 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Private is Your Attention? Bridging Privacy with In-Context Learning
Apr 22, 2025



In-context learning (ICL)-the ability of transformer-based models to perform new tasks from examples provided at inference time-has emerged as a hallmark of modern language models. While recent works have investigated the mechanisms underlying ICL, its feasibility under formal privacy constraints remains largely unexplored. In this paper, we propose a differentially private pretraining algorithm for linear attention heads and present the first theoretical analysis of the privacy-accuracy trade-off for ICL in linear regression. Our results characterize the fundamental tension between optimization and privacy-induced noise, formally capturing behaviors observed in private training via iterative methods. Additionally, we show that our method is robust to adversarial perturbations of training prompts, unlike standard ridge regression. All theoretical findings are supported by extensive simulations across diverse settings.
DiTAR: Diffusion Transformer Autoregressive Modeling for Speech Generation
Feb 06, 2025



Several recent studies have attempted to autoregressively generate continuous speech representations without discrete speech tokens by combining diffusion and autoregressive models, yet they often face challenges with excessive computational loads or suboptimal outcomes. In this work, we propose Diffusion Transformer Autoregressive Modeling (DiTAR), a patch-based autoregressive framework combining a language model with a diffusion transformer. This approach significantly enhances the efficacy of autoregressive models for continuous tokens and reduces computational demands. DiTAR utilizes a divide-and-conquer strategy for patch generation, where the language model processes aggregated patch embeddings and the diffusion transformer subsequently generates the next patch based on the output of the language model. For inference, we propose defining temperature as the time point of introducing noise during the reverse diffusion ODE to balance diversity and determinism. We also show in the extensive scaling analysis that DiTAR has superb scalability. In zero-shot speech generation, DiTAR achieves state-of-the-art performance in robustness, speaker similarity, and naturalness.
Seed-TTS: A Family of High-Quality Versatile Speech Generation Models
Jun 04, 2024



We introduce Seed-TTS, a family of large-scale autoregressive text-to-speech (TTS) models capable of generating speech that is virtually indistinguishable from human speech. Seed-TTS serves as a foundation model for speech generation and excels in speech in-context learning, achieving performance in speaker similarity and naturalness that matches ground truth human speech in both objective and subjective evaluations. With fine-tuning, we achieve even higher subjective scores across these metrics. Seed-TTS offers superior controllability over various speech attributes such as emotion and is capable of generating highly expressive and diverse speech for speakers in the wild. Furthermore, we propose a self-distillation method for speech factorization, as well as a reinforcement learning approach to enhance model robustness, speaker similarity, and controllability. We additionally present a non-autoregressive (NAR) variant of the Seed-TTS model, named $\text{Seed-TTS}_\text{DiT}$, which utilizes a fully diffusion-based architecture. Unlike previous NAR-based TTS systems, $\text{Seed-TTS}_\text{DiT}$ does not depend on pre-estimated phoneme durations and performs speech generation through end-to-end processing. We demonstrate that this variant achieves comparable performance to the language model-based variant and showcase its effectiveness in speech editing. We encourage readers to listen to demos at \url{https://bytedancespeech.github.io/seedtts_tech_report}.
Image Recognition of Oil Leakage Area Based on Logical Semantic Discrimination
Nov 17, 2023



Implementing precise detection of oil leaks in peak load equipment through image analysis can significantly enhance inspection quality and ensure the system's safety and reliability. However, challenges such as varying shapes of oil-stained regions, background noise, and fluctuating lighting conditions complicate the detection process. To address this, the integration of logical rule-based discrimination into image recognition has been proposed. This approach involves recognizing the spatial relationships among objects to semantically segment images of oil spills using a Mask RCNN network. The process begins with histogram equalization to enhance the original image, followed by the use of Mask RCNN to identify the preliminary positions and outlines of oil tanks, the ground, and areas of potential oil contamination. Subsequent to this identification, the spatial relationships between these objects are analyzed. Logical rules are then applied to ascertain whether the suspected areas are indeed oil spills. This method's effectiveness has been confirmed by testing on images captured from peak power equipment in the field. The results indicate that this approach can adeptly tackle the challenges in identifying oil-contaminated areas, showing a substantial improvement in accuracy compared to existing methods.
