 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Memory Compression for Efficient Multi-Agent Debate
Jan 31, 2026Multi-agent debate can improve reasoning quality and reduce hallucinations, but it incurs rapidly growing context as debate rounds and agent count increase. Retaining full textual histories leads to token usage that can exceed context limits and often requires repeated summarization, adding overhead and compounding information loss. We introduce DebateOCR, a cross-modal compression framework that replaces long textual debate traces with compact image representations, which are then consumed through a dedicated vision encoder to condition subsequent rounds. This design compresses histories that commonly span tens to hundreds of thousands of tokens, cutting input tokens by more than 92% and yielding substantially lower compute cost and faster inference across multiple benchmarks. We further provide a theoretical perspective showing that diversity across agents supports recovery of omitted information: although any single compressed history may discard details, aggregating multiple agents' compressed views allows the collective representation to approach the information bottleneck with exponentially high probability.
From nuclear safety to LLM security: Applying non-probabilistic risk management strategies to build safe and secure LLM-powered systems
May 20, 2025Large language models (LLMs) offer unprecedented and growing capabilities, but also introduce complex safety and security challenges that resist conventional risk management. While conventional probabilistic risk analysis (PRA) requires exhaustive risk enumeration and quantification, the novelty and complexity of these systems make PRA impractical, particularly against adaptive adversaries. Previous research found that risk management in various fields of engineering such as nuclear or civil engineering is often solved by generic (i.e. field-agnostic) strategies such as event tree analysis or robust designs. Here we show how emerging risks in LLM-powered systems could be met with 100+ of these non-probabilistic strategies to risk management, including risks from adaptive adversaries. The strategies are divided into five categories and are mapped to LLM security (and AI safety more broadly). We also present an LLM-powered workflow for applying these strategies and other workflows suitable for solution architects. Overall, these strategies could contribute (despite some limitations) to security, safety and other dimensions of responsible AI.
Risk-reducing design and operations toolkit: 90 strategies for managing risk and uncertainty in decision problems
Sep 06, 2023Uncertainty is a pervasive challenge in decision analysis, and decision theory recognizes two classes of solutions: probabilistic models and cognitive heuristics. However, engineers, public planners and other decision-makers instead use a third class of strategies that could be called RDOT (Risk-reducing Design and Operations Toolkit). These include incorporating robustness into designs, contingency planning, and others that do not fall into the categories of probabilistic models or cognitive heuristics. Moreover, identical strategies appear in several domains and disciplines, pointing to an important shared toolkit. The focus of this paper is to develop a catalog of such strategies and develop a framework for them. The paper finds more than 90 examples of such strategies falling into six broad categories and argues that they provide an efficient response to decision problems that are seemingly intractable due to high uncertainty. It then proposes a framework to incorporate them into decision theory using multi-objective optimization. Overall, RDOT represents an overlooked class of responses to uncertainty. Because RDOT strategies do not depend on accurate forecasting or estimation, they could be applied fruitfully to certain decision problems affected by high uncertainty and make them much more tractable.
On solving decision and risk management problems subject to uncertainty
Jan 18, 2023Uncertainty is a pervasive challenge in decision and risk management and it is usually studied by quantification and modeling. Interestingly, engineers and other decision makers usually manage uncertainty with strategies such as incorporating robustness, or by employing decision heuristics. The focus of this paper is then to develop a systematic understanding of such strategies, determine their range of application, and develop a framework to better employ them. Based on a review of a dataset of 100 decision problems, this paper found that many decision problems have pivotal properties, i.e. properties that enable solution strategies, and finds 14 such properties. Therefore, an analyst can first find these properties in a given problem, and then utilize the strategies they enable. Multi-objective optimization methods could be used to make investment decisions quantitatively. The analytical complexity of decision problems can also be scored by evaluating how many of the pivotal properties are available. Overall, we find that in the light of pivotal properties, complex problems under uncertainty frequently appear surprisingly tractable.
