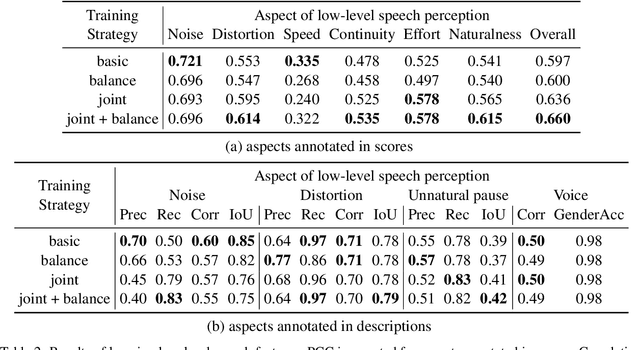
This paper explores a novel perspective to speech quality assessment by leveraging natural language descriptions, offering richer, more nuanced insights than traditional numerical scoring methods. Natural language feedback provides instructive recommendations and detailed evaluations, yet existing datasets lack the comprehensive annotations needed for this approach. To bridge this gap, we introduce QualiSpeech, a comprehensive low-level speech quality assessment dataset encompassing 11 key aspects and detailed natural language comments that include reasoning and contextual insights. Additionally, we propose the QualiSpeech Benchmark to evaluate the low-level speech understanding capabilities of auditory large language models (LLMs). Experimental results demonstrate that finetuned auditory LLMs can reliably generate detailed descriptions of noise and distortion, effectively identifying their types and temporal characteristics. The results further highlight the potential for incorporating reasoning to enhance the accuracy and reliability of quality assessments. The dataset will be released at https://huggingface.co/datasets/tsinghua-ee/QualiSpeech.
Solla: Towards a Speech-Oriented LLM That Hears Acoustic Context
Mar 19, 2025



Large Language Models (LLMs) have recently shown remarkable ability to process not only text but also multimodal inputs such as speech and audio. However, most existing models primarily focus on analyzing input signals using text instructions, overlooking scenarios in which speech instructions and audio are mixed and serve as inputs to the model. To address these challenges, we introduce Solla, a novel framework designed to understand speech-based questions and hear the acoustic context concurrently. Solla incorporates an audio tagging module to effectively identify and represent audio events, as well as an ASR-assisted prediction method to improve comprehension of spoken content. To rigorously evaluate Solla and other publicly available models, we propose a new benchmark dataset called SA-Eval, which includes three tasks: audio event classification, audio captioning, and audio question answering. SA-Eval has diverse speech instruction with various speaking styles, encompassing two difficulty levels, easy and hard, to capture the range of real-world acoustic conditions. Experimental results show that Solla performs on par with or outperforms baseline models on both the easy and hard test sets, underscoring its effectiveness in jointly understanding speech and audio.
