 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Fine-grained Causal Reasoning and QA
Apr 15, 2022
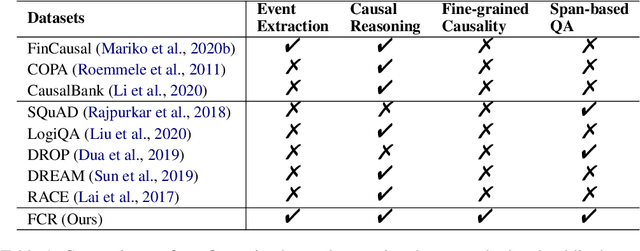

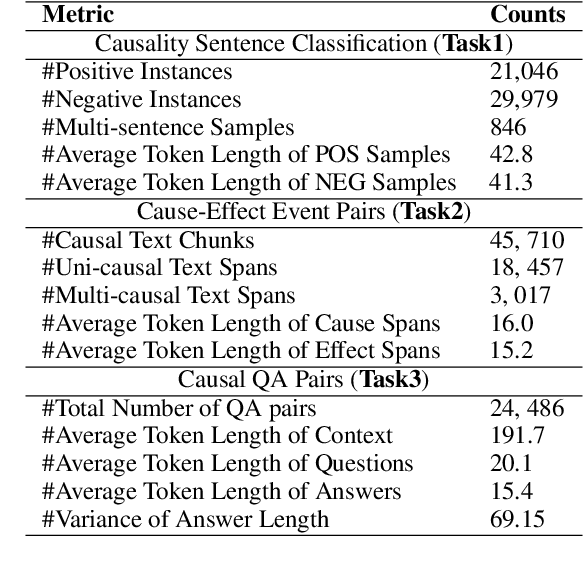
Understanding causality is key to the success of NLP applications, especially in high-stakes domains. Causality comes in various perspectives such as enable and prevent that, despite their importance, have been largely ignored in the literature. This paper introduces a novel fine-grained causal reasoning dataset and presents a series of novel predictive tasks in NLP, such as causality detection, event causality extraction, and Causal QA. Our dataset contains human annotations of 25K cause-effect event pairs and 24K question-answering pairs within multi-sentence samples, where each can have multiple causal relationships. Through extensive experiments and analysis, we show that the complex relations in our dataset bring unique challenges to state-of-the-art methods across all three tasks and highlight potential research opportunities, especially in developing "causal-thinking" methods.
Generating Data to Mitigate Spurious Correlations in Natural Language Inference Datasets
Mar 24, 2022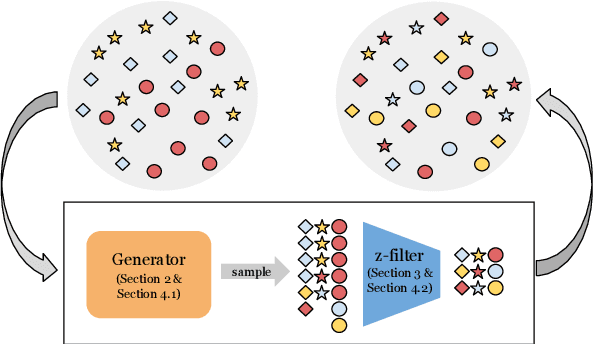
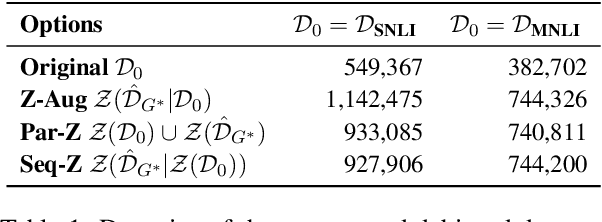
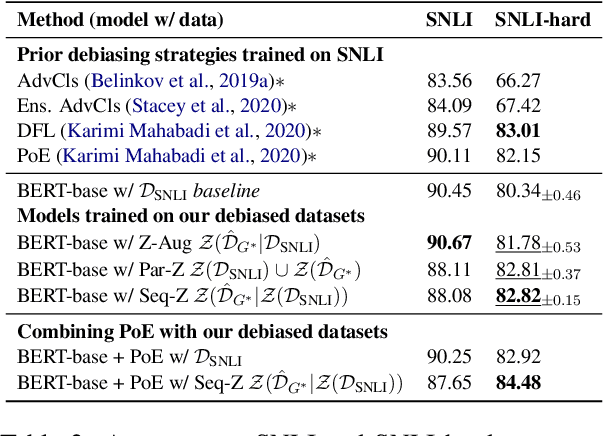
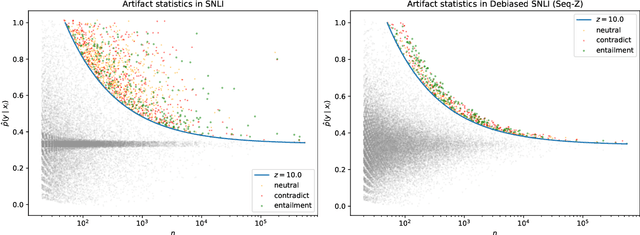
Natural language processing models often exploit spurious correlations between task-independent features and labels in datasets to perform well only within the distributions they are trained on, while not generalising to different task distributions. We propose to tackle this problem by generating a debiased version of a dataset, which can then be used to train a debiased, off-the-shelf model, by simply replacing its training data. Our approach consists of 1) a method for training data generators to generate high-quality, label-consistent data samples; and 2) a filtering mechanism for removing data points that contribute to spurious correlations, measured in terms of z-statistics. We generate debiased versions of the SNLI and MNLI datasets, and we evaluate on a large suite of