 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRRP-Voice: A Longitudinal Dataset and Benchmark for Recurrent Respiratory Papillomatosis Detection
Jun 01, 2026Deep learning has advanced pathological voice detection rapidly, yet rare laryngeal diseases remain underexplored due to data scarcity. Recurrent Respiratory Papillomatosis (RRP) exemplifies this gap: an HPV-induced disease of the larynx in which patients oscillate between recurrence and post-surgical remission over the years. RRP demands continuous voice monitoring that existing cross-sectional corpora cannot support. We introduce the first longitudinal voice dataset for RRP, comprising recordings from 26 patients with up to ten years of follow-up. Each session pairs sustained vowels with sentence-level utterances, which are annotated by otolaryngologists and confirmed synchronously with laryngoscopy. Building on this resource, we establish a systematic benchmark spanning handcrafted features, end-to-end deep networks, self-supervised pretrained models, and recent audio large language models, all evaluated under session-level cross-validation with patient-level audit. Per-subject longitudinal analyses further confirm that the cross-sectional discriminative signal reflects laryngoscopic disease state rather than stable speaker attributes. This work lays a foundation for rare longitudinal pathological voice tasks in low-resource clinical settings.
Few-Shot and Pseudo-Label Guided Speech Quality Evaluation with Large Language Models
Apr 15, 2026In this paper, we introduce GatherMOS, a novel framework that leverages large language models (LLM) as meta-evaluators to aggregate diverse signals into quality predictions. GatherMOS integrates lightweight acoustic descriptors with pseudo-labels from DNSMOS and VQScore, enabling the LLM to reason over heterogeneous inputs and infer perceptual mean opinion scores (MOS). We further explore both zero-shot and few-shot in-context learning setups, showing that zero-shot GatherMOS maintains stable performance across diverse conditions, while few-shot guidance yields large gains when support samples match the test conditions. Experiments on the VoiceBank-DEMAND dataset demonstrate that GatherMOS consistently outperforms DNSMOS, VQScore, naive score averaging, and even learning-based models such as CNN-BLSTM and MOS-SSL when trained under limited labeled-data conditions. These results highlight the potential of LLM-based aggregation as a practical strategy for non-intrusive speech quality evaluation.
Tracking Listener Attention: Gaze-Guided Audio-Visual Speech Enhancement Framework
Apr 09, 2026This paper presents a Gaze-Guided Audio-Visual Speech Enhancement (GG-AVSE) framework to address the cocktail party problem. A major challenge in conventional AVSE is identifying the listener's intended speaker in multi-talker environments. GG-AVSE addresses this issue by exploiting gaze direction as a supervisory cue for target-speaker selection. Specifically, we propose the GG-VM module, which combines gaze signals with a YOLO5Face detector to extract the target speaker's facial features and integrates them with the pretrained AVSEMamba model through two strategies: zero-shot merging and partial visual fine-tuning. For evaluation, we introduce the AVSEC2-Gaze dataset. Experimental results show that GG-AVSE achieves substantial performance gains over gaze-free baselines: a 10.08% improvement in PESQ (2.370 to 2.609), a 5.18% improvement in STOI (0.8802 to 0.9258), and a 23.69% improvement in SI-SDR (9.16 to 11.33). These results confirm that gaze provides an effective cue for resolving target-speaker ambiguity and highlight the scalability of GG-AVSE for real-world applications.
