 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboDream: Compositional World Models for Scalable Robot Data Synthesis
Jun 01, 2026Scaling robot learning requires large-scale, diverse demonstrations, yet real-world data collection via teleoperation remains prohibitively expensive and time-consuming. While video diffusion models offer a promising avenue for data scaling, existing generative approaches are often limited to superficial visual augmentation, or suffer from embodiment hallucinations that yield physically infeasible motions. We present a generalizable embodiment-centric world model that achieves scalable data generation by synthesizing photorealistic demonstrations with novel objects, in novel scenes, and from novel viewpoints. Our approach anchors generation to rendered robot motion while conditioning on explicit scene and object priors, effectively decoupling trajectory execution from environment synthesis. This formulation has the potential to unlock two powerful data scaling capabilities: (1) retrieval and rebirth, which repurposes existing trajectories into entirely new contexts without new motion data; and (2) prop-free teleoperation, where operators manipulate empty air and the model hallucinates the target objects and scene afterwards, eliminating reset time. We demonstrate with real-world experiments that our generated data consistently improves downstream policy performance and significantly reduces real-world data requirements across diverse manipulation tasks.
AnyView: Synthesizing Any Novel View in Dynamic Scenes
Jan 23, 2026Modern generative video models excel at producing convincing, high-quality outputs, but struggle to maintain multi-view and spatiotemporal consistency in highly dynamic real-world environments. In this work, we introduce \textbf{AnyView}, a diffusion-based video generation framework for \emph{dynamic view synthesis} with minimal inductive biases or geometric assumptions. We leverage multiple data sources with various levels of supervision, including monocular (2D), multi-view static (3D) and multi-view dynamic (4D) datasets, to train a generalist spatiotemporal implicit representation capable of producing zero-shot novel videos from arbitrary camera locations and trajectories. We evaluate AnyView on standard benchmarks, showing competitive results with the current state of the art, and propose \textbf{AnyViewBench}, a challenging new benchmark tailored towards \emph{extreme} dynamic view synthesis in diverse real-world scenarios. In this more dramatic setting, we find that most baselines drastically degrade in performance, as they require significant overlap between viewpoints, while AnyView maintains the ability to produce realistic, plausible, and spatiotemporally consistent videos when prompted from \emph{any} viewpoint. Results, data, code, and models can be viewed at: https://tri-ml.github.io/AnyView/
Fiducial Exoskeletons: Image-Centric Robot State Estimation
Jan 12, 2026We introduce Fiducial Exoskeletons, an image-based reformulation of 3D robot state estimation that replaces cumbersome procedures and motor-centric pipelines with single-image inference. Traditional approaches - especially robot-camera extrinsic estimation - often rely on high-precision actuators and require time-consuming routines such as hand-eye calibration. In contrast, modern learning-based robot control is increasingly trained and deployed from RGB observations on lower-cost hardware. Our key insight is twofold. First, we cast robot state estimation as 6D pose estimation of each link from a single RGB image: the robot-camera base transform is obtained directly as the estimated base-link pose, and the joint state is recovered via a lightweight global optimization that enforces kinematic consistency with the observed link poses (optionally warm-started with encoder readings). Second, we make per-link 6D pose estimation robust and simple - even without learning - by introducing the fiducial exoskeleton: a lightweight 3D-printed mount with a fiducial marker on each link and known marker-link geometry. This design yields robust camera-robot extrinsics, per-link SE(3) poses, and joint-angle state from a single image, enabling robust state estimation even on unplugged robots. Demonstrated on a low-cost robot arm, fiducial exoskeletons substantially simplify setup while improving calibration, state accuracy, and downstream 3D control performance. We release code and printable hardware designs to enable further algorithm-hardware co-design.
AnchorDream: Repurposing Video Diffusion for Embodiment-Aware Robot Data Synthesis
Dec 12, 2025The collection of large-scale and diverse robot demonstrations remains a major bottleneck for imitation learning, as real-world data acquisition is costly and simulators offer limited diversity and fidelity with pronounced sim-to-real gaps. While generative models present an attractive solution, existing methods often alter only visual appearances without creating new behaviors, or suffer from embodiment inconsistencies that yield implausible motions. To address these limitations, we introduce AnchorDream, an embodiment-aware world model that repurposes pretrained video diffusion models for robot data synthesis. AnchorDream conditions the diffusion process on robot motion renderings, anchoring the embodiment to prevent hallucination while synthesizing objects and environments consistent with the robot's kinematics. Starting from only a handful of human teleoperation demonstrations, our method scales them into large, diverse, high-quality datasets without requiring explicit environment modeling. Experiments show that the generated data leads to consistent improvements in downstream policy learning, with relative gains of 36.4% in simulator benchmarks and nearly double performance in real-world studies. These results suggest that grounding generative world models in robot motion provides a practical path toward scaling imitation learning.
SIRE: SE(3) Intrinsic Rigidity Embeddings
Mar 10, 2025



