 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSFC-Net: A Dual-Encoder Spatial and Frequency Co-Awareness Network for Rural Road Extraction
Feb 01, 2026Accurate extraction of rural roads from high-resolution remote sensing imagery is essential for infrastructure planning and sustainable development. However, this task presents unique challenges in rural settings due to several factors. These include high intra-class variability and low inter-class separability from diverse surface materials, frequent vegetation occlusions that disrupt spatial continuity, and narrow road widths that exacerbate detection difficulties. Existing methods, primarily optimized for structured urban environments, often underperform in these scenarios as they overlook such distinctive characteristics. To address these challenges, we propose DSFC-Net, a dual-encoder framework that synergistically fuses spatial and frequency-domain information. Specifically, a CNN branch is employed to capture fine-grained local road boundaries and short-range continuity, while a novel Spatial-Frequency Hybrid Transformer (SFT) is introduced to robustly model global topological dependencies against vegetation occlusions. Distinct from standard attention mechanisms that suffer from frequency bias, the SFT incorporates a Cross-Frequency Interaction Attention (CFIA) module that explicitly decouples high- and low-frequency information via a Laplacian Pyramid strategy. This design enables the dynamic interaction between spatial details and frequency-aware global contexts, effectively preserving the connectivity of narrow roads. Furthermore, a Channel Feature Fusion Module (CFFM) is proposed to bridge the two branches by adaptively recalibrating channel-wise feature responses, seamlessly integrating local textures with global semantics for accurate segmentation. Comprehensive experiments on the WHU-RuR+, DeepGlobe, and Massachusetts datasets validate the superiority of DSFC-Net over state-of-the-art approaches.
P-EAGLE: Parallel-Drafting EAGLE with Scalable Training
Feb 01, 2026Reasoning LLMs produce longer outputs, requiring speculative decoding drafters trained on extended sequences. Parallel drafting - predicting multiple tokens per forward pass - offers latency benefits over sequential generation, but training complexity scales quadratically with the product of sequence length and parallel positions, rendering long-context training impractical. We present P(arallel)-EAGLE, which transforms EAGLE from autoregressive to parallel multi-token prediction via a learnable shared hidden state. To scale training to long contexts, we develop a framework featuring attention mask pre-computation and sequence partitioning techniques, enabling gradient accumulation within individual sequences for parallel-prediction training. We implement P-EAGLE in vLLM and demonstrate speedups of 1.10-1.36x over autoregressive EAGLE-3 across GPT-OSS 120B, 20B, and Qwen3-Coder 30B.
Cross-Modal Memory Compression for Efficient Multi-Agent Debate
Jan 31, 2026Multi-agent debate can improve reasoning quality and reduce hallucinations, but it incurs rapidly growing context as debate rounds and agent count increase. Retaining full textual histories leads to token usage that can exceed context limits and often requires repeated summarization, adding overhead and compounding information loss. We introduce DebateOCR, a cross-modal compression framework that replaces long textual debate traces with compact image representations, which are then consumed through a dedicated vision encoder to condition subsequent rounds. This design compresses histories that commonly span tens to hundreds of thousands of tokens, cutting input tokens by more than 92% and yielding substantially lower compute cost and faster inference across multiple benchmarks. We further provide a theoretical perspective showing that diversity across agents supports recovery of omitted information: although any single compressed history may discard details, aggregating multiple agents' compressed views allows the collective representation to approach the information bottleneck with exponentially high probability.
HiFi-Mesh: High-Fidelity Efficient 3D Mesh Generation via Compact Autoregressive Dependence
Jan 29, 2026High-fidelity 3D meshes can be tokenized into one-dimension (1D) sequences and directly modeled using autoregressive approaches for faces and vertices. However, existing methods suffer from insufficient resource utilization, resulting in slow inference and the ability to handle only small-scale sequences, which severely constrains the expressible structural details. We introduce the Latent Autoregressive Network (LANE), which incorporates compact autoregressive dependencies in the generation process, achieving a $6\times$ improvement in maximum generatable sequence length compared to existing methods. To further accelerate inference, we propose the Adaptive Computation Graph Reconfiguration (AdaGraph) strategy, which effectively overcomes the efficiency bottleneck of traditional serial inference through spatiotemporal decoupling in the generation process. Experimental validation demonstrates that LANE achieves superior performance across generation speed, structural detail, and geometric consistency, providing an effective solution for high-quality 3D mesh generation.
