 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePepSpecBench: A Unified Evaluation Benchmark for Peptide Tandem Mass Spectrometry Prediction
May 03, 2026Tandem mass spectrometry provides a high-throughput framework for identifying and quantifying proteins in complex biological samples. In computational proteomics, predicting peptide MS/MS spectra is a critical task, enabling downstream applications such as large-scale peptide identification and quantification. While deep learning architectures have substantially improved prediction accuracy, three evaluation challenges obscure the true progress of the field. First, inconsistent data preprocessing and incompatible model output spaces hinder fair model comparison. Second, flawed data splitting strategies can permit hidden sequence leakage and inflate reported performance. Third, existing evaluations typically lack comprehensive cross-species benchmarking and systematic assessment of model robustness to influential experimental conditions. To address these challenges, we propose PepSpecBench, a unified benchmark for peptide MS/MS spectrum prediction. PepSpecBench standardizes data preprocessing across complementary public datasets, enforces a strict backbone-disjoint splitting strategy to eliminate sequence leakage, and evaluates diverse architectures within a shared fragment-ion representation space. It further introduces a comprehensive multi-species evaluation suite and physically grounded metadata perturbation probes to assess model robustness and instrument awareness. We uncover previously unrecognized performance discrepancies and robustness limitations across six representative models, providing actionable insights for future model design, evaluation and practical deployment.
SSBI-Free Direct Detection via Phase Diverse of Residual Optical Carrier Enabled by Finite Extinction Ratio IQ Modulator for Datacenter Interconnections
Apr 08, 2026Cost-effective, low-complexity and spectrally efficient interconnection can offer fundamental guiding law for future datacenter. In this work, we demonstrate a cost-efficient SSBI-free direct detection for datacenter interconnection, leveraging the phase diversity of residual optical carrier caused by finite-extinction ratio (ER) IQ modulators, combining the device cost-effective IQ modulator with finite-ER and efficient SSBI-free phase-diverse direct detection receiver. Specifically, the proposed solution transforms the inherent limitation of finite-ER of cost-effective IQ modulator into the residual optical carrier advantage of SSBI-free direct detection systems, eliminating SSBI without additional hardware and control complexity. A digital pre-distortion and offset correction algorithms, and a PD-thermal-noise constrained SSBI-free direct detection and signal recovery algorithms are derived and implemented. Comprehensive simulations are conducted. A Global-SNR gain of 1.78 dB and 400 Gb/s data rate are achieved in 100-km SSMF transmission when (ER_i, ER_o)= (7 dB, 25 dB) of IQ modulator. The proposed solution enables low-complexity, cost-effective, and spectrally-efficient interconnects for next-generation datacenters.
An Industrial-Scale Insurance LLM Achieving Verifiable Domain Mastery and Hallucination Control without Competence Trade-offs
Mar 15, 2026Adapting Large Language Models (LLMs) to high-stakes vertical domains like insurance presents a significant challenge: scenarios demand strict adherence to complex regulations and business logic with zero tolerance for hallucinations. Existing approaches often suffer from a Competency Trade-off - sacrificing general intelligence for domain expertise - or rely heavily on RAG without intrinsic reasoning. To bridge this gap, we present INS-S1, an insurance-specific LLM family trained via a novel end-to-end alignment paradigm. Our approach features two methodological innovations: (1) A Verifiable Data Synthesis System that constructs hierarchical datasets for actuarial reasoning and compliance; and (2) A Progressive SFT-RL Curriculum Framework that integrates dynamic data annealing with a synergistic mix of Verified Reasoning (RLVR) and AI Feedback (RLAIF). By optimizing data ratios and reward signals, this framework enforces domain constraints while preventing catastrophic forgetting. Additionally, we release INSEva, the most comprehensive insurance benchmark to date (39k+ samples). Extensive experiments show that INS-S1 achieves SOTA performance on domain tasks, significantly outperforming DeepSeek-R1 and Gemini-2.5-Pro. Crucially, it maintains top-tier general capabilities and achieves a record-low 0.6% hallucination rate (HHEM). Our results demonstrate that rigorous domain specialization can be achieved without compromising general intelligence.
