 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARS: Margin-Adversarial Risk-controlled Stopping for Parallel LLM Test-time Scaling
Jun 11, 2026Parallel test-time scaling samples many reasoning traces and majority-votes their answers, improving LLM accuracy but requiring traces to run to completion, incurring substantial computational overhead. We observe that probing partial traces at intermediate checkpoints can extract current answers without disrupting generation, revealing an evolving aggregate vote. Based on this observation, we introduce MARS, a margin-adversarial stopping rule that estimates which active traces are likely to change their answers and stops once the leader remains safe under a conservative bound on future vote movement. The rule separates two sources of uncertainty. It learns the trace-level switch probabilities that determine how much of the current margin is likely to be retained, while handling the harder question of where switching traces land through an adversarial bound calibrated from warmup traces. With true switch probabilities, MARS guarantees with high probability that the early-stopped answer matches the full-budget vote. In practice, a five-feature logistic model closely matches oracle switching behavior. Across three reasoning models and three competition-math benchmarks, MARS saves 25-47% of self-consistency tokens and 14-29% on top of DeepConf Online, a strong confidence-weighted baseline that already filters and truncates weak traces, while matching the accuracy of the corresponding full-budget baselines.
CAAL: Contextual Bandits based Online Hand-Craft Active Learning Strategy Selection
Jun 06, 2026The challenge with active learning algorithms is the uncertainty of the statistical distribution of unlabeled data, making it difficult to choose the best hand-crafted strategy. To address this, we introduced Contextual Adaptive Active Learning (CAAL). In CAAL, each "arm" represents a hand-crafted strategy. Unlike existing frameworks that select strategies based only on feedback from labeled data, we dynamically choose strategies for labeling batches of data using reward prediction with external context information. This general framework allows for customization with domain knowledge to design more effective rewards and context candidates. In addition, we experimentally show that CAAL outperforms the existing baseline adaptive strategy on public datasets using our reward and context design. Our results are consistent regardless of batch size in each iteration.
Cross-Modal Memory Compression for Efficient Multi-Agent Debate
Jan 31, 2026Multi-agent debate can improve reasoning quality and reduce hallucinations, but it incurs rapidly growing context as debate rounds and agent count increase. Retaining full textual histories leads to token usage that can exceed context limits and often requires repeated summarization, adding overhead and compounding information loss. We introduce DebateOCR, a cross-modal compression framework that replaces long textual debate traces with compact image representations, which are then consumed through a dedicated vision encoder to condition subsequent rounds. This design compresses histories that commonly span tens to hundreds of thousands of tokens, cutting input tokens by more than 92% and yielding substantially lower compute cost and faster inference across multiple benchmarks. We further provide a theoretical perspective showing that diversity across agents supports recovery of omitted information: although any single compressed history may discard details, aggregating multiple agents' compressed views allows the collective representation to approach the information bottleneck with exponentially high probability.
TabDeco: A Comprehensive Contrastive Framework for Decoupled Representations in Tabular Data
Nov 17, 2024



Representation learning is a fundamental aspect of modern artificial intelligence, driving substantial improvements across diverse applications. While selfsupervised contrastive learning has led to significant advancements in fields like computer vision and natural language processing, its adaptation to tabular data presents unique challenges. Traditional approaches often prioritize optimizing model architecture and loss functions but may overlook the crucial task of constructing meaningful positive and negative sample pairs from various perspectives like feature interactions, instance-level patterns and batch-specific contexts. To address these challenges, we introduce TabDeco, a novel method that leverages attention-based encoding strategies across both rows and columns and employs contrastive learning framework to effectively disentangle feature representations at multiple levels, including features, instances and data batches. With the innovative feature decoupling hierarchies, TabDeco consistently surpasses existing deep learning methods and leading gradient boosting algorithms, including XG-Boost, CatBoost, and LightGBM, across various benchmark tasks, underscoring its effectiveness in advancing tabular data representation learning.