A Parallel Hybrid Action Space Reinforcement Learning Model for Real-world Adaptive Traffic Signal Control
Mar 18, 2025Adaptive traffic signal control (ATSC) can effectively reduce vehicle travel times by dynamically adjusting signal timings but poses a critical challenge in real-world scenarios due to the complexity of real-time decision-making in dynamic and uncertain traffic conditions. The burgeoning field of intelligent transportation systems, bolstered by artificial intelligence techniques and extensive data availability, offers new prospects for the implementation of ATSC. In this study, we introduce a parallel hybrid action space reinforcement learning model (PH-DDPG) that optimizes traffic signal phase and duration of traffic signals simultaneously, eliminating the need for sequential decision-making seen in traditional two-stage models. Our model features a task-specific parallel hybrid action space tailored for adaptive traffic control, which directly outputs discrete phase selections and their associated continuous duration parameters concurrently, thereby inherently addressing dynamic traffic adaptation through unified parametric optimization. %Our model features a unique parallel hybrid action space that allows for the simultaneous output of each action and its optimal parameters, streamlining the decision-making process. Furthermore, to ascertain the robustness and effectiveness of this approach, we executed ablation studies focusing on the utilization of a random action parameter mask within the critic network, which decouples the parameter space for individual actions, facilitating the use of preferable parameters for each action. The results from these studies confirm the efficacy of this method, distinctly enhancing real-world applicability
PBR3DGen: A VLM-guided Mesh Generation with High-quality PBR Texture
Mar 14, 2025Generating high-quality physically based rendering (PBR) materials is important to achieve realistic rendering in the downstream tasks, yet it remains challenging due to the intertwined effects of materials and lighting. While existing methods have made breakthroughs by incorporating material decomposition in the 3D generation pipeline, they tend to bake highlights into albedo and ignore spatially varying properties of metallicity and roughness. In this work, we present PBR3DGen, a two-stage mesh generation method with high-quality PBR materials that integrates the novel multi-view PBR material estimation model and a 3D PBR mesh reconstruction model. Specifically, PBR3DGen leverages vision language models (VLM) to guide multi-view diffusion, precisely capturing the spatial distribution and inherent attributes of reflective-metalness material. Additionally, we incorporate view-dependent illumination-aware conditions as pixel-aware priors to enhance spatially varying material properties. Furthermore, our reconstruction model reconstructs high-quality mesh with PBR materials. Experimental results demonstrate that PBR3DGen significantly outperforms existing methods, achieving new state-of-the-art results for PBR estimation and mesh generation. More results and visualization can be found on our project page: https://pbr3dgen1218.github.io/.
NsBM-GAT: A Non-stationary Block Maximum and Graph Attention Framework for General Traffic Crash Risk Prediction
Mar 06, 2025



Accurate prediction of traffic crash risks for individual vehicles is essential for enhancing vehicle safety. While significant attention has been given to traffic crash risk prediction, existing studies face two main challenges: First, due to the scarcity of individual vehicle data before crashes, most models rely on hypothetical scenarios deemed dangerous by researchers. This raises doubts about their applicability to actual pre-crash conditions. Second, some crash risk prediction frameworks were learned from dashcam videos. Although such videos capture the pre-crash behavior of individual vehicles, they often lack critical information about the movements of surrounding vehicles. However, the interaction between a vehicle and its surrounding vehicles is highly influential in crash occurrences. To overcome these challenges, we propose a novel non-stationary extreme value theory (EVT), where the covariate function is optimized in a nonlinear fashion using a graph attention network. The EVT component incorporates the stochastic nature of crashes through probability distribution, which enhances model interpretability. Notably, the nonlinear covariate function enables the model to capture the interactive behavior between the target vehicle and its multiple surrounding vehicles, facilitating crash risk prediction across different driving tasks. We train and test our model using 100 sets of vehicle trajectory data before real crashes, collected via drones over three years from merging and weaving segments. We demonstrate that our model successfully learns micro-level precursors of crashes and fits a more accurate distribution with the aid of the nonlinear covariate function. Our experiments on the testing dataset show that the proposed model outperforms existing models by providing more accurate predictions for both rear-end and sideswipe crashes simultaneously.
From Hours to Minutes: Lossless Acceleration of Ultra Long Sequence Generation up to 100K Tokens
Feb 26, 2025Generating ultra-long sequences with large language models (LLMs) has become increasingly crucial but remains a highly time-intensive task, particularly for sequences up to 100K tokens. While traditional speculative decoding methods exist, simply extending their generation limits fails to accelerate the process and can be detrimental. Through an in-depth analysis, we identify three major challenges hindering efficient generation: frequent model reloading, dynamic key-value (KV) management and repetitive generation. To address these issues, we introduce TOKENSWIFT, a novel framework designed to substantially accelerate the generation process of ultra-long sequences while maintaining the target model's inherent quality. Experimental results demonstrate that TOKENSWIFT achieves over 3 times speedup across models of varying scales (1.5B, 7B, 8B, 14B) and architectures (MHA, GQA). This acceleration translates to hours of time savings for ultra-long sequence generation, establishing TOKENSWIFT as a scalable and effective solution at unprecedented lengths. Code can be found at https://github.com/bigai-nlco/TokenSwift.
