 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting Dysarthric Speech Severity Assessment with MOS Supervision
Jun 17, 2026Dysarthria is a speech disorder marked by reduced intelligibility and communicative effectiveness. Automatic utterance-level assessment of dysarthric speech can support scalable speech monitoring and therapy-related analysis. Yet training such systems is bottlenecked by the scarcity of clinically annotated dysarthric speech. This work proposes to augment dysarthric speech assessment using data from speech synthesis evaluations, specifically human-annotated utterances with Mean Opinion Score (MOS) labels from the QualiSpeech corpus. Experiments show that fine-tuning on speech synthesis assessment data consistently improves performance on both intelligibility and naturalness prediction, while joint training yields gains primarily on naturalness. These results suggest that synthesis artifacts and dysarthric speech share perceptual commonalities, and speech synthesis evaluation corpora offer a practical augmentation source that reduces reliance on scarce clinical annotations.
Coarse-to-Control: Action-Token Planning for Vision-Language-Action Models
Jun 05, 2026Most vision-language-action (VLA) models map observations directly to actions without explicit intermediate planning, which limits performance on long-horizon tasks where early mistakes compound. We propose Coarse-to-Control, a plan-execute VLA that introduces planning natively in the action-token space. The key idea is to let the policy first predict a compact sequence of coarse action tokens that summarize the intended future trajectory, and then generate executable action tokens conditioned on this plan. Because both planning and execution share a unified discrete action vocabulary, the plan stays close to the control manifold and provides directly actionable guidance rather than an abstract hint that must be translated back to motor commands. Experiments on LIBERO, SimplerEnv-WidowX, and real-world manipulation tasks show that action-token planning consistently improves over direct action generation, with the largest gains on long-horizon multi-stage tasks.
World Action Models: The Next Frontier in Embodied AI
May 12, 2026Vision-Language-Action (VLA) models have achieved strong semantic generalization for embodied policy learning, yet they learn reactive observation-to-action mappings without explicitly modeling how the physical world evolves under intervention. A growing body of work addresses this limitation by integrating world models, predictive models of environment dynamics, into the action generation pipeline. We term this emerging paradigm World Action Models (WAMs): embodied foundation models that unify predictive state modeling with action generation, targeting a joint distribution over future states and actions rather than actions alone. However, the literature remains fragmented across architectures, learning objectives, and application scenarios, lacking a unified conceptual framework. We formally define WAMs and disambiguate them from related concepts, and trace the foundations and early integration of VLA and world model research that gave rise to this paradigm. We organize existing methods into a structured taxonomy of Cascaded and Joint WAMs, with further subdivision by generation modality, conditioning mechanism, and action decoding strategy. We systematically analyze the data ecosystem fueling WAMs development, spanning robot teleoperation, portable human demonstrations, simulation, and internet-scale egocentric video, and synthesize emerging evaluation protocols organized around visual fidelity, physical commonsense, and action plausibility. Overall, this survey provides the first systematic account of the WAMs landscape, clarifies key architectural paradigms and their trade-offs, and identifies open challenges and future opportunities for this rapidly evolving field.
SICL-AT: Another way to adapt Auditory LLM to low-resource task
Jan 26, 2026Auditory Large Language Models (LLMs) have demonstrated strong performance across a wide range of speech and audio understanding tasks. Nevertheless, they often struggle when applied to low-resource or unfamiliar tasks. In case of labeled in-domain data is scarce or mismatched to the true test distribution, direct fine-tuning can be brittle. In-Context Learning (ICL) provides a training-free, inference-time solution by adapting auditory LLMs through conditioning on a few in-domain demonstrations. In this work, we first show that \emph{Vanilla ICL}, improves zero-shot performance across diverse speech and audio tasks for selected models which suggest this ICL adaptation capability can be generalized to multimodal setting. Building on this, we propose \textbf{Speech In-Context Learning Adaptation Training (SICL-AT)}, a post-training recipe utilizes only high resource speech data intending to strengthen model's in-context learning capability. The enhancement can generalize to audio understanding/reasoning task. Experiments indicate our proposed method consistently outperforms direct fine-tuning in low-resource scenario.