FlexMS is a flexible framework for benchmarking deep learning-based mass spectrum prediction tools in metabolomics
Feb 26, 2026The identification and property prediction of chemical molecules is of central importance in the advancement of drug discovery and material science, where the tandem mass spectrometry technology gives valuable fragmentation cues in the form of mass-to-charge ratio peaks. However, the lack of experimental spectra hinders the attachment of each molecular identification, and thus urges the establishment of prediction approaches for computational models. Deep learning models appear promising for predicting molecular structure spectra, but overall assessment remains challenging as a result of the heterogeneity in methods and the lack of well-defined benchmarks. To address this, our contribution is the creation of benchmark framework FlexMS for constructing and evaluating diverse model architectures in mass spectrum prediction. With its easy-to-use flexibility, FlexMS supports the dynamic construction of numerous distinct combinations of model architectures, while assessing their performance on preprocessed public datasets using different metrics. In this paper, we provide insights into factors influencing performance, including the structural diversity of datasets, hyperparameters like learning rate and data sparsity, pretraining effects, metadata ablation settings and cross-domain transfer learning analysis. This provides practical guidance in choosing suitable models. Moreover, retrieval benchmarks simulate practical identification scenarios and score potential matches based on predicted spectra.
The Swarm Intelligence Freeway-Urban Trajectories (SWIFTraj) Dataset - Part II: A Graph-Based Approach for Trajectory Connection
Feb 25, 2026In Part I of this companion paper series, we introduced SWIFTraj, a new open-source vehicle trajectory dataset collected using a unmanned aerial vehicle (UAV) swarm. The dataset has two distinctive features. First, by connecting trajectories across consecutive UAV videos, it provides long-distance continuous trajectories, with the longest exceeding 4.5 km. Second, it covers an integrated traffic network consisting of both freeways and their connected urban roads. Obtaining such long-distance continuous trajectories from a UAV swarm is challenging, due to the need for accurate time alignment across multiple videos and the irregular spatial distribution of UAVs. To address these challenges, this paper proposes a novel graph-based approach for connecting vehicle trajectories captured by a UAV swarm. An undirected graph is constructed to represent flexible UAV layouts, and an automatic time alignment method based on trajectory matching cost minimization is developed to estimate optimal time offsets across videos. To associate trajectories of the same vehicle observed in different videos, a vehicle matching table is established using the Hungarian algorithm. The proposed approach is evaluated using both simulated and real-world data. Results from real-world experiments show that the time alignment error is within three video frames, corresponding to approximately 0.1 s, and that the vehicle matching achieves an F1-score of about 0.99. These results demonstrate the effectiveness of the proposed method in addressing key challenges in UAV-based trajectory connection and highlight its potential for large-scale vehicle trajectory collection.
A Confidence-Variance Theory for Pseudo-Label Selection in Semi-Supervised Learning
Jan 16, 2026Most pseudo-label selection strategies in semi-supervised learning rely on fixed confidence thresholds, implicitly assuming that prediction confidence reliably indicates correctness. In practice, deep networks are often overconfident: high-confidence predictions can still be wrong, while informative low-confidence samples near decision boundaries are discarded. This paper introduces a Confidence-Variance (CoVar) theory framework that provides a principled joint reliability criterion for pseudo-label selection. Starting from the entropy minimization principle, we derive a reliability measure that combines maximum confidence (MC) with residual-class variance (RCV), which characterizes how probability mass is distributed over non-maximum classes. The derivation shows that reliable pseudo-labels should have both high MC and low RCV, and that the influence of RCV increases as confidence grows, thereby correcting overconfident but unstable predictions. From this perspective, we cast pseudo-label selection as a spectral relaxation problem that maximizes separability in a confidence-variance feature space, and design a threshold-free selection mechanism to distinguish high- from low-reliability predictions. We integrate CoVar as a plug-in module into representative semi-supervised semantic segmentation and image classification methods. Across PASCAL VOC 2012, Cityscapes, CIFAR-10, and Mini-ImageNet with varying label ratios and backbones, it consistently improves over strong baselines, indicating that combining confidence with residual-class variance provides a more reliable basis for pseudo-label selection than fixed confidence thresholds. (Code: https://github.com/ljs11528/CoVar_Pseudo_Label_Selection.git)
How vehicles change lanes after encountering crashes: Empirical analysis and modeling
Jan 13, 2026When a traffic crash occurs, following vehicles need to change lanes to bypass the obstruction. We define these maneuvers as post crash lane changes. In such scenarios, vehicles in the target lane may refuse to yield even after the lane change has already begun, increasing the complexity and crash risk of post crash LCs. However, the behavioral characteristics and motion patterns of post crash LCs remain unknown. To address this gap, we construct a post crash LC dataset by extracting vehicle trajectories from drone videos captured after crashes. Our empirical analysis reveals that, compared to mandatory LCs (MLCs) and discretionary LCs (DLCs), post crash LCs exhibit longer durations, lower insertion speeds, and higher crash risks. Notably, 79.4% of post crash LCs involve at least one instance of non yielding behavior from the new follower, compared to 21.7% for DLCs and 28.6% for MLCs. Building on these findings, we develop a novel trajectory prediction framework for post crash LCs. At its core is a graph based attention module that explicitly models yielding behavior as an auxiliary interaction aware task. This module is designed to guide both a conditional variational autoencoder and a Transformer based decoder to predict the lane changer's trajectory. By incorporating the interaction aware module, our model outperforms existing baselines in trajectory prediction performance by more than 10% in both average displacement error and final displacement error across different prediction horizons. Moreover, our model provides more reliable crash risk analysis by reducing false crash rates and improving conflict prediction accuracy. Finally, we validate the model's transferability using additional post crash LC datasets collected from different sites.
