 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchorDream: Repurposing Video Diffusion for Embodiment-Aware Robot Data Synthesis
Dec 12, 2025The collection of large-scale and diverse robot demonstrations remains a major bottleneck for imitation learning, as real-world data acquisition is costly and simulators offer limited diversity and fidelity with pronounced sim-to-real gaps. While generative models present an attractive solution, existing methods often alter only visual appearances without creating new behaviors, or suffer from embodiment inconsistencies that yield implausible motions. To address these limitations, we introduce AnchorDream, an embodiment-aware world model that repurposes pretrained video diffusion models for robot data synthesis. AnchorDream conditions the diffusion process on robot motion renderings, anchoring the embodiment to prevent hallucination while synthesizing objects and environments consistent with the robot's kinematics. Starting from only a handful of human teleoperation demonstrations, our method scales them into large, diverse, high-quality datasets without requiring explicit environment modeling. Experiments show that the generated data leads to consistent improvements in downstream policy learning, with relative gains of 36.4% in simulator benchmarks and nearly double performance in real-world studies. These results suggest that grounding generative world models in robot motion provides a practical path toward scaling imitation learning.
Seeing to Act, Prompting to Specify: A Bayesian Factorization of Vision Language Action Policy
Dec 12, 2025The pursuit of out-of-distribution generalization in Vision-Language-Action (VLA) models is often hindered by catastrophic forgetting of the Vision-Language Model (VLM) backbone during fine-tuning. While co-training with external reasoning data helps, it requires experienced tuning and data-related overhead. Beyond such external dependencies, we identify an intrinsic cause within VLA datasets: modality imbalance, where language diversity is much lower than visual and action diversity. This imbalance biases the model toward visual shortcuts and language forgetting. To address this, we introduce BayesVLA, a Bayesian factorization that decomposes the policy into a visual-action prior, supporting seeing-to-act, and a language-conditioned likelihood, enabling prompt-to-specify. This inherently preserves generalization and promotes instruction following. We further incorporate pre- and post-contact phases to better leverage pre-trained foundation models. Information-theoretic analysis formally validates our effectiveness in mitigating shortcut learning. Extensive experiments show superior generalization to unseen instructions, objects, and environments compared to existing methods. Project page is available at: https://xukechun.github.io/papers/BayesVLA.
Neural Ranging Inertial Odometry
Dec 11, 2025Ultra-wideband (UWB) has shown promising potential in GPS-denied localization thanks to its lightweight and drift-free characteristics, while the accuracy is limited in real scenarios due to its sensitivity to sensor arrangement and non-Gaussian pattern induced by multi-path or multi-signal interference, which commonly occurs in many typical applications like long tunnels. We introduce a novel neural fusion framework for ranging inertial odometry which involves a graph attention UWB network and a recurrent neural inertial network. Our graph net learns scene-relevant ranging patterns and adapts to any number of anchors or tags, realizing accurate positioning without calibration. Additionally, the integration of least squares and the incorporation of nominal frame enhance overall performance and scalability. The effectiveness and robustness of our methods are validated through extensive experiments on both public and self-collected datasets, spanning indoor, outdoor, and tunnel environments. The results demonstrate the superiority of our proposed IR-ULSG in handling challenging conditions, including scenarios outside the convex envelope and cases where only a single anchor is available.
Mr. Virgil: Learning Multi-robot Visual-range Relative Localization
Dec 11, 2025Ultra-wideband (UWB)-vision fusion localization has achieved extensive applications in the domain of multi-agent relative localization. The challenging matching problem between robots and visual detection renders existing methods highly dependent on identity-encoded hardware or delicate tuning algorithms. Overconfident yet erroneous matches may bring about irreversible damage to the localization system. To address this issue, we introduce Mr. Virgil, an end-to-end learning multi-robot visual-range relative localization framework, consisting of a graph neural network for data association between UWB rangings and visual detections, and a differentiable pose graph optimization (PGO) back-end. The graph-based front-end supplies robust matching results, accurate initial position predictions, and credible uncertainty estimates, which are subsequently integrated into the PGO back-end to elevate the accuracy of the final pose estimation. Additionally, a decentralized system is implemented for real-world applications. Experiments spanning varying robot numbers, simulation and real-world, occlusion and non-occlusion conditions showcase the stability and exactitude under various scenes compared to conventional methods. Our code is available at: https://github.com/HiOnes/Mr-Virgil.