debiased, out-of-distribution, and adversarial test sets. Results show that models trained on our debiased datasets generalise better than those trained on the original datasets in all settings. On the majority of the datasets, our method outperforms or performs comparably to previous state-of-the-art debiasing strategies, and when combined with an orthogonal technique, product-of-experts, it improves further and outperforms previous best results of SNLI-hard and MNLI-hard.
Rapid detection and recognition of whole brain activity in a freely behaving Caenorhabditis elegans
Sep 23, 2021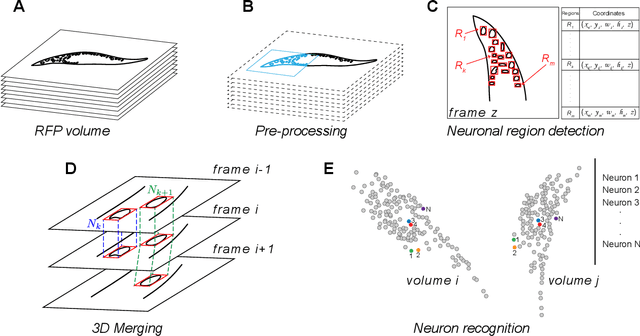

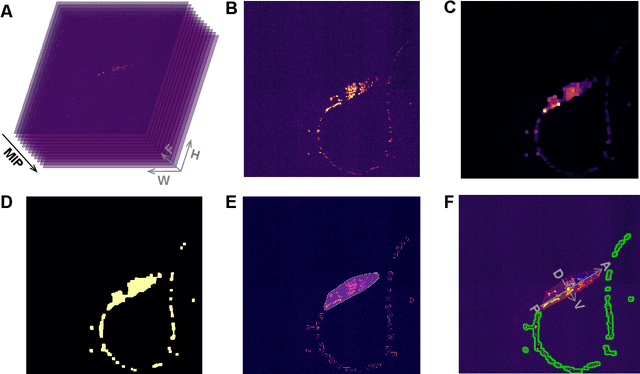
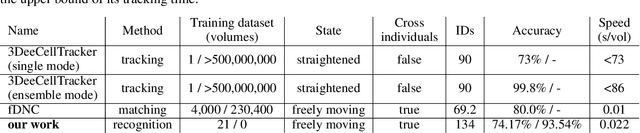
Advanced volumetric imaging methods and genetically encoded activity indicators have permitted a comprehensive characterization of whole brain activity at single neuron resolution in \textit{Caenorhabditis elegans}. The constant motion and deformation of the mollusc nervous system, however, impose a great challenge for a consistent identification of densely packed neurons in a behaving animal. Here, we propose a cascade solution for long-term and rapid recognition of head ganglion neurons in a freely moving \textit{C. elegans}. First, potential neuronal regions from a stack of fluorescence images are detected by a deep learning algorithm. Second, 2 dimensional neuronal regions are fused into 3 dimensional neuron entities. Third, by exploiting the neuronal density distribution surrounding a neuron and relative positional information between neurons, a multi-class artificial neural network transforms engineered neuronal feature vectors into digital neuronal identities. Under the constraint of a small number (20-40 volumes) of training samples, our bottom-up approach is able to process each volume - $1024 \times 1024 \times 18$ in voxels - in less than 1 second and achieves an accuracy of $91\%$ in neuronal detection and $74\%$ in neuronal recognition. Our work represents an important development towards a rapid and fully automated algorithm for decoding whole brain activity underlying natural animal behaviors.