SwitchTab: Switched Autoencoders Are Effective Tabular Learners
Jan 04, 2024



Self-supervised representation learning methods have achieved significant success in computer vision and natural language processing, where data samples exhibit explicit spatial or semantic dependencies. However, applying these methods to tabular data is challenging due to the less pronounced dependencies among data samples. In this paper, we address this limitation by introducing SwitchTab, a novel self-supervised method specifically designed to capture latent dependencies in tabular data. SwitchTab leverages an asymmetric encoder-decoder framework to decouple mutual and salient features among data pairs, resulting in more representative embeddings. These embeddings, in turn, contribute to better decision boundaries and lead to improved results in downstream tasks. To validate the effectiveness of SwitchTab, we conduct extensive experiments across various domains involving tabular data. The results showcase superior performance in end-to-end prediction tasks with fine-tuning. Moreover, we demonstrate that pre-trained salient embeddings can be utilized as plug-and-play features to enhance the performance of various traditional classification methods (e.g., Logistic Regression, XGBoost, etc.). Lastly, we highlight the capability of SwitchTab to create explainable representations through visualization of decoupled mutual and salient features in the latent space.
Semiblind subgraph reconstruction in Gaussian graphical models
Nov 15, 2017


Consider a social network where only a few nodes (agents) have meaningful interactions in the sense that the conditional dependency graph over node attribute variables (behaviors) is sparse. A company that can only observe the interactions between its own customers will generally not be able to accurately estimate