The establishment of static digital humans and the integration with spinal models
Feb 11, 2025Adolescent idiopathic scoliosis (AIS), a prevalent spinal deformity, significantly affects individuals' health and quality of life. Conventional imaging techniques, such as X - rays, computed tomography (CT), and magnetic resonance imaging (MRI), offer static views of the spine. However, they are restricted in capturing the dynamic changes of the spine and its interactions with overall body motion. Therefore, developing new techniques to address these limitations has become extremely important. Dynamic digital human modeling represents a major breakthrough in digital medicine. It enables a three - dimensional (3D) view of the spine as it changes during daily activities, assisting clinicians in detecting deformities that might be missed in static imaging. Although dynamic modeling holds great potential, constructing an accurate static digital human model is a crucial initial step for high - precision simulations. In this study, our focus is on constructing an accurate static digital human model integrating the spine, which is vital for subsequent dynamic digital human research on AIS. First, we generate human point - cloud data by combining the 3D Gaussian method with the Skinned Multi - Person Linear (SMPL) model from the patient's multi - view images. Then, we fit a standard skeletal model to the generated human model. Next, we align the real spine model reconstructed from CT images with the standard skeletal model. We validated the resulting personalized spine model using X - ray data from six AIS patients, with Cobb angles (used to measure the severity of scoliosis) as evaluation metrics. The results indicate that the model's error was within 1 degree of the actual measurements. This study presents an important method for constructing digital humans.
DiTAR: Diffusion Transformer Autoregressive Modeling for Speech Generation
Feb 06, 2025



Several recent studies have attempted to autoregressively generate continuous speech representations without discrete speech tokens by combining diffusion and autoregressive models, yet they often face challenges with excessive computational loads or suboptimal outcomes. In this work, we propose Diffusion Transformer Autoregressive Modeling (DiTAR), a patch-based autoregressive framework combining a language model with a diffusion transformer. This approach significantly enhances the efficacy of autoregressive models for continuous tokens and reduces computational demands. DiTAR utilizes a divide-and-conquer strategy for patch generation, where the language model processes aggregated patch embeddings and the diffusion transformer subsequently generates the next patch based on the output of the language model. For inference, we propose defining temperature as the time point of introducing noise during the reverse diffusion ODE to balance diversity and determinism. We also show in the extensive scaling analysis that DiTAR has superb scalability. In zero-shot speech generation, DiTAR achieves state-of-the-art performance in robustness, speaker similarity, and naturalness.
Nautilus: Locality-aware Autoencoder for Scalable Mesh Generation
Jan 27, 2025



Triangle meshes are fundamental to 3D applications, enabling efficient modification and rasterization while maintaining compatibility with standard rendering pipelines. However, current automatic mesh generation methods typically rely on intermediate representations that lack the continuous surface quality inherent to meshes. Converting these representations into meshes produces dense, suboptimal outputs. Although recent autoregressive approaches demonstrate promise in directly modeling mesh vertices and faces, they are constrained by the limitation in face count, scalability, and structural fidelity. To address these challenges, we propose Nautilus, a locality-aware autoencoder for artist-like mesh generation that leverages the local properties of manifold meshes to achieve structural fidelity and efficient representation. Our approach introduces a novel tokenization algorithm that preserves face proximity relationships and compresses sequence length through locally shared vertices and edges, enabling the generation of meshes with an unprecedented scale of up to 5,000 faces. Furthermore, we develop a Dual-stream Point Conditioner that provides multi-scale geometric guidance, ensuring global consistency and local structural fidelity by capturing fine-grained geometric features. Extensive experiments demonstrate that Nautilus significantly outperforms state-of-the-art methods in both fidelity and scalability. The project page will be released to https://nautilusmeshgen.github.io.