 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefining Context-Entangled Content Segmentation via Curriculum Selection and Anti-Curriculum Promotion
Feb 01, 2026Biological learning proceeds from easy to difficult tasks, gradually reinforcing perception and robustness. Inspired by this principle, we address Context-Entangled Content Segmentation (CECS), a challenging setting where objects share intrinsic visual patterns with their surroundings, as in camouflaged object detection. Conventional segmentation networks predominantly rely on architectural enhancements but often ignore the learning dynamics that govern robustness under entangled data distributions. We introduce CurriSeg, a dual-phase learning framework that unifies curriculum and anti-curriculum principles to improve representation reliability. In the Curriculum Selection phase, CurriSeg dynamically selects training data based on the temporal statistics of sample losses, distinguishing hard-but-informative samples from noisy or ambiguous ones, thus enabling stable capability enhancement. In the Anti-Curriculum Promotion phase, we design Spectral-Blindness Fine-Tuning, which suppresses high-frequency components to enforce dependence on low-frequency structural and contextual cues and thus strengthens generalization. Extensive experiments demonstrate that CurriSeg achieves consistent improvements across diverse CECS benchmarks without adding parameters or increasing total training time, offering a principled view of how progression and challenge interplay to foster robust and context-aware segmentation. Code will be released.
HiFi-Mesh: High-Fidelity Efficient 3D Mesh Generation via Compact Autoregressive Dependence
Jan 29, 2026High-fidelity 3D meshes can be tokenized into one-dimension (1D) sequences and directly modeled using autoregressive approaches for faces and vertices. However, existing methods suffer from insufficient resource utilization, resulting in slow inference and the ability to handle only small-scale sequences, which severely constrains the expressible structural details. We introduce the Latent Autoregressive Network (LANE), which incorporates compact autoregressive dependencies in the generation process, achieving a $6\times$ improvement in maximum generatable sequence length compared to existing methods. To further accelerate inference, we propose the Adaptive Computation Graph Reconfiguration (AdaGraph) strategy, which effectively overcomes the efficiency bottleneck of traditional serial inference through spatiotemporal decoupling in the generation process. Experimental validation demonstrates that LANE achieves superior performance across generation speed, structural detail, and geometric consistency, providing an effective solution for high-quality 3D mesh generation.
ProMotion: Prototypes As Motion Learners
Jun 07, 2024



In this work, we introduce ProMotion, a unified prototypical framework engineered to model fundamental motion tasks. ProMotion offers a range of compelling attributes that set it apart from current task-specific paradigms. We adopt a prototypical perspective, establishing a unified paradigm that harmonizes disparate motion learning approaches. This novel paradigm streamlines the architectural design, enabling the simultaneous assimilation of diverse motion information. We capitalize on a dual mechanism involving the feature denoiser and the prototypical learner to decipher the intricacies of motion. This approach effectively circumvents the pitfalls of ambiguity in pixel-wise feature matching, significantly bolstering the robustness of motion representation. We demonstrate a profound degree of transferability across distinct motion patterns. This inherent versatility reverberates robustly across a comprehensive spectrum of both 2D and 3D downstream tasks. Empirical results demonstrate that ProMotion outperforms various well-known specialized architectures, achieving 0.54 and 0.054 Abs Rel error on the Sintel and KITTI depth datasets, 1.04 and 2.01 average endpoint error on the clean and final pass of Sintel flow benchmark, and 4.30 F1-all error on the KITTI flow benchmark. For its efficacy, we hope our work can catalyze a paradigm shift in universal models in computer vision.
Prototypical Transformer as Unified Motion Learners
Jun 03, 2024



In this work, we introduce the Prototypical Transformer (ProtoFormer), a general and unified framework that approaches various motion tasks from a prototype perspective. ProtoFormer seamlessly integrates prototype learning with Transformer by thoughtfully considering motion dynamics, introducing two innovative designs. First, Cross-Attention Prototyping discovers prototypes based on signature motion patterns, providing transparency in understanding motion scenes. Second, Latent Synchronization guides feature representation learning via prototypes, effectively mitigating the problem of motion uncertainty. Empirical results demonstrate that our approach achieves competitive performance on popular motion tasks such as optical flow and scene depth. Furthermore, it exhibits generality across various downstream tasks, including object tracking and video stabilization.