Training Adaptive Computation for Open-Domain Question Answering with Computational Constraints
Jul 05, 2021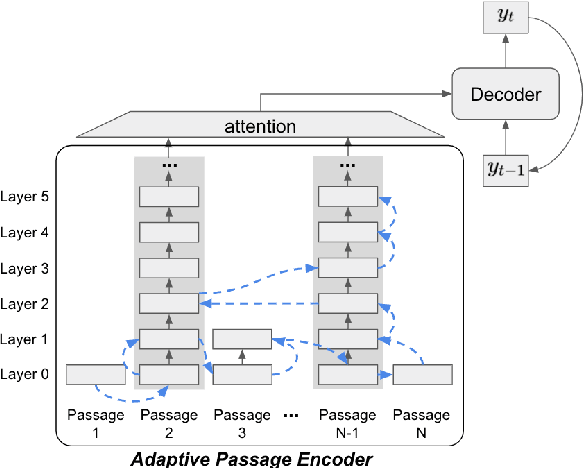
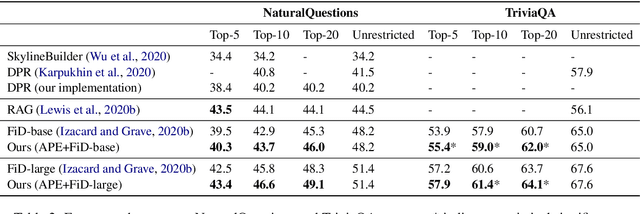
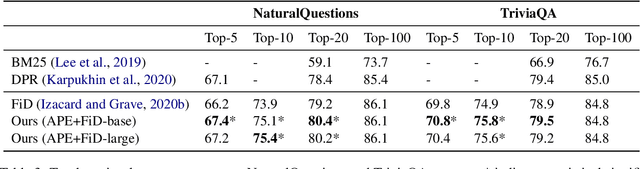
Adaptive Computation (AC) has been shown to be effective in improving the efficiency of Open-Domain Question Answering (ODQA) systems. However, current AC approaches require tuning of all model parameters, and training state-of-the-art ODQA models requires significant computational resources that may not be available for most researchers. We propose Adaptive Passage Encoder, an AC method that can be applied to an existing ODQA model and can be trained efficiently on a single GPU. It keeps the parameters of the base ODQA model fixed, but it overrides the default layer-by-layer computation of the encoder with an AC policy that is trained to optimise the computational efficiency of the model. Our experimental results show that our method improves upon a state-of-the-art model on two datasets, and is also more accurate than previous AC methods due to the stronger base ODQA model. All source code and datasets are available at https://github.com/uclnlp/APE.
