 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing the Patent Matching Capability of Large Language Models via the Memory Graph
Apr 21, 2025



Intellectual Property (IP) management involves strategically protecting and utilizing intellectual assets to enhance organizational innovation, competitiveness, and value creation. Patent matching is a crucial task in intellectual property management, which facilitates the organization and utilization of patents. Existing models often rely on the emergent capabilities of Large Language Models (LLMs) and leverage them to identify related patents directly. However, these methods usually depend on matching keywords and overlook the hierarchical classification and categorical relationships of patents. In this paper, we propose MemGraph, a method that augments the patent matching capabilities of LLMs by incorporating a memory graph derived from their parametric memory. Specifically, MemGraph prompts LLMs to traverse their memory to identify relevant entities within patents, followed by attributing these entities to corresponding ontologies. After traversing the memory graph, we utilize extracted entities and ontologies to improve the capability of LLM in comprehending the semantics of patents. Experimental results on the PatentMatch dataset demonstrate the effectiveness of MemGraph, achieving a 17.68% performance improvement over baseline LLMs. The further analysis highlights the generalization ability of MemGraph across various LLMs, both in-domain and out-of-domain, and its capacity to enhance the internal reasoning processes of LLMs during patent matching. All data and codes are available at https://github.com/NEUIR/MemGraph.
Bitstream Collisions in Neural Image Compression via Adversarial Perturbations
Mar 25, 2025



Neural image compression (NIC) has emerged as a promising alternative to classical compression techniques, offering improved compression ratios. Despite its progress towards standardization and practical deployment, there has been minimal exploration into it's robustness and security. This study reveals an unexpected vulnerability in NIC - bitstream collisions - where semantically different images produce identical compressed bitstreams. Utilizing a novel whitebox adversarial attack algorithm, this paper demonstrates that adding carefully crafted perturbations to semantically different images can cause their compressed bitstreams to collide exactly. The collision vulnerability poses a threat to the practical usability of NIC, particularly in security-critical applications. The cause of the collision is analyzed, and a simple yet effective mitigation method is presented.
Assessing the Adversarial Security of Perceptual Hashing Algorithms
Jun 03, 2024



Perceptual hashing algorithms (PHAs) are utilized extensively for identifying illegal online content. Given their crucial role in sensitive applications, understanding their security strengths and weaknesses is critical. This paper compares three major PHAs deployed widely in practice: PhotoDNA, PDQ, and NeuralHash, and assesses their robustness against three typical attacks: normal image editing attacks, malicious adversarial attacks, and hash inversion attacks. Contrary to prevailing studies, this paper reveals that these PHAs exhibit resilience to black-box adversarial attacks when realistic constraints regarding the distortion and query budget are applied, attributed to the unique property of random hash variations. Moreover, this paper illustrates that original images can be reconstructed from the hash bits, raising significant privacy concerns. By comprehensively exposing their security vulnerabilities, this paper contributes to the ongoing efforts aimed at enhancing the security of PHAs for effective deployment.
Multi-Evidence based Fact Verification via A Confidential Graph Neural Network
May 17, 2024



Fact verification tasks aim to identify the integrity of textual contents according to the truthful corpus. Existing fact verification models usually build a fully connected reasoning graph, which regards claim-evidence pairs as nodes and connects them with edges. They employ the graph to propagate the semantics of the nodes. Nevertheless, the noisy nodes usually propagate their semantics via the edges of the reasoning graph, which misleads the semantic representations of other nodes and amplifies the noise signals. To mitigate the propagation of noisy semantic information, we introduce a Confidential Graph Attention Network (CO-GAT), which proposes a node masking mechanism for modeling the nodes. Specifically, CO-GAT calculates the node confidence score by estimating the relevance between the claim and evidence pieces. Then, the node masking mechanism uses the node confidence scores to control the noise information flow from the vanilla node to the other graph nodes. CO-GAT achieves a 73.59% FEVER score on the FEVER dataset and shows the generalization ability by broadening the effectiveness to the science-specific domain.
Text Matching Improves Sequential Recommendation by Reducing Popularity Biases
Aug 27, 2023