Software-Hardware Co-optimization for Modular E2E AV Paradigm: A Unified Framework of Optimization Approaches, Simulation Environment and Evaluation Metrics
Jan 12, 2026Modular end-to-end (ME2E) autonomous driving paradigms combine modular interpretability with global optimization capability and have demonstrated strong performance. However, existing studies mainly focus on accuracy improvement, while critical system-level factors such as inference latency and energy consumption are often overlooked, resulting in increasingly complex model designs that hinder practical deployment. Prior efforts on model compression and acceleration typically optimize either the software or hardware side in isolation. Software-only optimization cannot fundamentally remove intermediate tensor access and operator scheduling overheads, whereas hardware-only optimization is constrained by model structure and precision. As a result, the real-world benefits of such optimizations are often limited. To address these challenges, this paper proposes a reusable software and hardware co-optimization and closed-loop evaluation framework for ME2E autonomous driving inference. The framework jointly integrates software-level model optimization with hardware-level computation optimization under a unified system-level objective. In addition, a multidimensional evaluation metric is introduced to assess system performance by jointly considering safety, comfort, efficiency, latency, and energy, enabling quantitative comparison of different optimization strategies. Experiments across multiple ME2E autonomous driving stacks show that the proposed framework preserves baseline-level driving performance while significantly reducing inference latency and energy consumption, achieving substantial overall system-level improvements. These results demonstrate that the proposed framework provides practical and actionable guidance for efficient deployment of ME2E autonomous driving systems.
PFA-NS: Power-Fading-Aware Noise Shaping Enabled C-Band IMDD System with Low Resolution DAC
Dec 23, 2025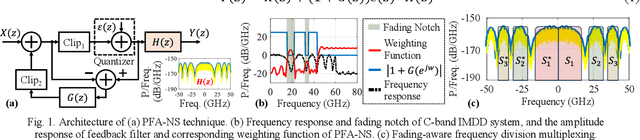
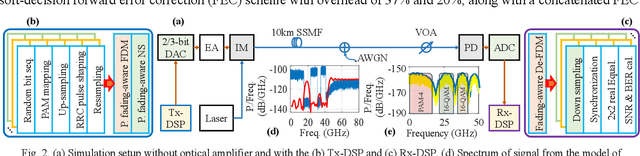
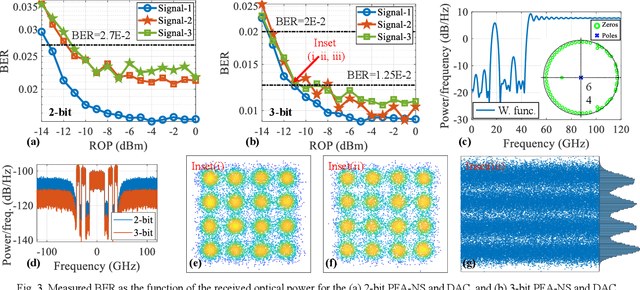
We propose and demonstrate a power-fading-aware noise-shaping technique for C-band IMDD system with low resolution DAC, which shapes and concentrates quantization noise within the fading-induced notch areas, yielding 94% improvement in data-rate over traditional counterpart.
EDA-RoF: Elastic Digital-Analog Radio-Over-Fiber (RoF) Modulation and Demodulation Architecture Enabling Seamless Transition Between Analog RoF and Digital RoF
Dec 23, 2025We propose and demonstrate an elastic digital-analog radio-over-fiber (RoF) modulation and demodulation architecture, seamlessly bridging A-RoF and D-RoF solutions, achieving quasilinear SNR scaling with respect to 1/η, and evidenced by R^2=0.9908.