PAQ: 65 Million Probably-Asked Questions and What You Can Do With Them
Feb 13, 2021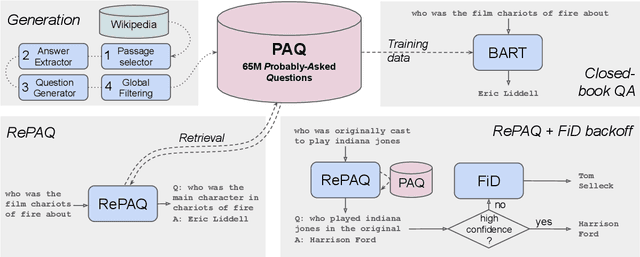
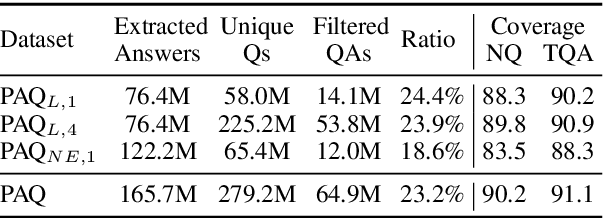

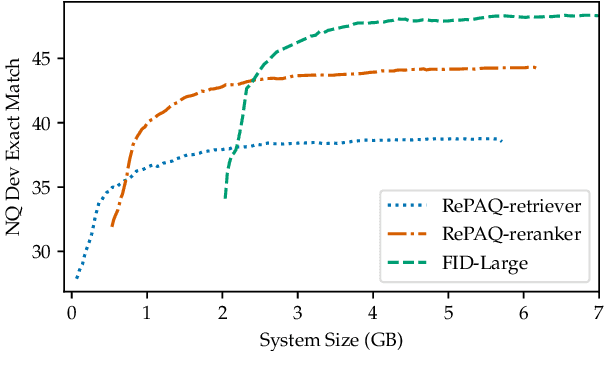
Open-domain Question Answering models which directly leverage question-answer (QA) pairs, such as closed-book QA (CBQA) models and QA-pair retrievers, show promise in terms of speed and memory compared to conventional models which retrieve and read from text corpora. QA-pair retrievers also offer interpretable answers, a high degree of control, and are trivial to update at test time with new knowledge. However, these models lack the accuracy of retrieve-and-read systems, as substantially less knowledge is covered by the available QA-pairs relative to text corpora like Wikipedia. To facilitate improved QA-pair models, we introduce Probably Asked Questions (PAQ), a very large resource of 65M automatically-generated QA-pairs. We introduce a new QA-pair retriever, RePAQ, to complement PAQ. We find that PAQ preempts and caches test questions, enabling RePAQ to match the accuracy of recent retrieve-and-read models, whilst being significantly faster. Using PAQ, we train CBQA models which outperform comparable baselines by 5%, but trail RePAQ by over 15%, indicating the effectiveness of explicit retrieval. RePAQ can be configured for size (under 500MB) or speed (over 1K questions per second) whilst retaining high accuracy. Lastly, we demonstrate RePAQ's strength at selective QA, abstaining from answering when it is likely to be incorrect. This enables RePAQ to ``back-off" to a more expensive state-of-the-art model, leading to a combined system which is both more accurate and 2x faster than the state-of-the-art model alone.
