 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrug Synergy Prediction via Residual Graph Isomorphism Networks and Attention Mechanisms
Apr 23, 2026In the treatment of complex diseases, treatment regimens using a single drug often yield limited efficacy and can lead to drug resistance. In contrast, combination drug therapies can significantly improve therapeutic outcomes through synergistic effects. However, experimentally validating all possible drug combinations is prohibitively expensive, underscoring the critical need for efficient computational prediction methods. Although existing approaches based on deep learning and graph neural networks (GNNs) have made considerable progress, challenges remain in reducing structural bias, improving generalization capability, and enhancing model interpretability. To address these limitations, this paper proposes a collaborative prediction graph neural network that integrates molecular structural features and cell-line genomic profiles with drug-drug interactions to enhance the prediction of synergistic effects. We introduce a novel model named the Residual Graph Isomorphism Network integrated with an Attention mechanism (ResGIN-Att). The model first extracts multi scale topological features of drug molecules using a residual graph isomorphism network, where residual connections help mitigate over-smoothing in deep layers. Subsequently, an adaptive Long Short-Term Memory (LSTM) module fuses structural information from local to global scales. Finally, a cross-attention module is designed to explicitly model drug-drug interactions and identify key chemical substructures. Extensive experiments on five public benchmark datasets demonstrate that ResGIN-Att achieves competitive performance, comparing favorably against key baseline methods while exhibiting promising generalization capability and robustness.
Evaluation-driven Scaling for Scientific Discovery
Apr 21, 2026Language models are increasingly used in scientific discovery to generate hypotheses, propose candidate solutions, implement systems, and iteratively refine them. At the core of these trial-and-error loops lies evaluation: the process of obtaining feedback on candidate solutions via verifiers, simulators, or task-specific scoring functions. While prior work has highlighted the importance of evaluation, it has not explicitly formulated the problem of how evaluation-driven discovery loops can be scaled up in a principled and effective manner to push the boundaries of scientific discovery, a problem this paper seeks to address. We introduce Simple Test-time Evaluation-driven Scaling (SimpleTES), a general framework that strategically combines parallel exploration, feedback-driven refinement, and local selection, revealing substantial gains unlocked by scaling evaluation-driven discovery loops along the right dimensions. Across 21 scientific problems spanning six domains, SimpleTES discovers state-of-the-art solutions using gpt-oss models, consistently outperforming both frontier-model baselines and sophisticated optimization pipelines. Particularly, we sped up the widely used LASSO algorithm by over 2x, designed quantum circuit routing policies that reduce gate overhead by 24.5%, and discovered new Erdos minimum overlap constructions that surpass the best-known results. Beyond novel discoveries, SimpleTES produces trajectory-level histories that naturally supervise feedback-driven learning. When post-trained on successful trajectories, models not only improve efficiency on seen problems but also generalize to unseen problems, discovering solutions that base models fail to uncover. Together, our results establish effective evaluation-driven loop scaling as a central axis for advancing LLM-driven scientific discovery, and provide a simple yet practical framework for realizing these gains.
EndoIR: Degradation-Agnostic All-in-One Endoscopic Image Restoration via Noise-Aware Routing Diffusion
Nov 11, 2025Endoscopic images often suffer from diverse and co-occurring degradations such as low lighting, smoke, and bleeding, which obscure critical clinical details. Existing restoration methods are typically task-specific and often require prior knowledge of the degradation type, limiting their robustness in real-world clinical use. We propose EndoIR, an all-in-one, degradation-agnostic diffusion-based framework that restores multiple degradation types using a single model. EndoIR introduces a Dual-Domain Prompter that extracts joint spatial-frequency features, coupled with an adaptive embedding that encodes both shared and task-specific cues as conditioning for denoising. To mitigate feature confusion in conventional concatenation-based conditioning, we design a Dual-Stream Diffusion architecture that processes clean and degraded inputs separately, with a Rectified Fusion Block integrating them in a structured, degradation-aware manner. Furthermore, Noise-Aware Routing Block improves efficiency by dynamically selecting only noise-relevant features during denoising. Experiments on SegSTRONG-C and CEC datasets demonstrate that EndoIR achieves state-of-the-art performance across multiple degradation scenarios while using fewer parameters than strong baselines, and downstream segmentation experiments confirm its clinical utility.
Fully Bayesian Analysis of the Relevance Vector Machine Classification for Imbalanced Data
Jul 26, 2020
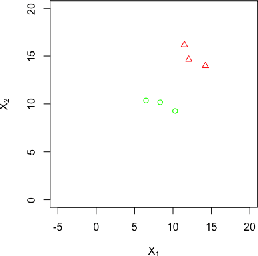
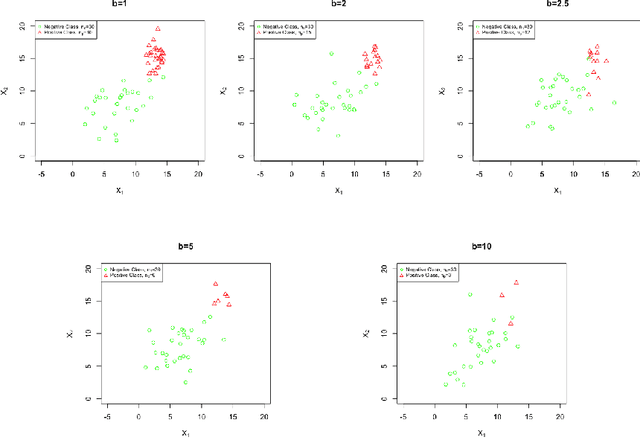
Relevance Vector Machine (RVM) is a supervised learning algorithm extended from Support Vector Machine (SVM) based on the Bayesian sparsity model. Compared with the regression problem, RVM classification is difficult to be conducted because there is no closed-form solution for the weight parameter posterior. Original RVM classification algorithm used Newton's method in optimization to obtain the mode of weight parameter posterior then approximated it by a Gaussian distribution in Laplace's method. It would work but just applied the frequency methods in a Bayesian framework. This paper proposes a Generic Bayesian approach for the RVM classification. We conjecture that our algorithm achieves convergent estimates of the quantities of interest compared with the nonconvergent estimates of the original RVM classification algorithm. Furthermore, a Fully Bayesian approach with the hierarchical hyperprior structure for RVM classification is proposed, which improves the classification performance, especially in the imbalanced data problem. By the numeric studies, our proposed algorithms obtain high classification accuracy rates. The Fully Bayesian hierarchical hyperprior method outperforms the Generic one for the imbalanced data classification.