High-resolution power equipment recognition based on improved self-attention
Nov 06, 2023
The current trend of automating inspections at substations has sparked a surge in interest in the field of transformer image recognition. However, due to restrictions in the number of parameters in existing models, high-resolution images can't be directly applied, leaving significant room for enhancing recognition accuracy. Addressing this challenge, the paper introduces a novel improvement on deep self-attention networks tailored for this issue. The proposed model comprises four key components: a foundational network, a region proposal network, a module for extracting and segmenting target areas, and a final prediction network. The innovative approach of this paper differentiates itself by decoupling the processes of part localization and recognition, initially using low-resolution images for localization followed by high-resolution images for recognition. Moreover, the deep self-attention network's prediction mechanism uniquely incorporates the semantic context of images, resulting in substantially improved recognition performance. Comparative experiments validate that this method outperforms the two other prevalent target recognition models, offering a groundbreaking perspective for automating electrical equipment inspections.
Automatic Parameterization for Aerodynamic Shape Optimization via Deep Geometric Learning
May 03, 2023



We propose two deep learning models that fully automate shape parameterization for aerodynamic shape optimization. Both models are optimized to parameterize via deep geometric learning to embed human prior knowledge into learned geometric patterns, eliminating the need for further handcrafting. The Latent Space Model (LSM) learns a low-dimensional latent representation of an object from a dataset of various geometries, while the Direct Mapping Model (DMM) builds parameterization on the fly using only one geometry of interest. We also devise a novel regularization loss that efficiently integrates volumetric mesh deformation into the parameterization model. The models directly manipulate the high-dimensional mesh data by moving vertices. LSM and DMM are fully differentiable, enabling gradient-based, end-to-end pipeline design and plug-and-play deployment of surrogate models or adjoint solvers. We perform shape optimization experiments on 2D airfoils and discuss the applicable scenarios for the two models.
Robust Outlier Rejection for 3D Registration with Variational Bayes
Apr 04, 2023



Learning-based outlier (mismatched correspondence) rejection for robust 3D registration generally formulates the outlier removal as an inlier/outlier classification problem. The core for this to be successful is to learn the discriminative inlier/outlier feature representations. In this paper, we develop a novel variational non-local network-based outlier rejection framework for robust alignment. By reformulating the non-local feature learning with variational Bayesian inference, the Bayesian-driven long-range dependencies can be modeled to aggregate discriminative geometric context information