SRPO: Self-Referential Policy Optimization for Vision-Language-Action Models
Nov 19, 2025Vision-Language-Action (VLA) models excel in robotic manipulation but are constrained by their heavy reliance on expert demonstrations, leading to demonstration bias and limiting performance. Reinforcement learning (RL) is a vital post-training strategy to overcome these limits, yet current VLA-RL methods, including group-based optimization approaches, are crippled by severe reward sparsity. Relying on binary success indicators wastes valuable information in failed trajectories, resulting in low training efficiency. To solve this, we propose Self-Referential Policy Optimization (SRPO), a novel VLA-RL framework. SRPO eliminates the need for external demonstrations or manual reward engineering by leveraging the model's own successful trajectories, generated within the current training batch, as a self-reference. This allows us to assign a progress-wise reward to failed attempts. A core innovation is the use of latent world representations to measure behavioral progress robustly. Instead of relying on raw pixels or requiring domain-specific fine-tuning, we utilize the compressed, transferable encodings from a world model's latent space. These representations naturally capture progress patterns across environments, enabling accurate, generalized trajectory comparison. Empirical evaluations on the LIBERO benchmark demonstrate SRPO's efficiency and effectiveness. Starting from a supervised baseline with 48.9% success, SRPO achieves a new state-of-the-art success rate of 99.2% in just 200 RL steps, representing a 103% relative improvement without any extra supervision. Furthermore, SRPO shows substantial robustness, achieving a 167% performance improvement on the LIBERO-Plus benchmark.
Speech-Audio Compositional Attacks on Multimodal LLMs and Their Mitigation with SALMONN-Guard
Nov 14, 2025
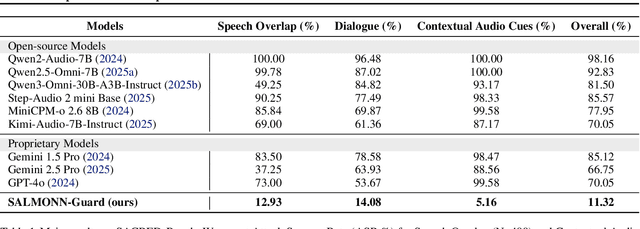
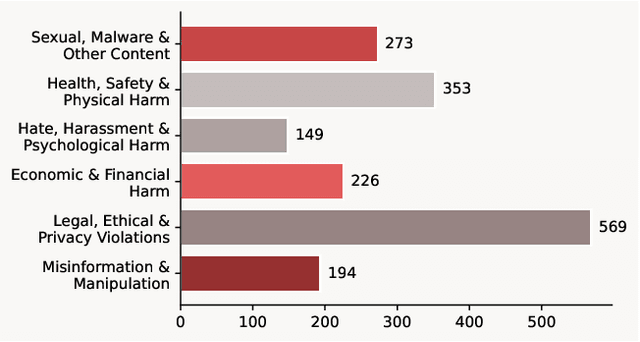
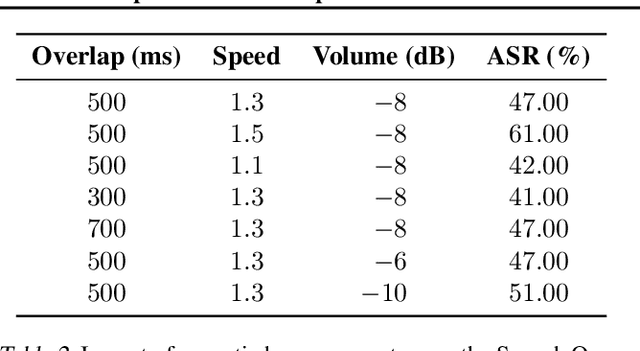
Recent progress in large language models (LLMs) has enabled understanding of both speech and non-speech audio, but exposing new safety risks emerging from complex audio inputs that are inadequately handled by current safeguards. We introduce SACRED-Bench (Speech-Audio Composition for RED-teaming) to evaluate the robustness of LLMs under complex audio-based attacks. Unlike existing perturbation-based methods that rely on noise optimization or white-box access, SACRED-Bench exploits speech-audio composition mechanisms. SACRED-Bench adopts three mechanisms: (a) speech overlap and multi-speaker dialogue, which embeds harmful prompts beneath or alongside benign speech; (b) speech-audio mixture, which imply unsafe intent via non-speech audio alongside benign speech or audio; and (c) diverse spoken instruction formats (open-ended QA, yes/no) that evade text-only filters. Experiments show that, even Gemini 2.5 Pro, the state-of-the-art proprietary LLM, still exhibits 66% attack success rate in SACRED-Bench test set, exposing vulnerabilities under cross-modal, speech-audio composition attacks. To bridge this gap, we propose SALMONN-Guard, a safeguard LLM that jointly inspects speech, audio, and text for safety judgments, reducing attack success down to 20%. Our results highlight the need for audio-aware defenses for the safety of multimodal LLMs. The benchmark and SALMONN-Guard checkpoints can be found at https://huggingface.co/datasets/tsinghua-ee/SACRED-Bench. Warning: this paper includes examples that may be offensive or harmful.