NeurIPS 2020 EfficientQA Competition: Systems, Analyses and Lessons Learned
Jan 01, 2021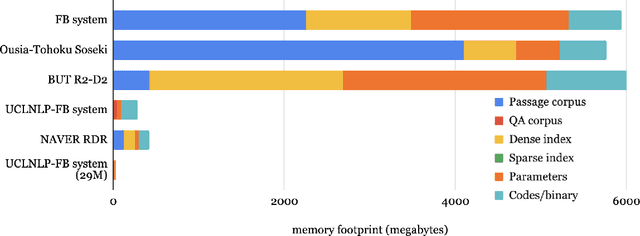
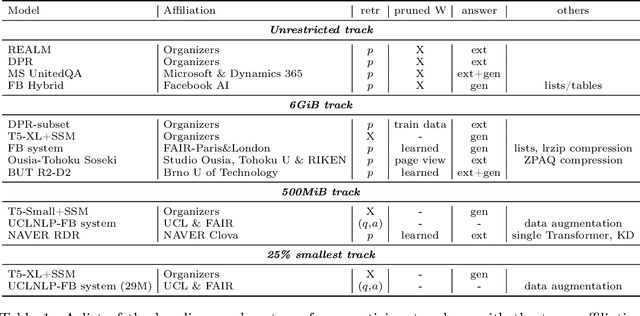
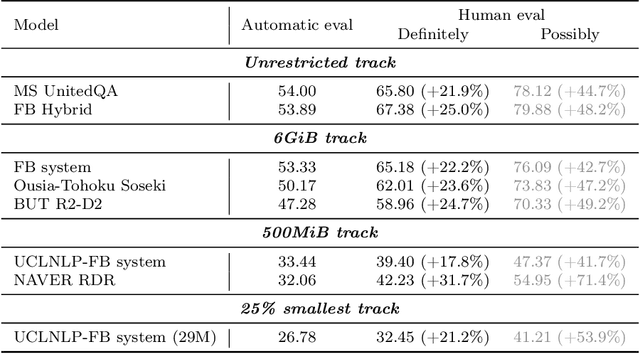
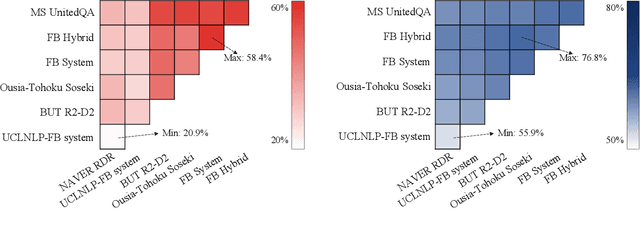
We review the EfficientQA competition from NeurIPS 2020. The competition focused on open-domain question answering (QA), where systems take natural language questions as input and return natural language answers. The aim of the competition was to build systems that can predict correct answers while also satisfying strict on-disk memory budgets. These memory budgets were designed to encourage contestants to explore the trade-off between storing large, redundant, retrieval corpora or the parameters of large learned models. In this report, we describe the motivation and organization of the competition, review the best submissions, and analyze system predictions to inform a discussion of evaluation for open-domain QA.
Don't Read Too Much into It: Adaptive Computation for Open-Domain Question Answering
Nov 10, 2020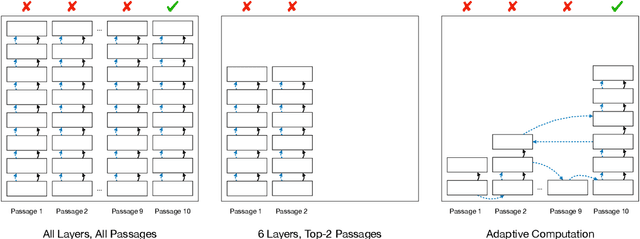
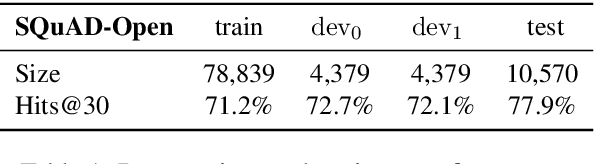
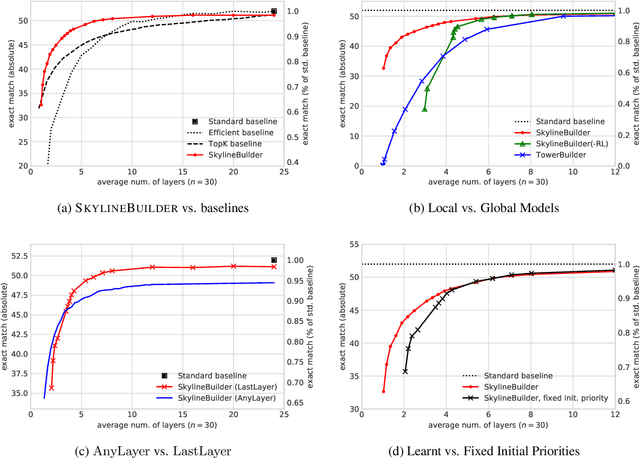
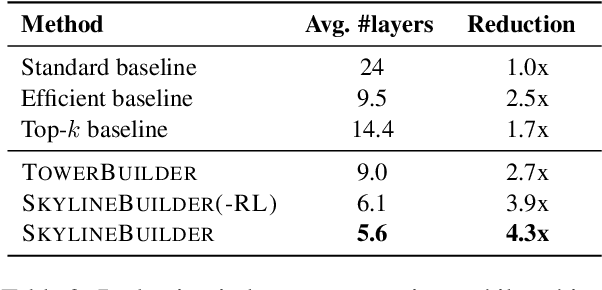
Most approaches to Open-Domain Question Answering consist of a light-weight retriever that selects a set of candidate passages, and a computationally expensive reader that examines the passages to identify the correct answer. Previous works have shown that as the number of retrieved passages increases, so does the performance of the reader. However, they assume all retrieved passages are of equal importance and allocate the same amount of computation to them, leading to a substantial increase in computational cost. To reduce this cost, we propose the use of adaptive computation to control the computational