This paper proposes Text mAtching based SequenTial rEcommendation model (TASTE), which maps items and users in an embedding space and recommends items by matching their text representations. TASTE verbalizes items and user-item interactions using identifiers and attributes of items. To better characterize user behaviors, TASTE additionally proposes an attention sparsity method, which enables TASTE to model longer user-item interactions by reducing the self-attention computations during encoding. Our experiments show that TASTE outperforms the state-of-the-art methods on widely used sequential recommendation datasets. TASTE alleviates the cold start problem by representing long-tail items using full-text modeling and bringing the benefits of pretrained language models to recommendation systems. Our further analyses illustrate that TASTE significantly improves the recommendation accuracy by reducing the popularity bias of previous item id based recommendation models and returning more appropriate and text-relevant items to satisfy users. All codes are available at https://github.com/OpenMatch/TASTE.
Dimension Reduction for Efficient Dense Retrieval via Conditional Autoencoder
May 06, 2022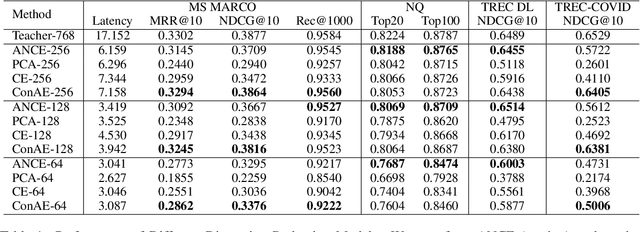
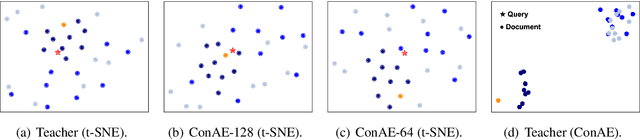
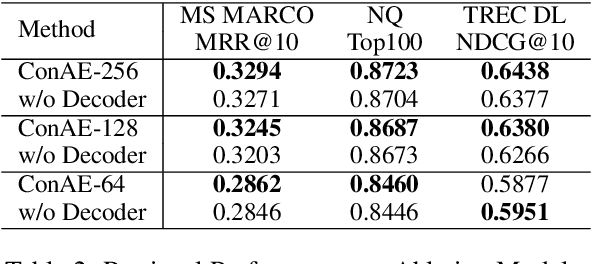
Dense retrievers encode texts and map them in an embedding space using pre-trained language models. These embeddings are critical to keep high-dimensional for effectively training dense retrievers, but lead to a high cost of storing index and retrieval. To reduce the embedding dimensions of dense retrieval, this paper proposes a Conditional Autoencoder (ConAE) to compress the high-dimensional embeddings to maintain the same embedding distribution and better recover the ranking features. Our experiments show the effectiveness of ConAE in compressing embeddings by achieving comparable ranking performance with the raw ones, making the retrieval system more efficient. Our further analyses show that ConAE can mitigate the redundancy of the embeddings of dense retrieval with only one linear layer. All codes of this work are available at https://github.com/NEUIR/ConAE.
Mitigating Black-Box Adversarial Attacks via Output Noise Perturbation
Sep 30, 2021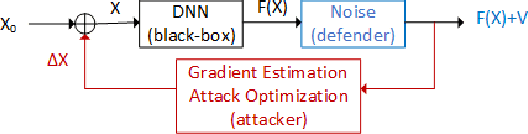