SUGAR: Learning Skeleton Representation with Visual-Motion Knowledge for Action Recognition
Nov 13, 2025Large Language Models (LLMs) hold rich implicit knowledge and powerful transferability. In this paper, we explore the combination of LLMs with the human skeleton to perform action classification and description. However, when treating LLM as a recognizer, two questions arise: 1) How can LLMs understand skeleton? 2) How can LLMs distinguish among actions? To address these problems, we introduce a novel paradigm named learning Skeleton representation with visUal-motion knowledGe for Action Recognition (SUGAR). In our pipeline, we first utilize off-the-shelf large-scale video models as a knowledge base to generate visual, motion information related to actions. Then, we propose to supervise skeleton learning through this prior knowledge to yield discrete representations. Finally, we use the LLM with untouched pre-training weights to understand these representations and generate the desired action targets and descriptions. Notably, we present a Temporal Query Projection (TQP) module to continuously model the skeleton signals with long sequences. Experiments on several skeleton-based action classification benchmarks demonstrate the efficacy of our SUGAR. Moreover, experiments on zero-shot scenarios show that SUGAR is more versatile than linear-based methods.
EndoIR: Degradation-Agnostic All-in-One Endoscopic Image Restoration via Noise-Aware Routing Diffusion
Nov 11, 2025Endoscopic images often suffer from diverse and co-occurring degradations such as low lighting, smoke, and bleeding, which obscure critical clinical details. Existing restoration methods are typically task-specific and often require prior knowledge of the degradation type, limiting their robustness in real-world clinical use. We propose EndoIR, an all-in-one, degradation-agnostic diffusion-based framework that restores multiple degradation types using a single model. EndoIR introduces a Dual-Domain Prompter that extracts joint spatial-frequency features, coupled with an adaptive embedding that encodes both shared and task-specific cues as conditioning for denoising. To mitigate feature confusion in conventional concatenation-based conditioning, we design a Dual-Stream Diffusion architecture that processes clean and degraded inputs separately, with a Rectified Fusion Block integrating them in a structured, degradation-aware manner. Furthermore, Noise-Aware Routing Block improves efficiency by dynamically selecting only noise-relevant features during denoising. Experiments on SegSTRONG-C and CEC datasets demonstrate that EndoIR achieves state-of-the-art performance across multiple degradation scenarios while using fewer parameters than strong baselines, and downstream segmentation experiments confirm its clinical utility.
Probing the Critical Point (CritPt) of AI Reasoning: a Frontier Physics Research Benchmark
Oct 01, 2025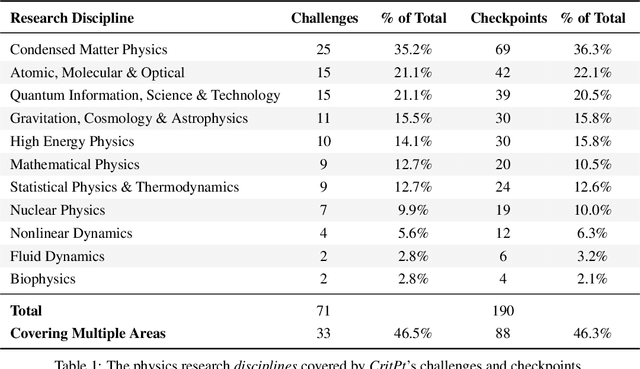



While large language models (LLMs) with reasoning capabilities are progressing rapidly on high-school math competitions and coding, can they reason effectively through complex, open-ended challenges found in frontier physics research? And crucially, what kinds of reasoning tasks do physicists want LLMs to assist with? To address these questions, we present the CritPt (Complex Research using Integrated Thinking - Physics Test, pronounced "critical point"), the first benchmark designed to test LLMs on unpublished, research-level reasoning tasks that broadly covers modern physics research areas, including condensed matter, quantum physics, atomic, molecular & optical physics, astrophysics, high energy physics, mathematical physics, statistical physics, nuclear physics, nonlinear dynamics, fluid dynamics and biophysics. CritPt consists of 71 composite research challenges designed to simulate full-scale research projects at the entry level, which are also decomposed to 190 simpler checkpoint tasks for more fine-grained insights. All problems are newly created by 50+ active physics researchers based on their own research. Every problem is hand-curated to admit a guess-resistant and machine-verifiable answer and is evaluated by an automated grading pipeline heavily customized for advanced physics-specific output formats. We find that while current state-of-the-art LLMs show early promise on isolated checkpoints, they remain far from being able to reliably solve full research-scale challenges: the best average accuracy among base models is only 4.0% , achieved by GPT-5 (high), moderately rising to around 10% when equipped with coding tools. Through the realistic yet standardized evaluation offered by CritPt, we highlight a large disconnect between current model capabilities and realistic physics research demands, offering a foundation to guide the development of scientifically grounded AI tools.