for inlier/outlier distinction. Specifically, to achieve such Bayesian-driven contextual dependencies, each query/key/value component in our non-local network predicts a prior feature distribution and a posterior one. Embedded with the inlier/outlier label, the posterior feature distribution is label-dependent and discriminative. Thus, pushing the prior to be close to the discriminative posterior in the training step enables the features sampled from this prior at test time to model high-quality long-range dependencies. Notably, to achieve effective posterior feature guidance, a specific probabilistic graphical model is designed over our non-local model, which lets us derive a variational low bound as our optimization objective for model training. Finally, we propose a voting-based inlier searching strategy to cluster the high-quality hypothetical inliers for transformation estimation. Extensive experiments on 3DMatch, 3DLoMatch, and KITTI datasets verify the effectiveness of our method.
IR2Net: Information Restriction and Information Recovery for Accurate Binary Neural Networks
Oct 06, 2022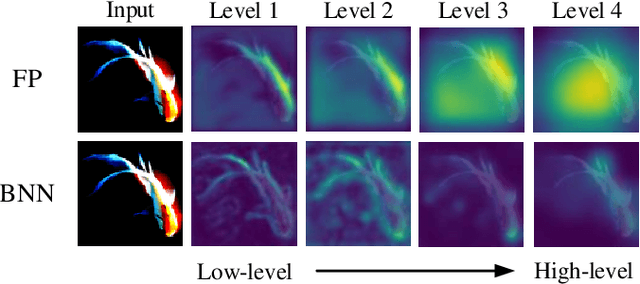
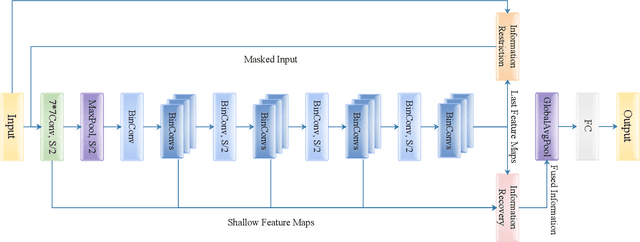
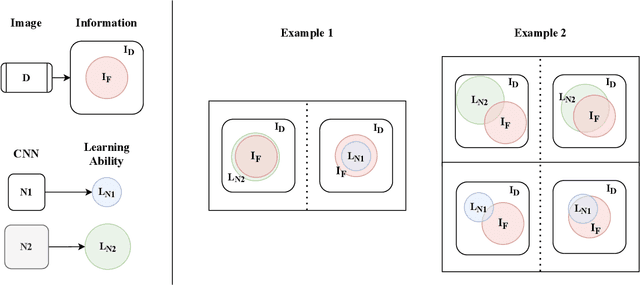
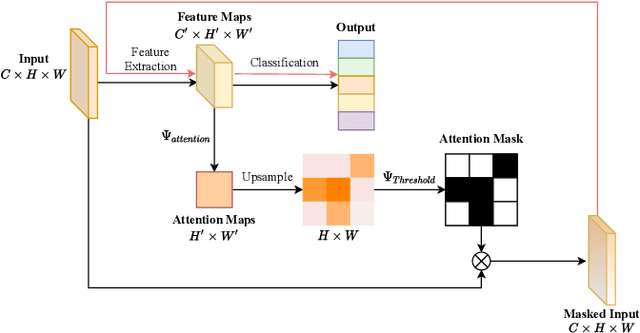
Weight and activation binarization can efficiently compress deep neural networks and accelerate model inference, but cause severe accuracy degradation. Existing optimization methods for binary neural networks (BNNs) focus on fitting full-precision networks to reduce quantization errors, and suffer from the trade-off between accuracy and computational complexity. In contrast, considering the limited learning ability and information loss caused by the limited representational capability of BNNs, we propose IR$^2$Net to stimulate the potential of BNNs and improve the network accuracy by restricting the input information and recovering the feature information, including: 1) information restriction: for a BNN, by evaluating the learning ability on the input information, discarding some of the information it cannot focus on, and limiting the amount of input information to match its learning ability; 2) information recovery: due to the information loss in forward propagation, the output feature information of the network is not enough to support accurate classification. By selecting some shallow feature maps with richer information, and fusing them with the final feature maps to recover the feature information. In addition, the computational cost is reduced by streamlining the information recovery method to strike a better trade-off between accuracy and efficiency. Experimental results demonstrate that our approach still achieves comparable accuracy even with $ \sim $10x floating-point operations (FLOPs) reduction for ResNet-18. The models and code are available at https://github.com/pingxue-hfut/IR2Net.
AIP: Adversarial Iterative Pruning Based on Knowledge Transfer for Convolutional Neural Networks
Aug 31, 2021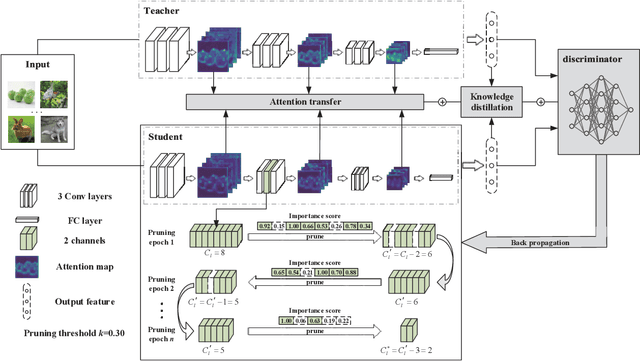
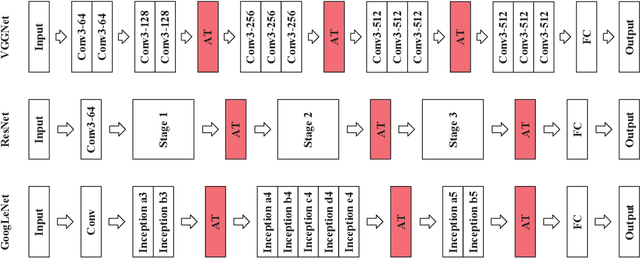
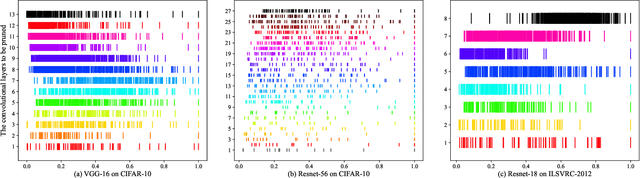