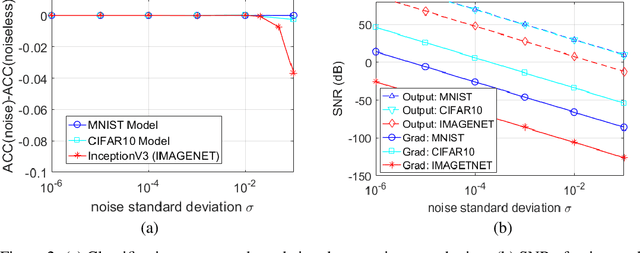
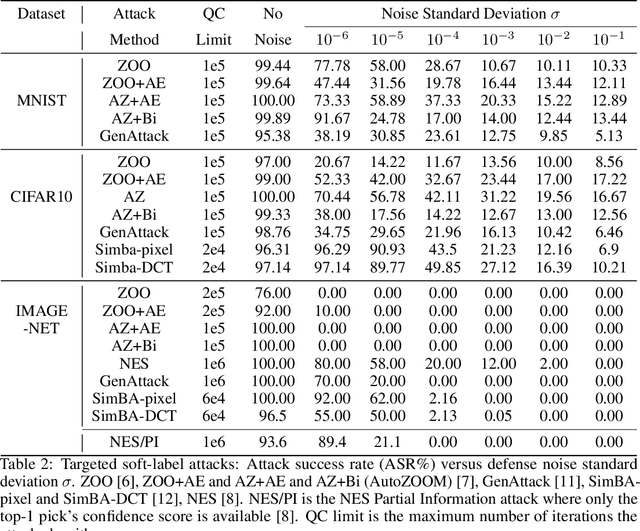
In black-box adversarial attacks, adversaries query the deep neural network (DNN), use the output to reconstruct gradients, and then optimize the adversarial inputs iteratively. In this paper, we study the method of adding white noise to the DNN output to mitigate such attacks, with a unique focus on the trade-off analysis of noise level and query cost. The attacker's query count (QC) is derived mathematically as a function of noise standard deviation. With this result, the defender can conveniently find the noise level needed to mitigate attacks for the desired security level specified by QC and limited DNN performance loss. Our analysis shows that the added noise is drastically magnified by the small variation of DNN outputs, which makes the reconstructed gradient have an extremely low signal-to-noise ratio (SNR). Adding slight white noise with a standard deviation less than 0.01 is enough to increase QC by many orders of magnitude without introducing any noticeable classification accuracy reduction. Our experiments demonstrate that this method can effectively mitigate both soft-label and hard-label black-box attacks under realistic QC constraints. We also show that this method outperforms many other defense methods and is robust to the attacker's countermeasures.
TPPI-Net: Towards Efficient and Practical Hyperspectral Image Classification
Mar 18, 2021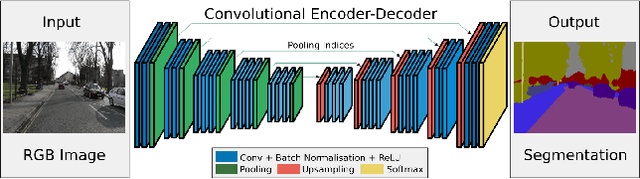
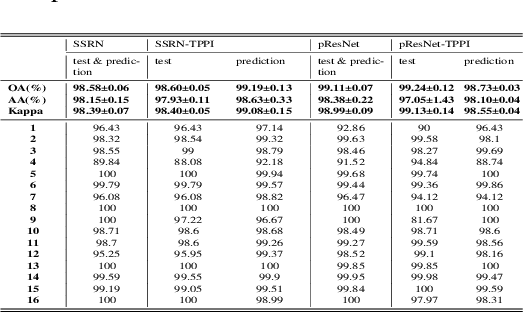
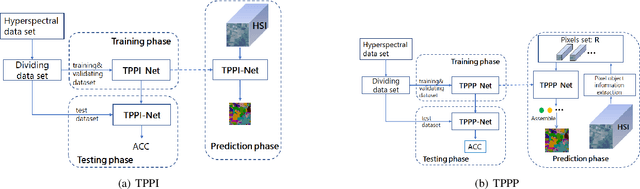
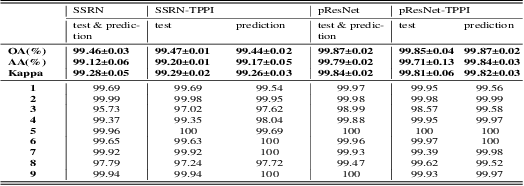
Hyperspectral Image(HSI) classification is the most vibrant field of research in the hyperspectral community, which aims to assign each pixel in the image to one certain category based on its spectral-spatial characteristics. Recently, some spectral-spatial-feature based DCNNs have been proposed and demonstrated remarkable classification performance. When facing a real HSI, however, these Networks have to deal with the pixels in the image one by one. The pixel-wise processing strategy is inefficient since there are numerous repeated calculations between adjacent pixels. In this paper, firstly, a brand new Network design mechanism TPPI (training based on pixel and prediction based on image) is proposed for HSI classification, which makes it possible to provide efficient and practical HSI classification with the restrictive conditions attached to the hyperspectral dataset. And then, according to the TPPI mechanism, TPPI-Net is derived based on the state of the art networks for HSI classification. Experimental results show that the proposed TPPI-Net can not only obtain high classification accuracy equivalent to the state of the art networks for HSI classification, but also greatly reduce the computational complexity of hyperspectral image prediction.
A Spike Learning System for Event-driven Object Recognition
Jan 21, 2021