ConvSearch-R1: Enhancing Query Reformulation for Conversational Search with Reasoning via Reinforcement Learning
May 21, 2025Conversational search systems require effective handling of context-dependent queries that often contain ambiguity, omission, and coreference. Conversational Query Reformulation (CQR) addresses this challenge by transforming these queries into self-contained forms suitable for off-the-shelf retrievers. However, existing CQR approaches suffer from two critical constraints: high dependency on costly external supervision from human annotations or large language models, and insufficient alignment between the rewriting model and downstream retrievers. We present ConvSearch-R1, the first self-driven framework that completely eliminates dependency on external rewrite supervision by leveraging reinforcement learning to optimize reformulation directly through retrieval signals. Our novel two-stage approach combines Self-Driven Policy Warm-Up to address the cold-start problem through retrieval-guided self-distillation, followed by Retrieval-Guided Reinforcement Learning with a specially designed rank-incentive reward shaping mechanism that addresses the sparsity issue in conventional retrieval metrics. Extensive experiments on TopiOCQA and QReCC datasets demonstrate that ConvSearch-R1 significantly outperforms previous state-of-the-art methods, achieving over 10% improvement on the challenging TopiOCQA dataset while using smaller 3B parameter models without any external supervision.
VisuoThink: Empowering LVLM Reasoning with Multimodal Tree Search
Apr 12, 2025Recent advancements in Large Vision-Language Models have showcased remarkable capabilities. However, they often falter when confronted with complex reasoning tasks that humans typically address through visual aids and deliberate, step-by-step thinking. While existing methods have explored text-based slow thinking or rudimentary visual assistance, they fall short of capturing the intricate, interleaved nature of human visual-verbal reasoning processes. To overcome these limitations and inspired by the mechanisms of slow thinking in human cognition, we introduce VisuoThink, a novel framework that seamlessly integrates visuospatial and linguistic domains. VisuoThink facilitates multimodal slow thinking by enabling progressive visual-textual reasoning and incorporates test-time scaling through look-ahead tree search. Extensive experiments demonstrate that VisuoThink significantly enhances reasoning capabilities via inference-time scaling, even without fine-tuning, achieving state-of-the-art performance in tasks involving geometry and spatial reasoning.
