 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen LLMs get significantly worse: A statistical approach to detect model degradations
Feb 09, 2026Minimizing the inference cost and latency of foundation models has become a crucial area of research. Optimization approaches include theoretically lossless methods and others without accuracy guarantees like quantization. In all of these cases it is crucial to ensure that the model quality has not degraded. However, even at temperature zero, model generations are not necessarily robust even to theoretically lossless model optimizations due to numerical errors. We thus require statistical tools to decide whether a finite-sample accuracy deviation is an evidence of a model's degradation or whether it can be attributed to (harmless) noise in the evaluation. We propose a statistically sound hypothesis testing framework based on McNemar's test allowing to efficiently detect model degradations, while guaranteeing a controlled rate of false positives. The crucial insight is that we have to confront the model scores on each sample, rather than aggregated on the task level. Furthermore, we propose three approaches to aggregate accuracy estimates across multiple benchmarks into a single decision. We provide an implementation on top of the largely adopted open source LM Evaluation Harness and provide a case study illustrating that the method correctly flags degraded models, while not flagging model optimizations that are provably lossless. We find that with our tests even empirical accuracy degradations of 0.3% can be confidently attributed to actual degradations rather than noise.
* https://openreview.net/forum?id=cM3gsqEI4K
XShare: Collaborative in-Batch Expert Sharing for Faster MoE Inference
Feb 06, 2026Mixture-of-Experts (MoE) architectures are increasingly used to efficiently scale large language models. However, in production inference, request batching and speculative decoding significantly amplify expert activation, eroding these efficiency benefits. We address this issue by modeling batch-aware expert selection as a modular optimization problem and designing efficient greedy algorithms for different deployment settings. The proposed method, namely XShare, requires no retraining and dynamically adapts to each batch by maximizing the total gating score of selected experts. It reduces expert activation by up to 30% under standard batching, cuts peak GPU load by up to 3x in expert-parallel deployments, and achieves up to 14% throughput gains in speculative decoding via hierarchical, correlation-aware expert selection even if requests in a batch drawn from heterogeneous datasets.
P-EAGLE: Parallel-Drafting EAGLE with Scalable Training
Feb 01, 2026Reasoning LLMs produce longer outputs, requiring speculative decoding drafters trained on extended sequences. Parallel drafting - predicting multiple tokens per forward pass - offers latency benefits over sequential generation, but training complexity scales quadratically with the product of sequence length and parallel positions, rendering long-context training impractical. We present P(arallel)-EAGLE, which transforms EAGLE from autoregressive to parallel multi-token prediction via a learnable shared hidden state. To scale training to long contexts, we develop a framework featuring attention mask pre-computation and sequence partitioning techniques, enabling gradient accumulation within individual sequences for parallel-prediction training. We implement P-EAGLE in vLLM and demonstrate speedups of 1.10-1.36x over autoregressive EAGLE-3 across GPT-OSS 120B, 20B, and Qwen3-Coder 30B.
PPLqa: An Unsupervised Information-Theoretic Quality Metric for Comparing Generative Large Language Models
Nov 22, 2024We propose PPLqa, an easy to compute, language independent, information-theoretic metric to measure the quality of responses of generative Large Language Models (LLMs) in an unsupervised way, without requiring ground truth annotations or human supervision. The method and metric enables users to rank generative language models for quality of responses, so as to make a selection of the best model for a given task. Our single metric assesses LLMs with an approach that subsumes, but is not explicitly based on, coherence and fluency (quality of writing) and relevance and consistency (appropriateness of response) to the query. PPLqa performs as well as other related metrics, and works better with long-form Q\&A. Thus, PPLqa enables bypassing the lengthy annotation process required for ground truth evaluations, and it also correlates well with human and LLM rankings.