A Data Perspective on Enhanced Identity Preservation for Diffusion Personalization
Nov 07, 2023



Large text-to-image models have revolutionized the ability to generate imagery using natural language. However, particularly unique or personal visual concepts, such as your pet, an object in your house, etc., will not be captured by the original model. This has led to interest in how to inject new visual concepts, bound to a new text token, using as few as 4-6 examples. Despite significant progress, this task remains a formidable challenge, particularly in preserving the subject's identity. While most researchers attempt to to address this issue by modifying model architectures, our approach takes a data-centric perspective, advocating the modification of data rather than the model itself. We introduce a novel regularization dataset generation strategy on both the text and image level; demonstrating the importance of a rich and structured regularization dataset (automatically generated) to prevent losing text coherence and better identity preservation. The better quality is enabled by allowing up to 5x more fine-tuning iterations without overfitting and degeneration. The generated renditions of the desired subject preserve even fine details such as text and logos; all while maintaining the ability to generate diverse samples that follow the input text prompt. Since our method focuses on data augmentation, rather than adjusting the model architecture, it is complementary and can be combined with prior work. We show on established benchmarks that our data-centric approach forms the new state of the art in terms of image quality, with the best trade-off between identity preservation, diversity, and text alignment.
E^2VPT: An Effective and Efficient Approach for Visual Prompt Tuning
Jul 25, 2023As the size of transformer-based models continues to grow, fine-tuning these large-scale pretrained vision models for new tasks has become increasingly parameter-intensive. Parameter-efficient learning has been developed to reduce the number of tunable parameters during fine-tuning. Although these methods show promising results, there is still a significant performance gap compared to full fine-tuning. To address this challenge, we propose an Effective and Efficient Visual Prompt Tuning (E^2VPT) approach for large-scale transformer-based model adaptation. Specifically, we introduce a set of learnable key-value prompts and visual prompts into self-attention and input layers, respectively, to improve the effectiveness of model fine-tuning. Moreover, we design a prompt pruning procedure to systematically prune low importance prompts while preserving model performance, which largely enhances the model's efficiency. Empirical results demonstrate that our approach outperforms several state-of-the-art baselines on two benchmarks, with considerably low parameter usage (e.g., 0.32% of model parameters on VTAB-1k). Our code is available at https://github.com/ChengHan111/E2VPT.
Towards Unbiased Label Distribution Learning for Facial Pose Estimation Using Anisotropic Spherical Gaussian
Aug 19, 2022
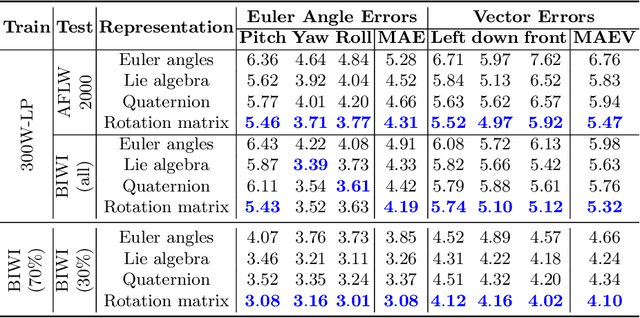
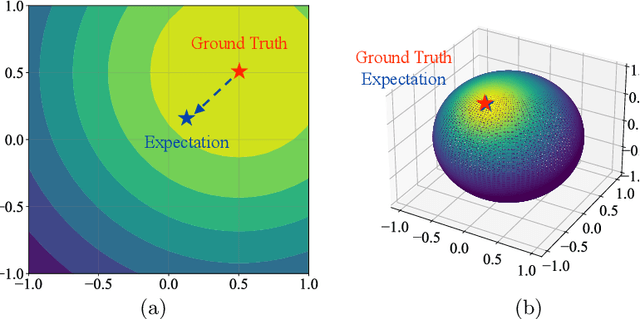
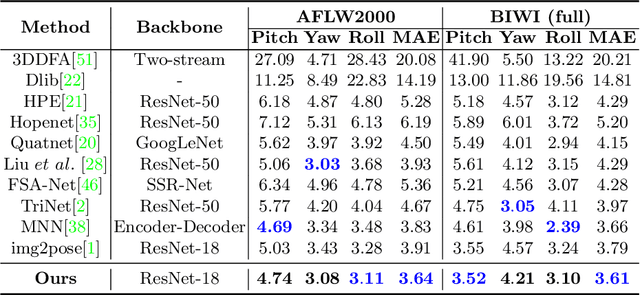
Facial pose estimation refers to the task of predicting face orientation from a single RGB image. It is an important research topic with a wide range of applications in computer vision. Label distribution learning (LDL) based methods have been recently proposed for facial pose estimation, which achieve promising results. However, there are two major issues in existing LDL methods. First, the expectations of label distributions are biased, leading to a biased pose estimation. Second, fixed distribution parameters are applied for all learning samples, severely limiting the model capability. In this paper, we propose an Anisotropic Spherical Gaussian (ASG)-based LDL approach for facial pose estimation. In particular, our approach adopts the spherical Gaussian distribution on a unit sphere which constantly generates unbiased expectation. Meanwhile, we introduce a new loss function that allows the network to learn the distribution parameter for each learning sample flexibly. Extensive experimental results show that our method sets new state-of-the-art records on AFLW2000 and BIWI datasets.