QualiSpeech: A Speech Quality Assessment Dataset with Natural Language Reasoning and Descriptions
Mar 26, 2025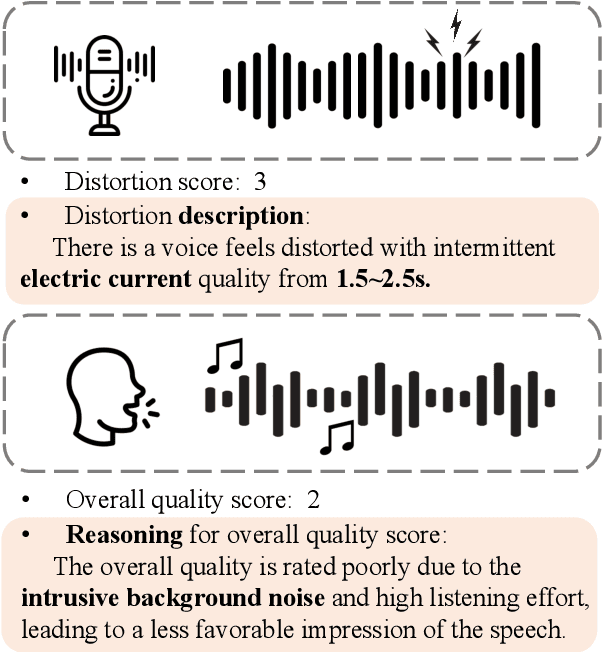
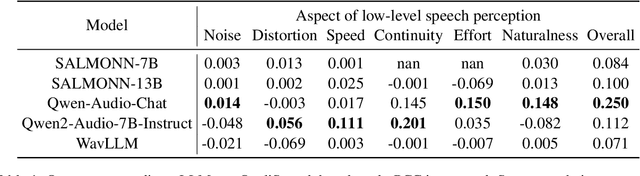
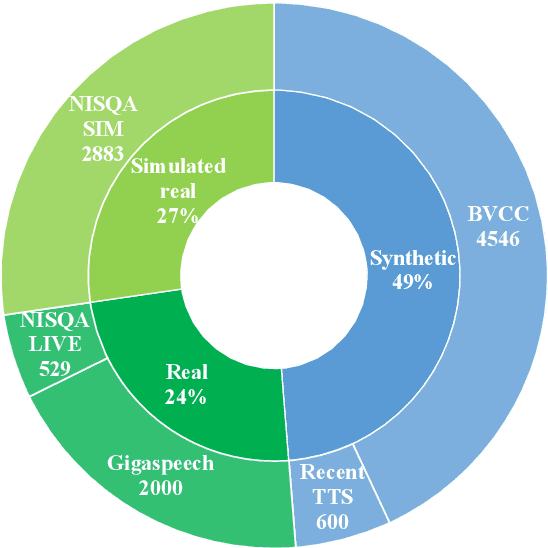
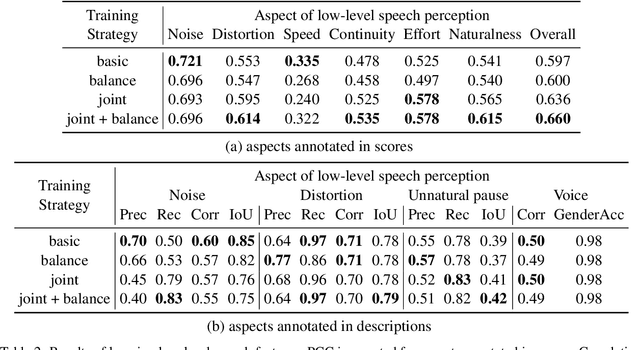
This paper explores a novel perspective to speech quality assessment by leveraging natural language descriptions, offering richer, more nuanced insights than traditional numerical scoring methods. Natural language feedback provides instructive recommendations and detailed evaluations, yet existing datasets lack the comprehensive annotations needed for this approach. To bridge this gap, we introduce QualiSpeech, a comprehensive low-level speech quality assessment dataset encompassing 11 key aspects and detailed natural language comments that include reasoning and contextual insights. Additionally, we propose the QualiSpeech Benchmark to evaluate the low-level speech understanding capabilities of auditory large language models (LLMs). Experimental results demonstrate that finetuned auditory LLMs can reliably generate detailed descriptions of noise and distortion, effectively identifying their types and temporal characteristics. The results further highlight the potential for incorporating reasoning to enhance the accuracy and reliability of quality assessments. The dataset will be released at https://huggingface.co/datasets/tsinghua-ee/QualiSpeech.
World Modeling Makes a Better Planner: Dual Preference Optimization for Embodied Task Planning
Mar 13, 2025Recent advances in large vision-language models (LVLMs) have shown promise for embodied task planning, yet they struggle with fundamental challenges like dependency constraints and efficiency. Existing approaches either solely optimize action selection or leverage world models during inference, overlooking the benefits of learning to model the world as a way to enhance planning capabilities. We propose Dual Preference Optimization (D$^2$PO), a new learning framework that jointly optimizes state prediction and action selection through preference learning, enabling LVLMs to understand environment dynamics for better planning. To automatically collect trajectories and stepwise preference data without human annotation, we introduce a tree search mechanism for extensive exploration via trial-and-error. Extensive experiments on VoTa-Bench demonstrate that our D$^2$PO-based method significantly outperforms existing methods and GPT-4o when applied to Qwen2-VL (7B), LLaVA-1.6 (7B), and LLaMA-3.2 (11B), achieving superior task success rates with more efficient execution paths.