Improving language models fine-tuning with representation consistency targets
May 23, 2022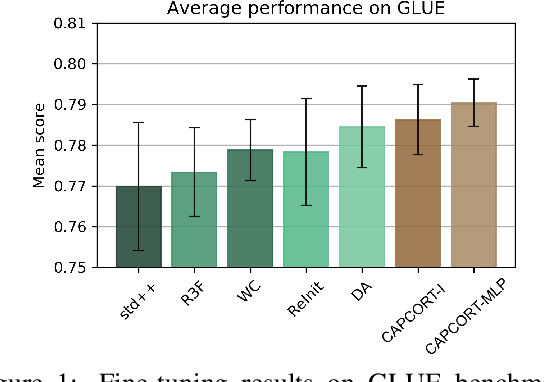
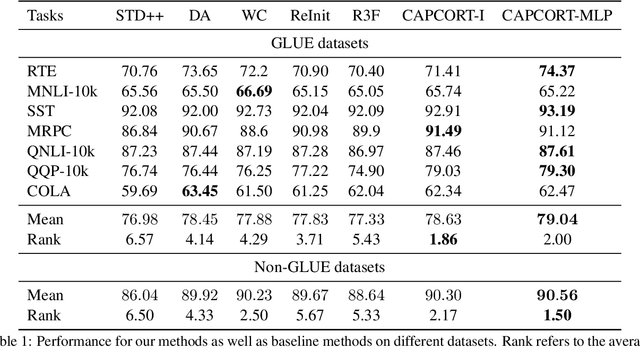
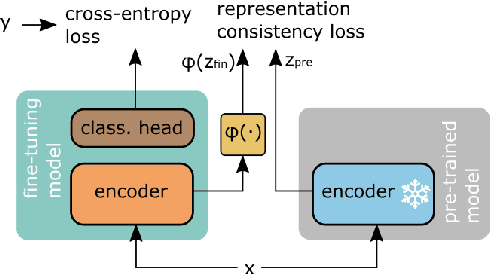
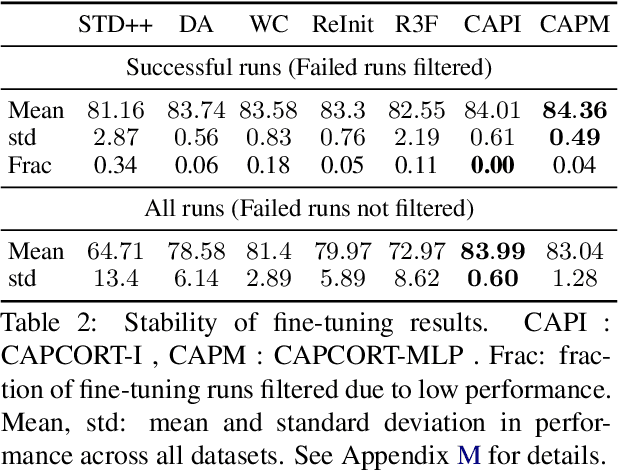
Fine-tuning contextualized representations learned by pre-trained language models has become a standard practice in the NLP field. However, pre-trained representations are prone to degradation (also known as representation collapse) during fine-tuning, which leads to instability, suboptimal performance, and weak generalization. In this paper, we propose a novel fine-tuning method that avoids representation collapse during fine-tuning by discouraging undesirable changes in the representations. We show that our approach matches or exceeds the performance of the existing regularization-based fine-tuning methods across 13 language understanding tasks (GLUE benchmark and six additional datasets). We also demonstrate its effectiveness in low-data settings and robustness to label perturbation. Furthermore, we extend previous studies of representation collapse and propose several metrics to quantify it. Using these metrics and previously proposed experiments, we show that our approach obtains significant improvements in retaining the expressive power of representations.
Pyramid-BERT: Reducing Complexity via Successive Core-set based Token Selection
Mar 27, 2022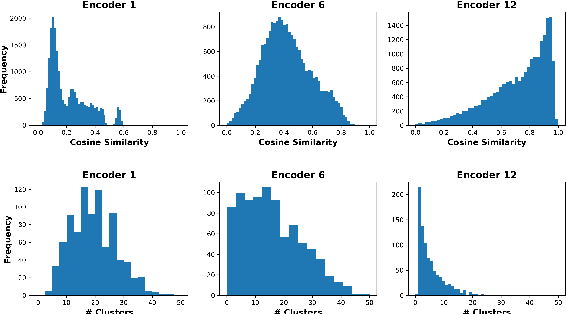
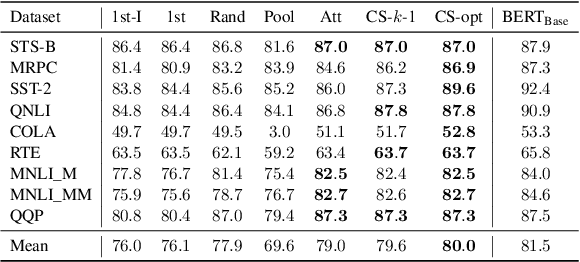
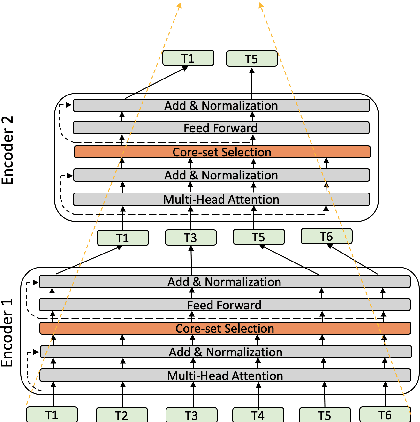
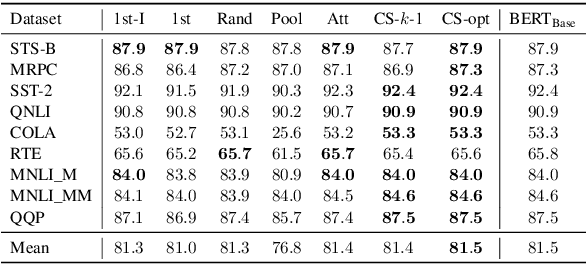
Transformer-based language models such as BERT have achieved the state-of-the-art performance on various NLP tasks, but are computationally prohibitive. A recent line of works use various heuristics to successively shorten sequence length while transforming tokens through encoders, in