MambaControl: Anatomy Graph-Enhanced Mamba ControlNet with Fourier Refinement for Diffusion-Based Disease Trajectory Prediction
May 15, 2025Modelling disease progression in precision medicine requires capturing complex spatio-temporal dynamics while preserving anatomical integrity. Existing methods often struggle with longitudinal dependencies and structural consistency in progressive disorders. To address these limitations, we introduce MambaControl, a novel framework that integrates selective state-space modelling with diffusion processes for high-fidelity prediction of medical image trajectories. To better capture subtle structural changes over time while maintaining anatomical consistency, MambaControl combines Mamba-based long-range modelling with graph-guided anatomical control to more effectively represent anatomical correlations. Furthermore, we introduce Fourier-enhanced spectral graph representations to capture spatial coherence and multiscale detail, enabling MambaControl to achieve state-of-the-art performance in Alzheimer's disease prediction. Quantitative and regional evaluations demonstrate improved progression prediction quality and anatomical fidelity, highlighting its potential for personalised prognosis and clinical decision support.
PhysLLM: Harnessing Large Language Models for Cross-Modal Remote Physiological Sensing
May 06, 2025Remote photoplethysmography (rPPG) enables non-contact physiological measurement but remains highly susceptible to illumination changes, motion artifacts, and limited temporal modeling. Large Language Models (LLMs) excel at capturing long-range dependencies, offering a potential solution but struggle with the continuous, noise-sensitive nature of rPPG signals due to their text-centric design. To bridge this gap, we introduce PhysLLM, a collaborative optimization framework that synergizes LLMs with domain-specific rPPG components. Specifically, the Text Prototype Guidance (TPG) strategy is proposed to establish cross-modal alignment by projecting hemodynamic features into LLM-interpretable semantic space, effectively bridging the representational gap between physiological signals and linguistic tokens. Besides, a novel Dual-Domain Stationary (DDS) Algorithm is proposed for resolving signal instability through adaptive time-frequency domain feature re-weighting. Finally, rPPG task-specific cues systematically inject physiological priors through physiological statistics, environmental contextual answering, and task description, leveraging cross-modal learning to integrate both visual and textual information, enabling dynamic adaptation to challenging scenarios like variable illumination and subject movements. Evaluation on four benchmark datasets, PhysLLM achieves state-of-the-art accuracy and robustness, demonstrating superior generalization across lighting variations and motion scenarios.
Enhancing the Patent Matching Capability of Large Language Models via the Memory Graph
Apr 21, 2025



Intellectual Property (IP) management involves strategically protecting and utilizing intellectual assets to enhance organizational innovation, competitiveness, and value creation. Patent matching is a crucial task in intellectual property management, which facilitates the organization and utilization of patents. Existing models often rely on the emergent capabilities of Large Language Models (LLMs) and leverage them to identify related patents directly. However, these methods usually depend on matching keywords and overlook the hierarchical classification and categorical relationships of patents. In this paper, we propose MemGraph, a method that augments the patent matching capabilities of LLMs by incorporating a memory graph derived from their parametric memory. Specifically, MemGraph prompts LLMs to traverse their memory to identify relevant entities within patents, followed by attributing these entities to corresponding ontologies. After traversing the memory graph, we utilize extracted entities and ontologies to improve the capability of LLM in comprehending the semantics of patents. Experimental results on the PatentMatch dataset demonstrate the effectiveness of MemGraph, achieving a 17.68% performance improvement over baseline LLMs. The further analysis highlights the generalization ability of MemGraph across various LLMs, both in-domain and out-of-domain, and its capacity to enhance the internal reasoning processes of LLMs during patent matching. All data and codes are available at https://github.com/NEUIR/MemGraph.