Resource Efficient Sleep Staging via Multi-Level Masking and Prompt Learning
Nov 18, 2025Automatic sleep staging plays a vital role in assessing sleep quality and diagnosing sleep disorders. Most existing methods rely heavily on long and continuous EEG recordings, which poses significant challenges for data acquisition in resource-constrained systems, such as wearable or home-based monitoring systems. In this paper, we propose the task of resource-efficient sleep staging, which aims to reduce the amount of signal collected per sleep epoch while maintaining reliable classification performance. To solve this task, we adopt the masking and prompt learning strategy and propose a novel framework called Mask-Aware Sleep Staging (MASS). Specifically, we design a multi-level masking strategy to promote effective feature modeling under partial and irregular observations. To mitigate the loss of contextual information introduced by masking, we further propose a hierarchical prompt learning mechanism that aggregates unmasked data into a global prompt, serving as a semantic anchor for guiding both patch-level and epoch-level feature modeling. MASS is evaluated on four datasets, demonstrating state-of-the-art performance, especially when the amount of data is very limited. This result highlights its potential for efficient and scalable deployment in real-world low-resource sleep monitoring environments.
Why is "Chicago" Predictive of Deceptive Reviews? Using LLMs to Discover Language Phenomena from Lexical Cues
Nov 17, 2025Deceptive reviews mislead consumers, harm businesses, and undermine trust in online marketplaces. Machine learning classifiers can learn from large amounts of training examples to effectively distinguish deceptive reviews from genuine ones. However, the distinguishing features learned by these classifiers are often subtle, fragmented, and difficult for humans to interpret. In this work, we explore using large language models (LLMs) to translate machine-learned lexical cues into human-understandable language phenomena that can differentiate deceptive reviews from genuine ones. We show that language phenomena obtained in this manner are empirically grounded in data, generalizable across similar domains, and more predictive than phenomena either in LLMs' prior knowledge or obtained through in-context learning. These language phenomena have the potential to aid people in critically assessing the credibility of online reviews in environments where deception detection classifiers are unavailable.
SeFA-Policy: Fast and Accurate Visuomotor Policy Learning with Selective Flow Alignment
Nov 11, 2025Developing efficient and accurate visuomotor policies poses a central challenge in robotic imitation learning. While recent rectified flow approaches have advanced visuomotor policy learning, they suffer from a key limitation: After iterative distillation, generated actions may deviate from the ground-truth actions corresponding to the current visual observation, leading to accumulated error as the reflow process repeats and unstable task execution. We present Selective Flow Alignment (SeFA), an efficient and accurate visuomotor policy learning framework. SeFA resolves this challenge by a selective flow alignment strategy, which leverages expert demonstrations to selectively correct generated actions and restore consistency with observations, while preserving multimodality. This design introduces a consistency correction mechanism that ensures generated actions remain observation-aligned without sacrificing the efficiency of one-step flow inference. Extensive experiments across both simulated and real-world manipulation tasks show that SeFA Policy surpasses state-of-the-art diffusion-based and flow-based policies, achieving superior accuracy and robustness while reducing inference latency by over 98%. By unifying rectified flow efficiency with observation-consistent action generation, SeFA provides a scalable and dependable solution for real-time visuomotor policy learning. Code is available on https://github.com/RongXueZoe/SeFA.
Versatile and Risk-Sensitive Cardiac Diagnosis via Graph-Based ECG Signal Representation
Nov 11, 2025Despite the rapid advancements of electrocardiogram (ECG) signal diagnosis and analysis methods through deep learning, two major hurdles still limit their clinical adoption: the lack of versatility in processing ECG signals with diverse configurations, and the inadequate detection of risk signals due to sample imbalances. Addressing these challenges, we introduce VersAtile and Risk-Sensitive cardiac diagnosis (VARS), an innovative approach that employs a graph-based representation to uniformly model heterogeneous ECG signals. VARS stands out by transforming ECG signals into versatile graph structures that capture critical diagnostic features, irrespective of signal diversity in the lead count, sampling frequency, and duration. This graph-centric formulation also enhances diagnostic sensitivity, enabling precise localization and identification of abnormal ECG patterns that often elude standard analysis methods. To facilitate representation transformation, our approach integrates denoising reconstruction with contrastive learning to preserve raw ECG information while highlighting pathognomonic patterns. We rigorously evaluate the efficacy of VARS on three distinct ECG datasets, encompassing a range of structural variations. The results demonstrate that VARS not only consistently surpasses existing state-of-the-art models across all these datasets but also exhibits substantial improvement in identifying risk signals. Additionally, VARS offers interpretability by pinpointing the exact waveforms that lead to specific model outputs, thereby assisting clinicians in making informed decisions. These findings suggest that our VARS will likely emerge as an invaluable tool for comprehensive cardiac health assessment.