Physical Attack on Monocular Depth Estimation with Optimal Adversarial Patches
Jul 11, 2022

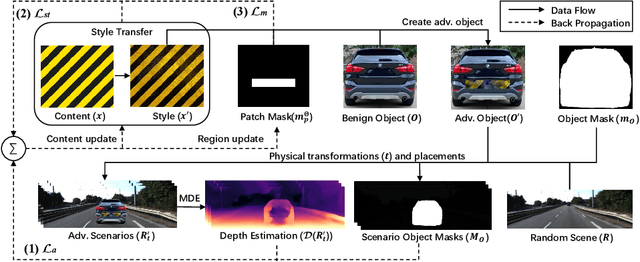
Deep learning has substantially boosted the performance of Monocular Depth Estimation (MDE), a critical component in fully vision-based autonomous driving (AD) systems (e.g., Tesla and Toyota). In this work, we develop an attack against learning-based MDE. In particular, we use an optimization-based method to systematically generate stealthy physical-object-oriented adversarial patches to attack depth estimation. We balance the stealth and effectiveness of our attack with object-oriented adversarial design, sensitive region localization, and natural style camouflage. Using real-world driving scenarios, we evaluate our attack on concurrent MDE models and a representative downstream task for AD (i.e., 3D object detection). Experimental results show that our method can generate stealthy, effective, and robust adversarial patches for different target objects and models and achieves more than 6 meters mean depth estimation error and 93% attack success rate (ASR) in object detection with a patch of 1/9 of the vehicle's rear area. Field tests on three different driving routes with a real vehicle indicate that we cause over 6 meters mean depth estimation error and reduce the object detection rate from 90.70% to 5.16% in continuous video frames.
DG-Labeler and DGL-MOTS Dataset: Boost the Autonomous Driving Perception
Oct 15, 2021
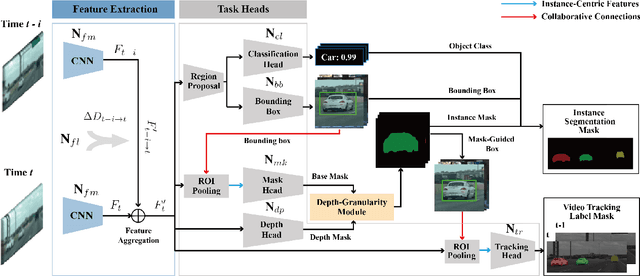
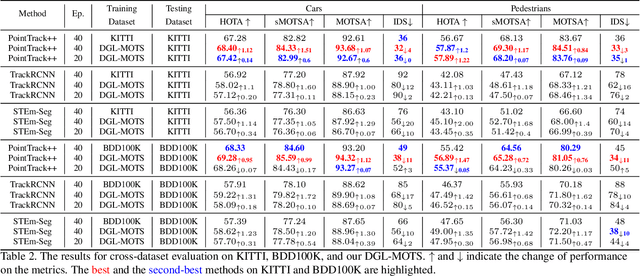
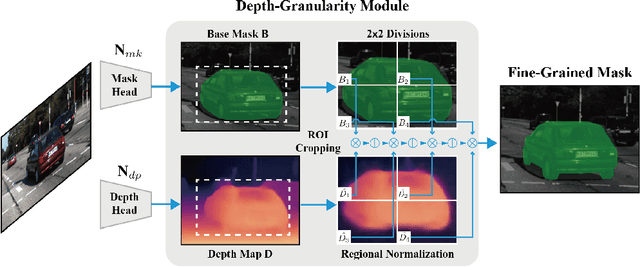
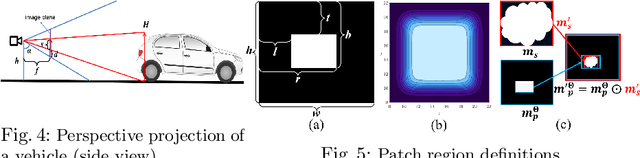
Multi-object tracking and segmentation (MOTS) is a critical task for autonomous driving applications. The existing MOTS studies face two critical challenges: 1) the published datasets inadequately capture the real-world complexity for network training to address various driving settings; 2) the working pipeline annotation tool is under-studied in the literature to improve the quality of MOTS learning examples. In this work, we introduce the DG-Labeler and DGL-MOTS dataset to facilitate the training data annotation for the MOTS task and accordingly improve network training accuracy and efficiency. DG-Labeler uses the novel Depth-Granularity Module to depict the instance spatial relations and produce fine-grained instance masks. Annotated by DG-Labeler, our DGL-MOTS dataset exceeds the prior effort (i.e., KITTI MOTS and BDD100K) in data diversity, annotation quality, and temporal representations. Results on extensive cross-dataset evaluations indicate significant performance improvements for several state-of-the-art methods trained on our DGL-MOTS dataset. We believe our DGL-MOTS Dataset and DG-Labeler hold the valuable potential to boost the visual perception of future transportation.