tasks such as classification and ranking that require a single token embedding for prediction. We present a novel solution to this problem, called Pyramid-BERT where we replace previously used heuristics with a {\em core-set} based token selection method justified by theoretical results. The core-set based token selection technique allows us to avoid expensive pre-training, gives a space-efficient fine tuning, and thus makes it suitable to handle longer sequence lengths. We provide extensive experiments establishing advantages of pyramid BERT over several baselines and existing works on the GLUE benchmarks and Long Range Arena datasets.
TabTransformer: Tabular Data Modeling Using Contextual Embeddings
Dec 11, 2020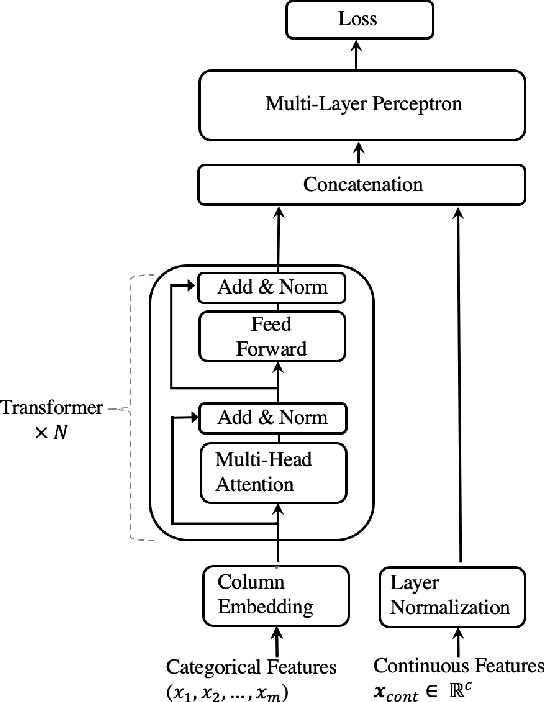
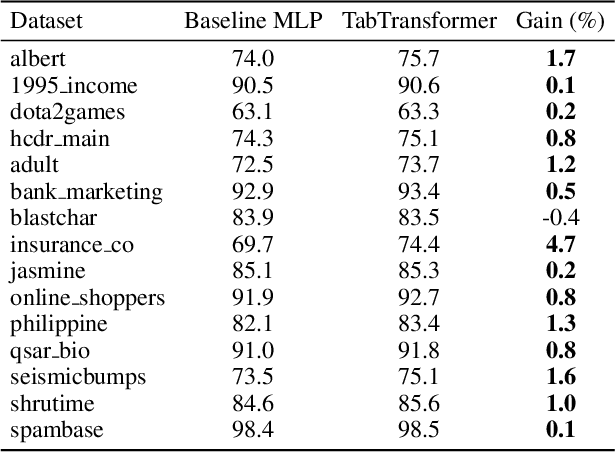
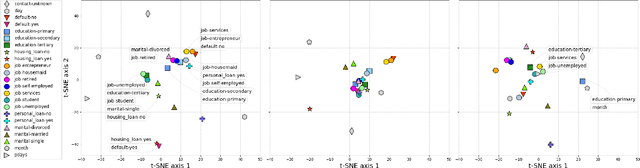
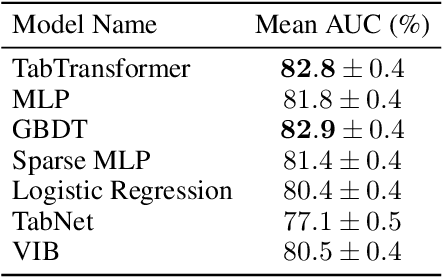
We propose TabTransformer, a novel deep tabular data modeling architecture for supervised and semi-supervised learning. The TabTransformer is built upon self-attention based Transformers. The Transformer layers transform the embeddings of categorical features into robust contextual embeddings to achieve higher prediction accuracy. Through extensive experiments on fifteen publicly available datasets, we show that the TabTransformer outperforms the state-of-the-art deep learning methods for tabular data by at least 1.0% on mean AUC, and matches the performance of tree-based ensemble models. Furthermore, we demonstrate that the contextual embeddings learned from TabTransformer are highly robust against both missing and noisy data features, and provide better interpretability. Lastly, for the semi-supervised setting we develop an unsupervised pre-training procedure to learn data-driven contextual embeddings, resulting in an average 2.1% AUC lift over the state-of-the-art methods.