budget allocated for the passages to be read. We first introduce a technique operating on individual passages in isolation which relies on anytime prediction and a per-layer estimation of an early exit probability. We then introduce SkylineBuilder, an approach for dynamically deciding on which passage to allocate computation at each step, based on a resource allocation policy trained via reinforcement learning. Our results on SQuAD-Open show that adaptive computation with global prioritisation improves over several strong static and adaptive methods, leading to a 4.3x reduction in computation while retaining 95% performance of the full model.
How Context Affects Language Models' Factual Predictions
May 10, 2020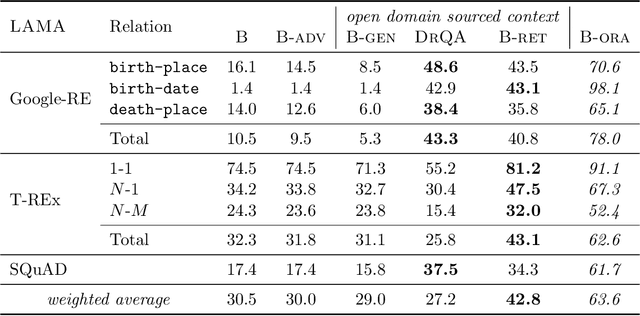
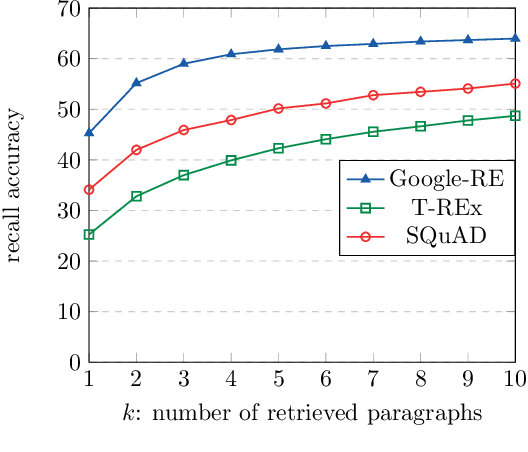
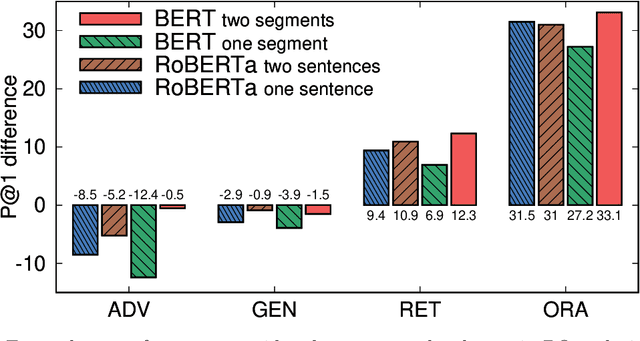
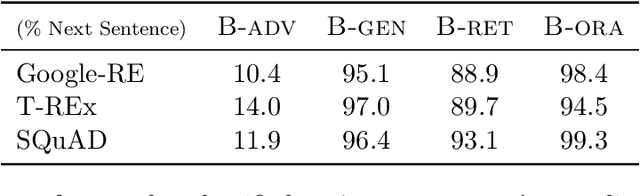
When pre-trained on large unsupervised textual corpora, language models are able to store and retrieve factual knowledge to some extent, making it possible to use them directly for zero-shot cloze-style question answering. However, storing factual knowledge in a fixed number of weights of a language model clearly has limitations. Previous approaches have successfully provided access to information outside the model weights using supervised architectures that combine an information retrieval system with a machine reading component. In this paper, we go a step further and integrate information from a retrieval system with a pre-trained language model in a purely unsupervised way. We report that augmenting pre-trained language models in this way dramatically improves performance and that the resulting system, despite being unsupervised, is competitive with a supervised machine reading baseline. Furthermore, processing query and context with different segment tokens allows BERT to utilize its Next Sentence Prediction pre-trained classifier to determine whether the context is relevant or not, substantially improving BERT's zero-shot cloze-style question-answering performance and making its predictions robust to noisy contexts.