its customers' dependency subgraph: it is blinded to any external interactions of its customers and this blindness creates false edges in its subgraph. In this paper we address the semiblind scenario where the company has access to a noisy summary of the complementary subgraph connecting external agents, e.g., provided by a consolidator. The proposed framework applies to other applications as well, including field estimation from a network of awake and sleeping sensors and privacy-constrained information sharing over social subnetworks. We propose a penalized likelihood approach in the context of a graph signal obeying a Gaussian graphical models (GGM). We use a convex-concave iterative optimization algorithm to maximize the penalized likelihood.
Robust training on approximated minimal-entropy set
Oct 21, 2016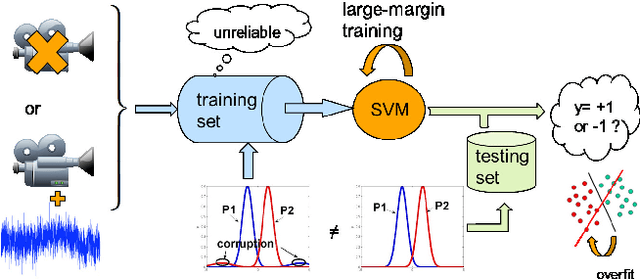
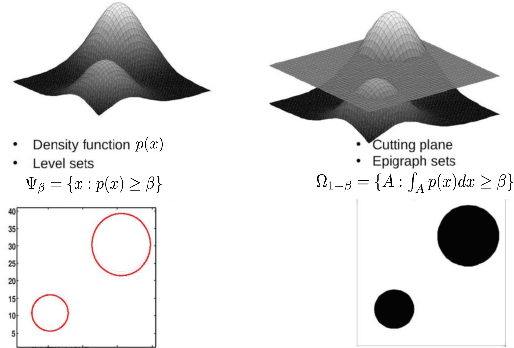
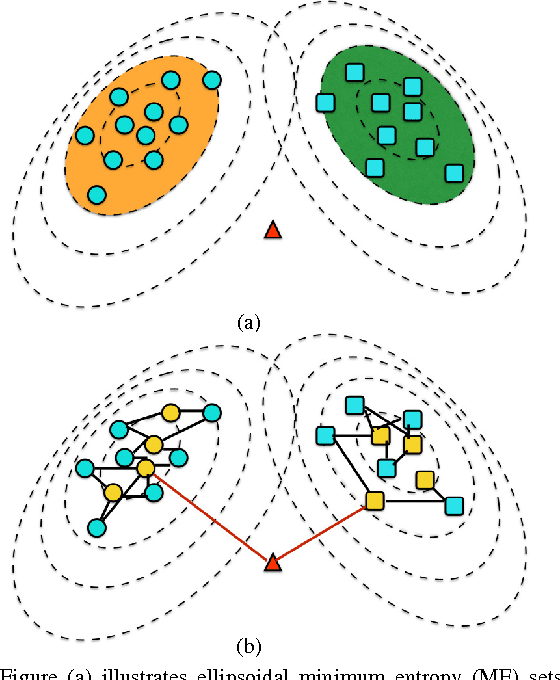

In this paper, we propose a general framework to learn a robust large-margin binary classifier when corrupt measurements, called anomalies, caused by sensor failure might be present in the training set. The goal is to minimize the generalization error of the classifier on non-corrupted measurements while controlling the false alarm rate associated with anomalous samples. By incorporating a non-parametric regularizer based on an empirical entropy estimator, we propose a Geometric-Entropy-Minimization regularized Maximum Entropy Discrimination (GEM-MED) method to learn to classify and detect anomalies in a joint manner. We demonstrate using simulated data and a real multimodal data set. Our GEM-MED method can yield improved performance over previous robust classification methods in terms of both classification accuracy and anomaly detection rate.
Learning to classify with possible sensor failures