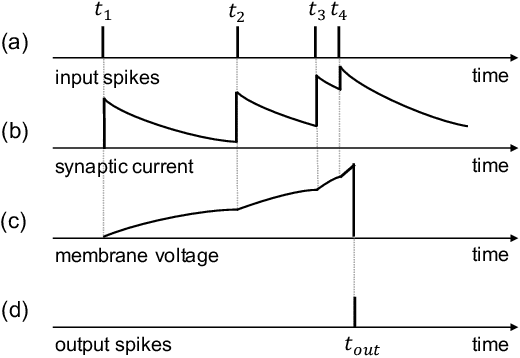
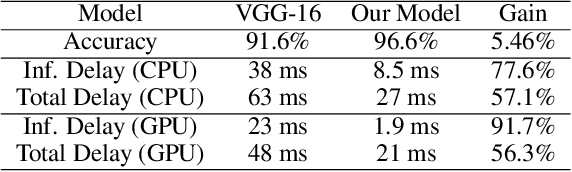
Event-driven sensors such as LiDAR and dynamic vision sensor (DVS) have found increased attention in high-resolution and high-speed applications. A lot of work has been conducted to enhance recognition accuracy. However, the essential topic of recognition delay or time efficiency is largely under-explored. In this paper, we present a spiking learning system that uses the spiking neural network (SNN) with a novel temporal coding for accurate and fast object recognition. The proposed temporal coding scheme maps each event's arrival time and data into SNN spike time so that asynchronously-arrived events are processed immediately without delay. The scheme is integrated nicely with the SNN's asynchronous processing capability to enhance time efficiency. A key advantage over existing systems is that the event accumulation time for each recognition task is determined automatically by the system rather than pre-set by the user. The system can finish recognition early without waiting for all the input events. Extensive experiments were conducted over a list of 7 LiDAR and DVS datasets. The results demonstrated that the proposed system had state-of-the-art recognition accuracy while achieving remarkable time efficiency. Recognition delay was shown to reduce by 56.3% to 91.7% in various experiment settings over the popular KITTI dataset.
Spiking Neural Networks with Single-Spike Temporal-Coded Neurons for Network Intrusion Detection
Oct 15, 2020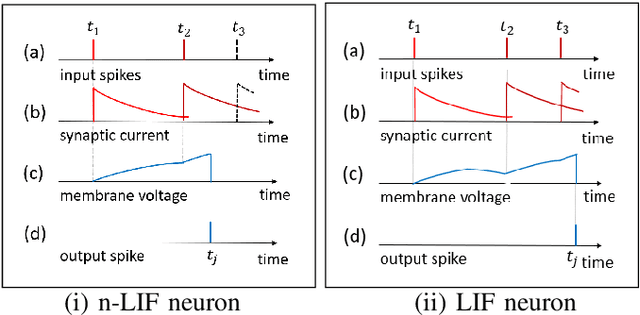
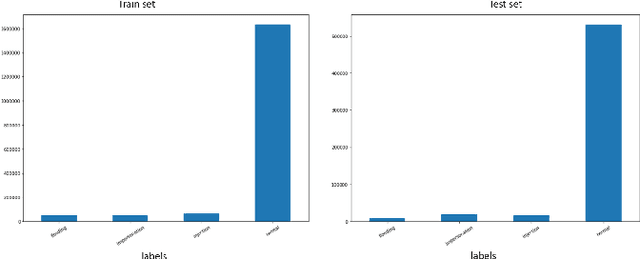
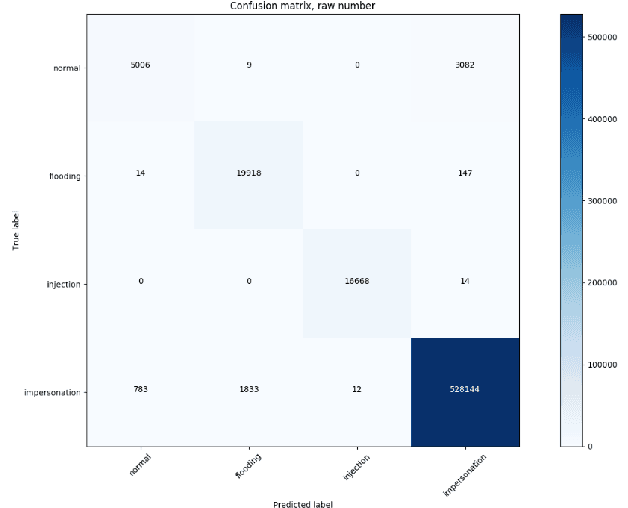

Spiking neural network (SNN) is interesting due to its strong bio-plausibility and high energy efficiency. However, its performance is falling far behind conventional deep neural networks (DNNs). In this paper, considering a general class of single-spike temporal-coded integrate-and-fire neurons, we analyze the input-output expressions of both leaky and nonleaky neurons. We show that SNNs built with leaky neurons suffer from the overly-nonlinear and overly-complex input-output response, which is the major reason for their difficult training and low performance. This reason is more fundamental than the commonly believed problem of nondifferentiable spikes. To support this claim, we show that SNNs built with nonleaky neurons can have a less-complex and less-nonlinear input-output response. They can be easily trained and can have superior performance, which is demonstrated by experimenting with the SNNs over two popular network intrusion detection datasets, i.e., the NSL-KDD and the AWID datasets. Our experiment results show that the proposed SNNs outperform a comprehensive list of DNN models and classic machine learning models. This paper demonstrates that SNNs can be promising and competitive in contrast to common beliefs.
* Published in the 25th International Conference on Pattern Recognition (ICPR'2020), January 2021