Language Models as Knowledge Bases?
Sep 04, 2019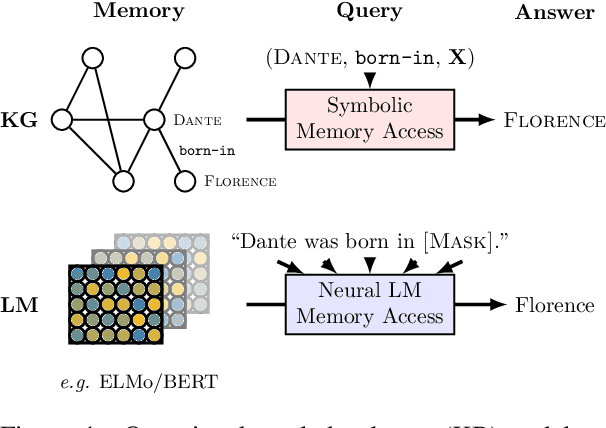
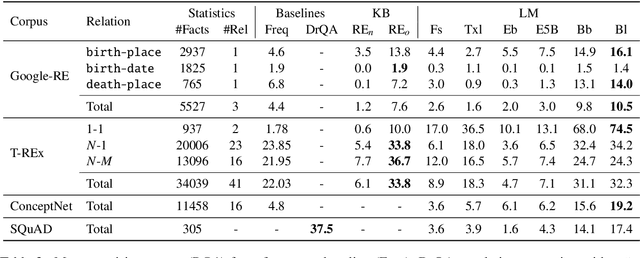
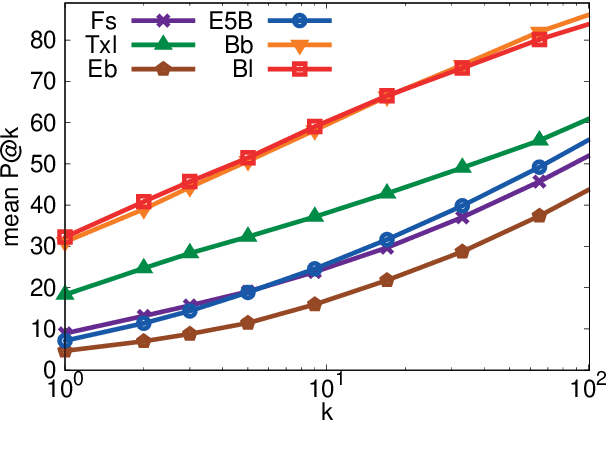
Recent progress in pretraining language models on large textual corpora led to a surge of improvements for downstream NLP tasks. Whilst learning linguistic knowledge, these models may also be storing relational knowledge present in the training data, and may be able to answer queries structured as "fill-in-the-blank" cloze statements. Language models have many advantages over structured knowledge bases: they require no schema engineering, allow practitioners to query about an open class of relations, are easy to extend to more data, and require no human supervision to train. We present an in-depth analysis of the relational knowledge already present (without fine-tuning) in a wide range of state-of-the-art pretrained language models. We find that (i) without fine-tuning, BERT contains relational knowledge competitive with traditional NLP methods that have some access to oracle knowledge, (ii) BERT also does remarkably well on open-domain question answering against a supervised baseline, and (iii) certain types of factual knowledge are learned much more readily than others by standard language model pretraining approaches. The surprisingly strong ability of these models to recall factual knowledge without any fine-tuning demonstrates their potential as unsupervised open-domain QA systems. The code to reproduce our analysis is available at https://github.com/facebookresearch/LAMA.