Using massive health insurance claims data to predict very high-cost claimants: a machine learning approach
Dec 30, 2019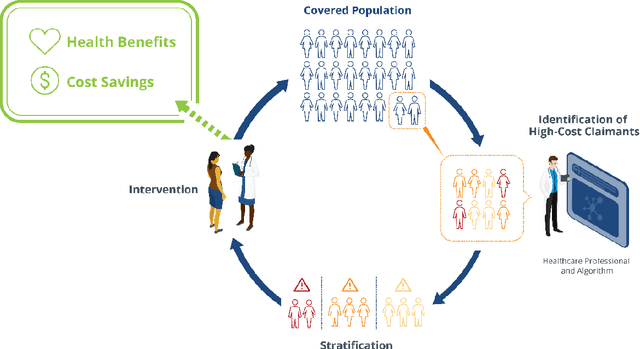
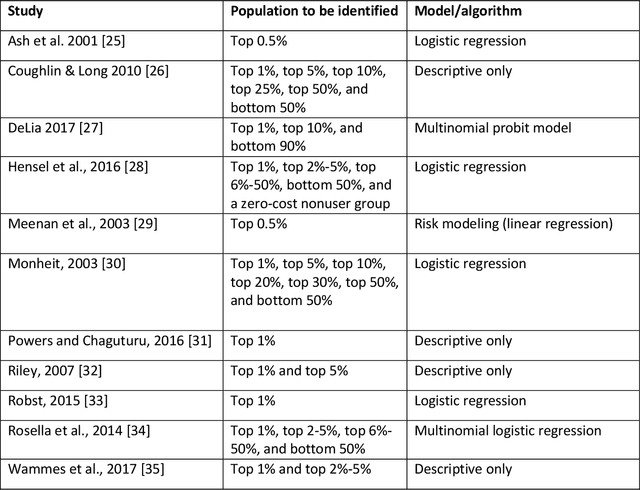
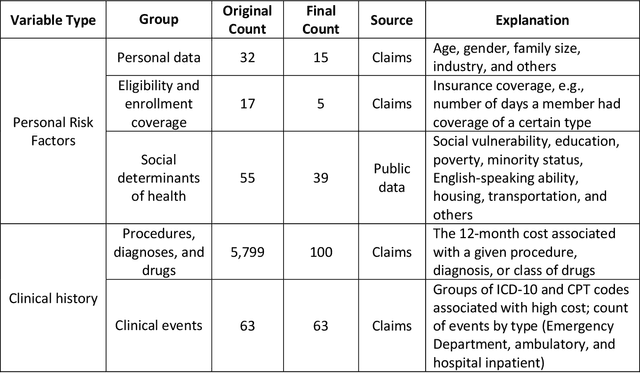
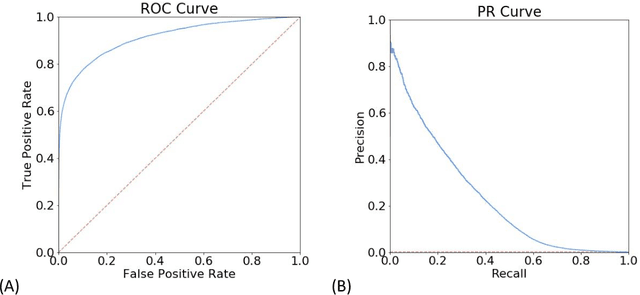
Due to escalating healthcare costs, accurately predicting which patients will incur high costs is an important task for payers and providers of healthcare. High-cost claimants (HiCCs) are patients who have annual costs above $\$250,000$ and who represent just 0.16% of the insured population but currently account for 9% of all healthcare costs. In this study, we aimed to develop a high-performance algorithm to predict HiCCs to inform a novel care management system. Using health insurance claims from 48 million people and augmented with census data, we applied machine learning to train binary classification models to calculate the personal risk of HiCC. To train the models, we developed a platform starting with 6,006 variables across all clinical and demographic dimensions and constructed over one hundred candidate models. The best model achieved an area under the receiver operating characteristic curve of 91.2%. The model exceeds the highest published performance (84%) and remains high for patients with no prior history of high-cost status (89%), who have less than a full year of enrollment (87%), or lack pharmacy claims data (88%). It attains an area under the precision-recall curve of 23.1%, and precision of 74% at a threshold of 0.99. A care management program enrolling 500 people with the highest HiCC risk is expected to treat 199 true HiCCs and generate a net savings of $\$7.3$ million per year. Our results demonstrate that high-performing predictive models can be constructed using claims data and publicly available data alone, even for rare high-cost claimants exceeding $\$250,000$. Our model demonstrates the transformational power of machine learning and artificial intelligence in care management, which would allow healthcare payers and providers to introduce the next generation of care management programs.