Feb 22, 2016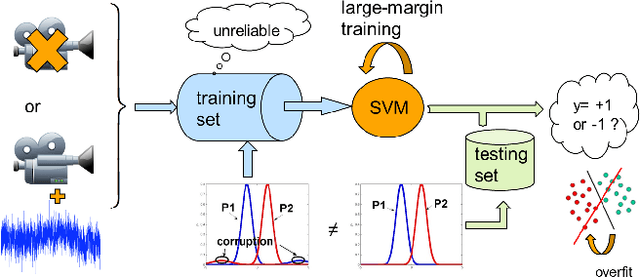
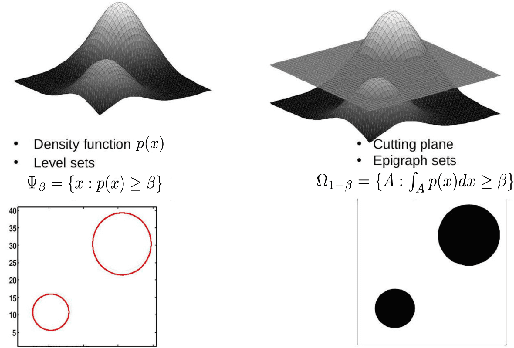
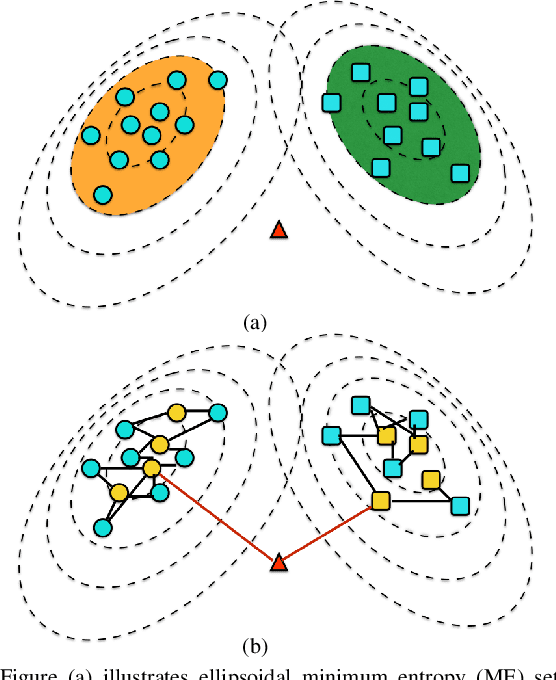
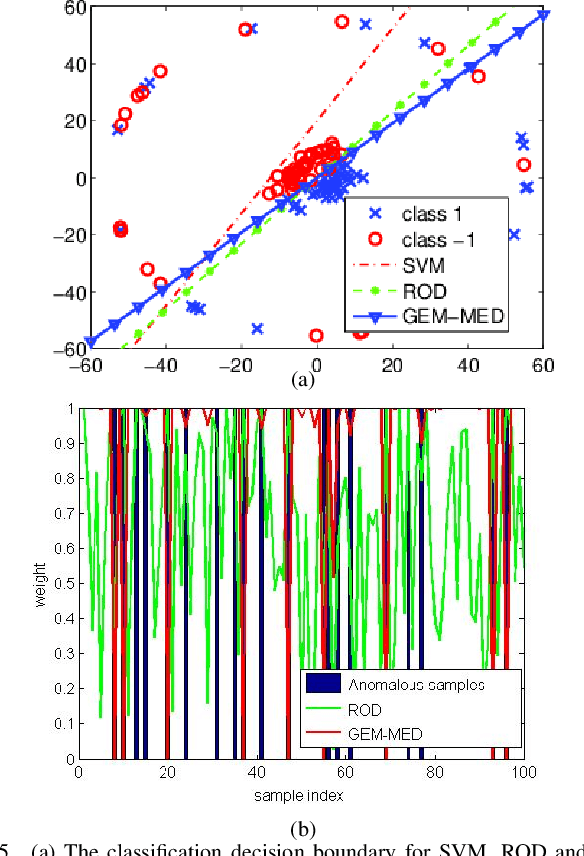
In this paper, we propose a general framework to learn a robust large-margin binary classifier when corrupt measurements, called anomalies, caused by sensor failure might be present in the training set. The goal is to minimize the generalization error of the classifier on non-corrupted measurements while controlling the false alarm rate associated with anomalous samples. By incorporating a non-parametric regularizer based on an empirical entropy estimator, we propose a Geometric-Entropy-Minimization regularized Maximum Entropy Discrimination (GEM-MED) method to learn to classify and detect anomalies in a joint manner. We demonstrate using simulated data and a real multimodal data set. Our GEM-MED method can yield improved performance over previous robust classification methods in terms of both classification accuracy and anomaly detection rate.
Semi-supervised Multi-sensor Classification via Consensus-based Multi-View Maximum Entropy Discrimination
Jul 05, 2015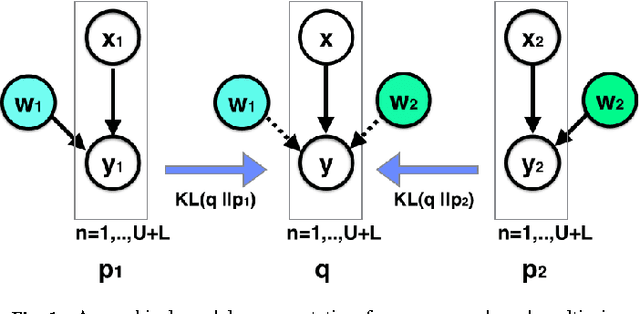

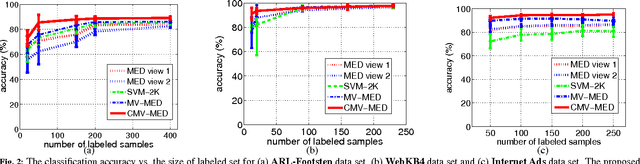
In this paper, we consider multi-sensor classification when there is a large number of unlabeled samples. The problem is formulated under the multi-view learning framework and a Consensus-based Multi-View Maximum Entropy Discrimination (CMV-MED) algorithm is proposed. By iteratively maximizing the stochastic agreement between multiple classifiers on the unlabeled dataset, the algorithm simultaneously learns multiple high accuracy classifiers. We demonstrate that our proposed method can yield improved performance over previous multi-view learning approaches by comparing performance on three real multi-sensor data sets.