Segmentation is All You Need
May 26, 2019
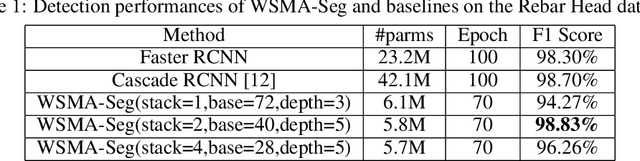
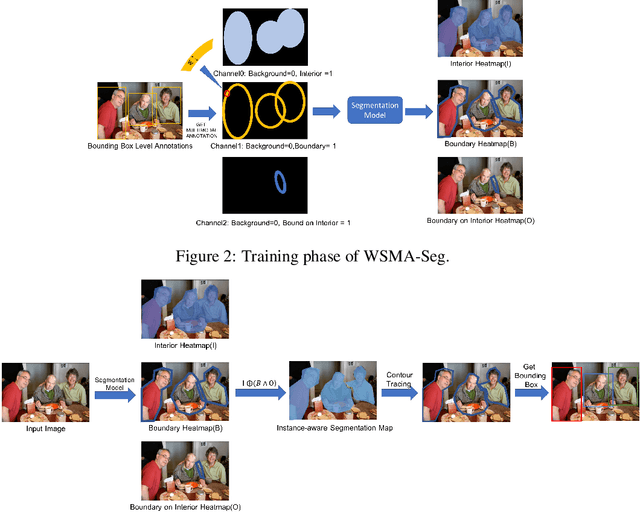
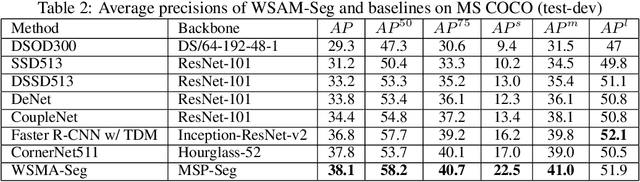
Region proposal mechanisms are essential for existing deep learning approaches to object detection in images. Although they can generally achieve a good detection performance under normal circumstances, their recall in a scene with extreme cases is unacceptably low. This is mainly because bounding box annotations contain much environment noise information, and non-maximum suppression (NMS) is required to select target boxes. Therefore, in this paper, we propose the first anchor-free and NMS-free object detection model called weakly supervised multimodal annotation segmentation (WSMA-Seg), which utilizes segmentation models to achieve an accurate and robust object detection without NMS. In WSMA-Seg, multimodal annotations are proposed to achieve an instance-aware segmentation using weakly supervised bounding boxes; we also develop a run-data-based following algorithm to trace contours of objects. In addition, we propose a multi-scale pooling segmentation (MSP-Seg) as the underlying segmentation model of WSMA-Seg to achieve a more accurate segmentation and to enhance the detection accuracy of WSMA-Seg. Experimental results on multiple datasets show that the proposed WSMA-Seg approach outperforms the state-of-the-art detectors.