TF-Blender: Temporal Feature Blender for Video Object Detection
Aug 12, 2021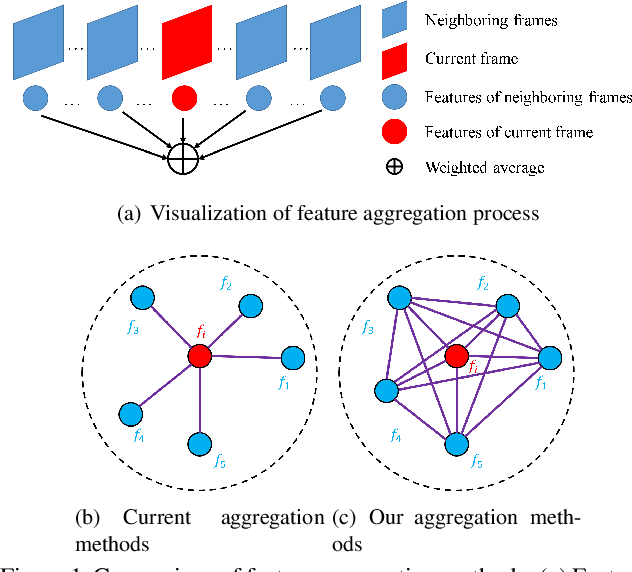
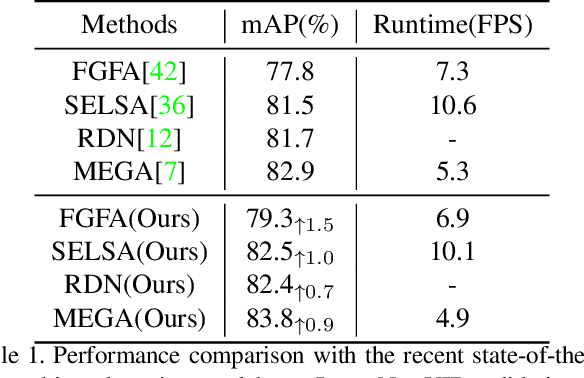
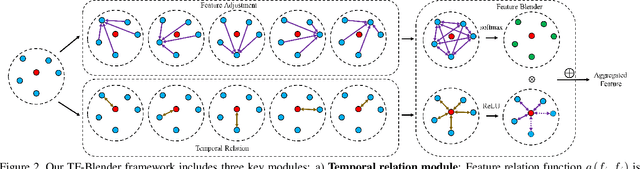
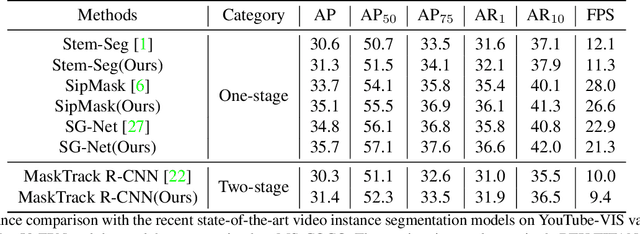
Video objection detection is a challenging task because isolated video frames may encounter appearance deterioration, which introduces great confusion for detection. One of the popular solutions is to exploit the temporal information and enhance per-frame representation through aggregating features from neighboring frames. Despite achieving improvements in detection, existing methods focus on the selection of higher-level video frames for aggregation rather than modeling lower-level temporal relations to increase the feature representation. To address this limitation, we propose a novel solution named TF-Blender,which includes three modules: 1) Temporal relation mod-els the relations between the current frame and its neighboring frames to preserve spatial information. 2). Feature adjustment enriches the representation of every neigh-boring feature map; 3) Feature blender combines outputs from the first two modules and produces stronger features for the later detection tasks. For its simplicity, TF-Blender can be effortlessly plugged into any detection network to improve detection behavior. Extensive evaluations on ImageNet VID and YouTube-VIS benchmarks indicate the performance guarantees of using TF-Blender on recent state-of-the-art methods.