SAVe: Self-Supervised Audio-visual Deepfake Detection Exploiting Visual Artifacts and Audio-visual Misalignment
Mar 26, 2026Multimodal deepfakes can exhibit subtle visual artifacts and cross-modal inconsistencies, which remain challenging to detect, especially when detectors are trained primarily on curated synthetic forgeries. Such synthetic dependence can introduce dataset and generator bias, limiting scalability and robustness to unseen manipulations. We propose SAVe, a self-supervised audio-visual deepfake detection framework that learns entirely on authentic videos. SAVe generates on-the-fly, identity-preserving, region-aware self-blended pseudo-manipulations to emulate tampering artifacts, enabling the model to learn complementary visual cues across multiple facial granularities. To capture cross-modal evidence, SAVe also models lip-speech synchronization via an audio-visual alignment component that detects temporal misalignment patterns characteristic of audio-visual forgeries. Experiments on FakeAVCeleb and AV-LipSync-TIMIT demonstrate competitive in-domain performance and strong cross-dataset generalization, highlighting self-supervised learning as a scalable paradigm for multimodal deepfake detection.
TaigiSpeech: A Low-Resource Real-World Speech Intent Dataset and Preliminary Results with Scalable Data Mining In-the-Wild
Mar 23, 2026Speech technologies have advanced rapidly and serve diverse populations worldwide. However, many languages remain underrepresented due to limited resources. In this paper, we introduce \textbf{TaigiSpeech}, a real-world speech intent dataset in Taiwanese Taigi (aka Taiwanese Hokkien/Southern Min), which is a low-resource and primarily spoken language. The dataset is collected from older adults, comprising 21 speakers with a total of 3k utterances. It is designed for practical intent detection scenarios, including healthcare and home assistant applications. To address the scarcity of labeled data, we explore two data mining strategies with two levels of supervision: keyword match data mining with LLM pseudo labeling via an intermediate language and an audio-visual framework that leverages multimodal cues with minimal textual supervision. This design enables scalable dataset construction for low-resource and unwritten spoken languages. TaigiSpeech will be released under the CC BY 4.0 license to facilitate broad adoption and research on low-resource and unwritten languages. The project website and the dataset can be found on https://kwchang.org/taigispeech.
How Auditory Knowledge in LLM Backbones Shapes Audio Language Models: A Holistic Evaluation
Mar 19, 2026Large language models (LLMs) have been widely used as knowledge backbones of Large Audio Language Models (LALMs), yet how much auditory knowledge they encode through text-only pre-training and how this affects downstream performance remains unclear. We study this gap by comparing different LLMs under two text-only and one audio-grounded setting: (1) direct probing on AKB-2000, a curated benchmark testing the breadth and depth of auditory knowledge; (2) cascade evaluation, where LLMs reason over text descriptions from an audio captioner; and (3) audio-grounded evaluation, where each LLM is fine-tuned into a Large Audio Language Model (LALM) with an audio encoder. Our findings reveal that auditory knowledge varies substantially across families, and text-only results are strongly correlated with audio performance. Our work provides empirical grounding for a comprehensive understanding of LLMs in audio research.
LLM-Guided Reinforcement Learning for Audio-Visual Speech Enhancement
Mar 17, 2026In existing Audio-Visual Speech Enhancement (AVSE) methods, objectives such as Scale-Invariant Signal-to-Noise Ratio (SI-SNR) and Mean Squared Error (MSE) are widely used; however, they often correlate poorly with perceptual quality and provide limited interpretability for optimization. This work proposes a reinforcement learning-based AVSE framework with a Large Language Model (LLM)-based interpretable reward model. An audio LLM generates natural language descriptions of enhanced speech, which are converted by a sentiment analysis model into a 1-5 rating score serving as the PPO reward for fine-tuning a pretrained AVSE model. Compared with scalar metrics, LLM-generated feedback is semantically rich and explicitly describes improvements in speech quality. Experiments on the 4th COG-MHEAR AVSE Challenge (AVSEC-4) dataset show that the proposed method outperforms a supervised baseline and a DNSMOS-based RL baseline in PESQ, STOI, neural quality metrics, and subjective listening tests.