Robot Learning from a Physical World Model
Nov 10, 2025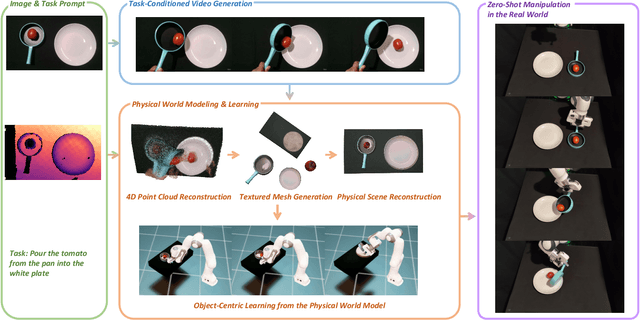

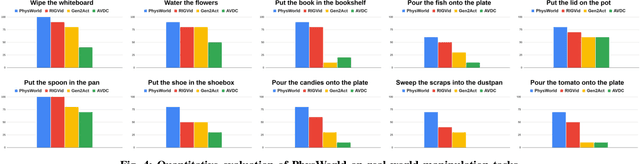

We introduce PhysWorld, a framework that enables robot learning from video generation through physical world modeling. Recent video generation models can synthesize photorealistic visual demonstrations from language commands and images, offering a powerful yet underexplored source of training signals for robotics. However, directly retargeting pixel motions from generated videos to robots neglects physics, often resulting in inaccurate manipulations. PhysWorld addresses this limitation by coupling video generation with physical world reconstruction. Given a single image and a task command, our method generates task-conditioned videos and reconstructs the underlying physical world from the videos, and the generated video motions are grounded into physically accurate actions through object-centric residual reinforcement learning with the physical world model. This synergy transforms implicit visual guidance into physically executable robotic trajectories, eliminating the need for real robot data collection and enabling zero-shot generalizable robotic manipulation. Experiments on diverse real-world tasks demonstrate that PhysWorld substantially improves manipulation accuracy compared to previous approaches. Visit \href{https://pointscoder.github.io/PhysWorld_Web/}{the project webpage} for details.
Diffusion-Based Image Editing: An Unforeseen Adversary to Robust Invisible Watermarks
Nov 05, 2025

Robust invisible watermarking aims to embed hidden messages into images such that they survive various manipulations while remaining imperceptible. However, powerful diffusion-based image generation and editing models now enable realistic content-preserving transformations that can inadvertently remove or distort embedded watermarks. In this paper, we present a theoretical and empirical analysis demonstrating that diffusion-based image editing can effectively break state-of-the-art robust watermarks designed to withstand conventional distortions. We analyze how the iterative noising and denoising process of diffusion models degrades embedded watermark signals, and provide formal proofs that under certain conditions a diffusion model's regenerated image retains virtually no detectable watermark information. Building on this insight, we propose a diffusion-driven attack that uses generative image regeneration to erase watermarks from a given image. Furthermore, we introduce an enhanced \emph{guided diffusion} attack that explicitly targets the watermark during generation by integrating the watermark decoder into the sampling loop. We evaluate our approaches on multiple recent deep learning watermarking schemes (e.g., StegaStamp, TrustMark, and VINE) and demonstrate that diffusion-based editing can reduce watermark decoding accuracy to near-zero levels while preserving high visual fidelity of the images. Our findings reveal a fundamental vulnerability in current robust watermarking techniques against generative model-based edits, underscoring the need for new watermarking strategies in the era of generative AI.