PruneNet: Channel Pruning via Global Importance
May 22, 2020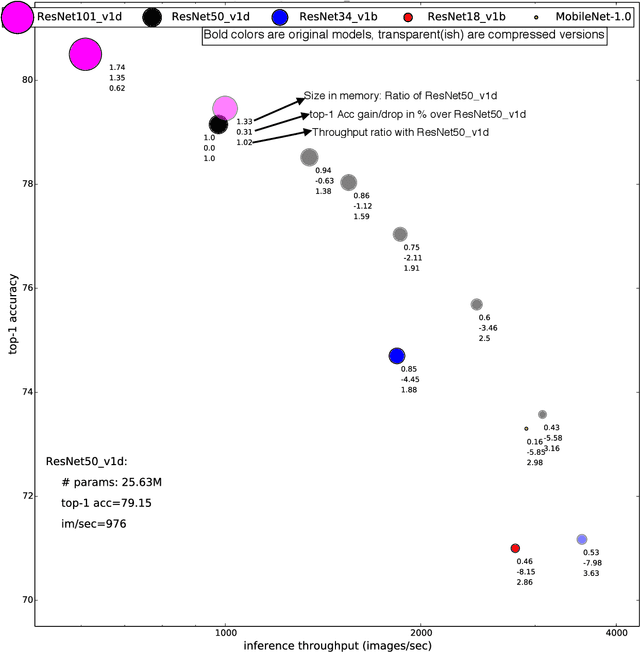
Channel pruning is one of the predominant approaches for accelerating deep neural networks. Most existing pruning methods either train from scratch with a sparsity inducing term such as group lasso, or prune redundant channels in a pretrained network and then fine tune the network. Both strategies suffer from some limitations: the use of group lasso is computationally expensive, difficult to converge and often suffers from worse behavior due to the regularization bias. The methods that start with a pretrained network either prune channels uniformly across the layers or prune channels based on the basic statistics of the network parameters. These approaches either ignore the fact that some CNN layers are more redundant than others or fail to adequately identify the level of redundancy in different layers. In this work, we investigate a simple-yet-effective method for pruning channels based on a computationally light-weight yet effective data driven optimization step that discovers the necessary width per layer. Experiments conducted on ILSVRC-$12$ confirm effectiveness of our approach. With non-uniform pruning across the layers on ResNet-$50$, we are able to match the FLOP reduction of state-of-the-art channel pruning results while achieving a $0.98\%$ higher accuracy. Further, we show that our pruned ResNet-$50$ network outperforms ResNet-$34$ and ResNet-$18$ networks, and that our pruned ResNet-$101$ outperforms ResNet-$50$.