MOS-Bias: From Hidden Gender Bias to Gender-Aware Speech Quality Assessment
Mar 11, 2026The Mean Opinion Score (MOS) serves as the standard metric for speech quality assessment, yet biases in human annotations remain underexplored. We conduct the first systematic analysis of gender bias in MOS, revealing that male listeners consistently assign higher scores than female listeners--a gap that is most pronounced in low-quality speech and gradually diminishes as quality improves. This quality-dependent structure proves difficult to eliminate through simple calibration. We further demonstrate that automated MOS models trained on aggregated labels exhibit predictions skewed toward male standards of perception. To address this, we propose a gender-aware model that learns gender-specific scoring patterns through abstracting binary group embeddings, thereby improving overall and gender-specific prediction accuracy. This study establishes that gender bias in MOS constitutes a systematic, learnable pattern demanding attention in equitable speech evaluation.
Visual-Informed Speech Enhancement Using Attention-Based Beamforming
Mar 05, 2026Recent studies have demonstrated that incorporating auxiliary information, such as speaker voiceprint or visual cues, can substantially improve Speech Enhancement (SE) performance. However, single-channel methods often yield suboptimal results in low signal-to-noise ratio (SNR) conditions, when there is high reverberation, or in complex scenarios involving dynamic speakers, overlapping speech, or non-stationary noise. To address these issues, we propose a novel Visual-Informed Neural Beamforming Network (VI-NBFNet), which integrates microphone array signal processing and deep neural networks (DNNs) using multimodal input features. The proposed network leverages a pretrained visual speech recognition model to extract lip movements as input features, which serve for voice activity detection (VAD) and target speaker identification. The system is intended to handle both static and moving speakers by introducing a supervised end-to-end beamforming framework equipped with an attention mechanism. The experimental results demonstrated that the proposed audiovisual system has achieved better SE performance and robustness for both stationary and dynamic speaker scenarios, compared to several baseline methods.
* 15 pages, 14 figures
MEGState: Phoneme Decoding from Magnetoencephalography Signals
Dec 19, 2025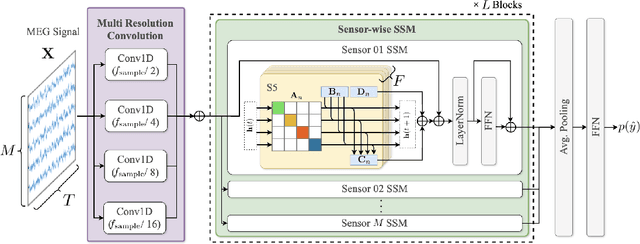
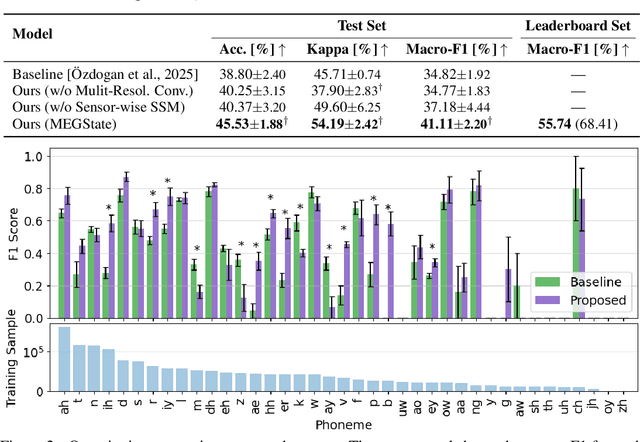
Decoding linguistically meaningful representations from non-invasive neural recordings remains a central challenge in neural speech decoding. Among available neuroimaging modalities, magnetoencephalography (MEG) provides a safe and repeatable means of mapping speech-related cortical dynamics, yet its low signal-to-noise ratio and high temporal dimensionality continue to hinder robust decoding. In this work, we introduce MEGState, a novel architecture for phoneme decoding from MEG signals that captures fine-grained cortical responses evoked by auditory stimuli. Extensive experiments on the LibriBrain dataset demonstrate that MEGState consistently surpasses baseline model across multiple evaluation metrics. These findings highlight the potential of MEG-based phoneme decoding as a scalable pathway toward non-invasive brain-computer interfaces for speech.