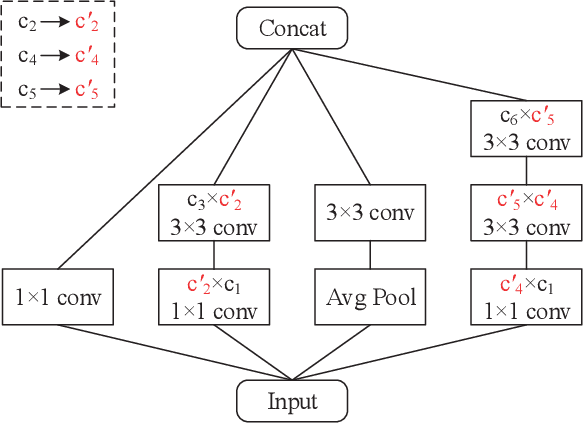
With the increase of structure complexity, convolutional neural networks (CNNs) take a fair amount of computation cost. Meanwhile, existing research reveals the salient parameter redundancy in CNNs. The current pruning methods can compress CNNs with little performance drop, but when the pruning ratio increases, the accuracy loss is more serious. Moreover, some iterative pruning methods are difficult to accurately identify and delete unimportant parameters due to the accuracy drop during pruning. We propose a novel adversarial iterative pruning method (AIP) for CNNs based on knowledge transfer. The original network is regarded as the teacher while the compressed network is the student. We apply attention maps and output features to transfer information from the teacher to the student. Then, a shallow fully-connected network is designed as the discriminator to allow the output of two networks to play an adversarial game, thereby it can quickly recover the pruned accuracy among pruning intervals. Finally, an iterative pruning scheme based on the importance of channels is proposed. We conduct extensive experiments on the image classification tasks CIFAR-10, CIFAR-100, and ILSVRC-2012 to verify our pruning method can achieve efficient compression for CNNs even without accuracy loss. On the ILSVRC-2012, when removing 36.78% parameters and 45.55% floating-point operations (FLOPs) of ResNet-18, the Top-1 accuracy drop are only 0.66%. Our method is superior to some state-of-the-art pruning schemes in terms of compressing rate and accuracy. Moreover, we further demonstrate that AIP has good generalization on the object detection task PASCAL VOC.
Few-Shot Model Adaptation for Customized Facial Landmark Detection, Segmentation, Stylization and Shadow Removal
Apr 19, 2021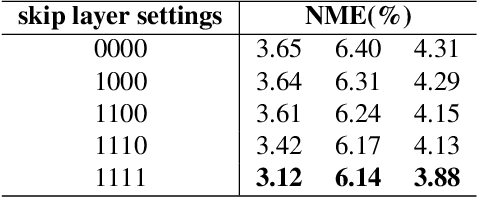
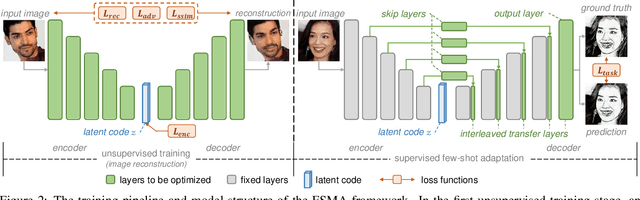
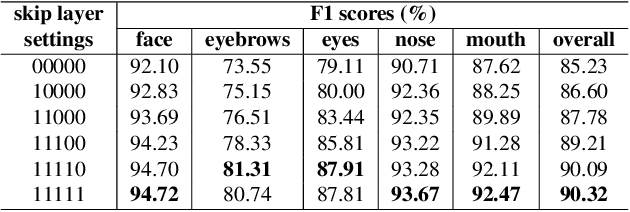
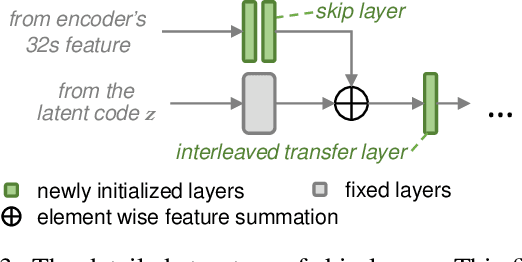
Despite excellent progress has been made, the performance of deep learning based algorithms still heavily rely on specific datasets, which are difficult to extend due to labor-intensive labeling. Moreover, because of the advancement of new applications, initial definition of data annotations might not always meet the requirements of new functionalities. Thus, there is always a great demand in customized data annotations. To address the above issues, we propose the Few-Shot Model Adaptation (FSMA) framework and demonstrate its potential on several important tasks on Faces. The FSMA first acquires robust facial image embeddings by training an adversarial auto-encoder using large-scale unlabeled data. Then the model is equipped with feature adaptation and fusion layers, and adapts to the target task efficiently using a minimal amount of annotated images. The FSMA framework is prominent in its versatility across a wide range of facial image applications. The FSMA achieves state-of-the-art few-shot landmark detection performance and it offers satisfying solutions for few-shot face segmentation, stylization and facial shadow removal tasks for the first time.