schuBERT: Optimizing Elements of BERT
May 09, 2020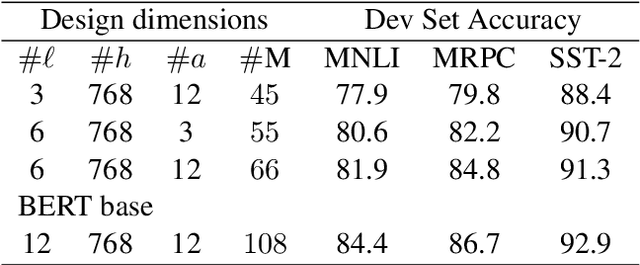
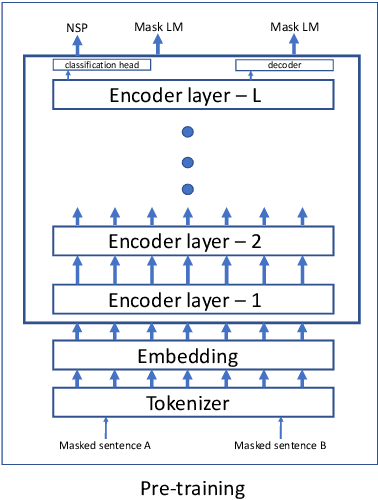
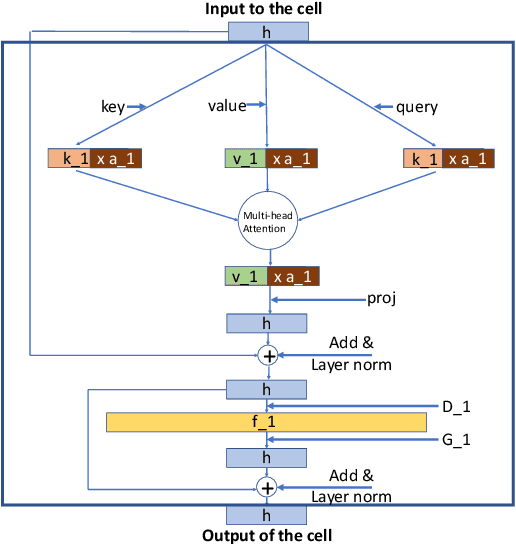
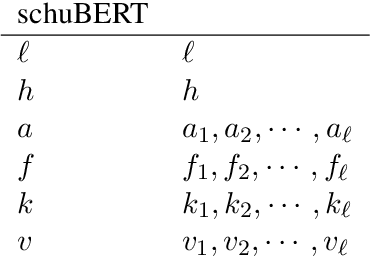
Transformers \citep{vaswani2017attention} have gradually become a key component for many state-of-the-art natural language representation models. A recent Transformer based model- BERT \citep{devlin2018bert} achieved state-of-the-art results on various natural language processing tasks, including GLUE, SQuAD v1.1, and SQuAD v2.0. This model however is computationally prohibitive and has a huge number of parameters. In this work we revisit the architecture choices of BERT in efforts to obtain a lighter model. We focus on reducing the number of parameters yet our methods can be applied towards other objectives such FLOPs or latency. We show that much efficient light BERT models can be obtained by reducing algorithmically chosen correct architecture design dimensions rather than reducing the number of Transformer encoder layers. In particular, our schuBERT gives $6.6\%$ higher average accuracy on GLUE and SQuAD datasets as compared to BERT with three encoder layers while having the same number of parameters.
Robust conditional GANs under missing or uncertain labels
Jun 09, 2019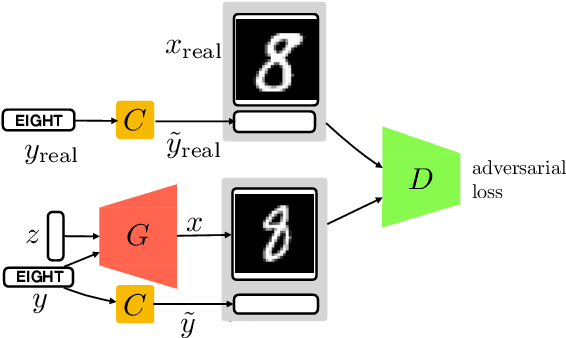

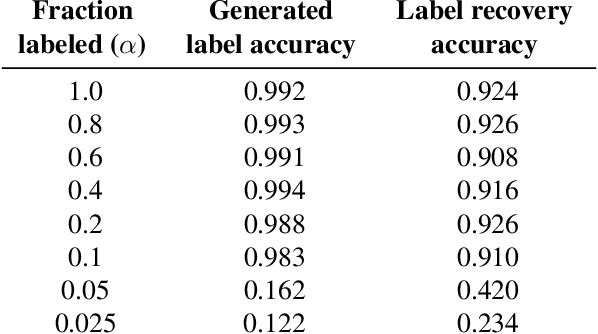

Matching the performance of conditional Generative Adversarial Networks with little supervision is an important task, especially in venturing into new domains. We design a new training algorithm, which is robust to missing or ambiguous labels. The main idea is to intentionally corrupt the labels of generated examples to match the statistics of the real data, and have a discriminator process the real and generated examples with corrupted labels. We showcase the robustness of this proposed approach both theoretically and empirically. We show that minimizing the proposed loss is equivalent to minimizing true divergence between real and generated data up to a multiplicative factor, and characterize this multiplicative factor as a function of the statistics of the uncertain labels. Experiments on MNIST dataset demonstrates that proposed architecture is able to achieve high accuracy in generating examples faithful to the class even with only a few examples per class.