Motion serves as a powerful cue for scene perception and understanding by separating independently moving surfaces and organizing the physical world into distinct entities. We introduce SIRE, a self-supervised method for motion discovery of objects and dynamic scene reconstruction from casual scenes by learning intrinsic rigidity embeddings from videos. Our method trains an image encoder to estimate scene rigidity and geometry, supervised by a simple 4D reconstruction loss: a least-squares solver uses the estimated geometry and rigidity to lift 2D point track trajectories into SE(3) tracks, which are simply re-projected back to 2D and compared against the original 2D trajectories for supervision. Crucially, our framework is fully end-to-end differentiable and can be optimized either on video datasets to learn generalizable image priors, or even on a single video to capture scene-specific structure - highlighting strong data efficiency. We demonstrate the effectiveness of our rigidity embeddings and geometry across multiple settings, including downstream object segmentation, SE(3) rigid motion estimation, and self-supervised depth estimation. Our findings suggest that SIRE can learn strong geometry and motion rigidity priors from video data, with minimal supervision.
Controlling the World by Sleight of Hand
Aug 13, 2024



Humans naturally build mental models of object interactions and dynamics, allowing them to imagine how their surroundings will change if they take a certain action. While generative models today have shown impressive results on generating/editing images unconditionally or conditioned on text, current methods do not provide the ability to perform object manipulation conditioned on actions, an important tool for world modeling and action planning. Therefore, we propose to learn an action-conditional generative models by learning from unlabeled videos of human hands interacting with objects. The vast quantity of such data on the internet allows for efficient scaling which can enable high-performing action-conditional models. Given an image, and the shape/location of a desired hand interaction, CosHand, synthesizes an image of a future after the interaction has occurred. Experiments show that the resulting model can predict the effects of hand-object interactions well, with strong generalization particularly to translation, stretching, and squeezing interactions of unseen objects in unseen environments. Further, CosHand can be sampled many times to predict multiple possible effects, modeling the uncertainty of forces in the interaction/environment. Finally, method generalizes to different embodiments, including non-human hands, i.e. robot hands, suggesting that generative video models can be powerful models for robotics.
Generative Camera Dolly: Extreme Monocular Dynamic Novel View Synthesis
May 23, 2024



Accurate reconstruction of complex dynamic scenes from just a single viewpoint continues to be a challenging task in computer vision. Current dynamic novel view synthesis methods typically require videos from many different camera viewpoints, necessitating careful recording setups, and significantly restricting their utility in the wild as well as in terms of embodied AI applications. In this paper, we propose $\textbf{GCD}$, a controllable monocular dynamic view synthesis pipeline that leverages large-scale diffusion priors to, given a video of any scene, generate a synchronous video from any other chosen perspective, conditioned on a set of relative camera pose parameters. Our model does not require depth as input, and does not explicitly model 3D scene geometry, instead performing end-to-end video-to-video translation in order to achieve its goal efficiently. Despite being trained on synthetic multi-view video data only, zero-shot real-world generalization experiments show promising results in multiple domains, including robotics, object permanence, and driving environments. We believe our framework can potentially unlock powerful applications in rich dynamic scene understanding, perception for robotics, and interactive 3D video viewing experiences for virtual reality.
Tracking through Containers and Occluders in the Wild
May 04, 2023Tracking objects with persistence in cluttered and dynamic environments remains a difficult challenge for computer vision systems. In this paper, we introduce $\textbf{TCOW}$, a new benchmark and model for visual tracking through heavy occlusion and containment. We set up a task where the goal is to, given a video sequence, segment both the projected extent of the target object, as well as the surrounding container or occluder whenever one exists. To study this task, we create a mixture of synthetic and annotated real datasets to support both supervised learning and structured evaluation of model performance under various forms of task variation, such as moving or nested containment. We evaluate two recent transformer-based video models and find that while they can be surprisingly capable of tracking targets under certain settings of task variation, there remains a considerable performance gap before we can claim a tracking model to have acquired a true notion of object permanence.
Zero-1-to-3: Zero-shot One Image to 3D Object
Mar 20, 2023



We introduce Zero-1-to-3, a framework for changing the camera viewpoint of an object given just a single RGB image. To perform novel view synthesis in this under-constrained setting, we capitalize on the geometric priors that large-scale diffusion models learn about natural images. Our conditional diffusion model uses a synthetic dataset to learn controls of the relative camera viewpoint, which allow new images to be generated of the same object under a specified camera transformation. Even though it is trained on a synthetic dataset, our model retains a strong zero-shot generalization ability to out-of-distribution datasets as well as in-the-wild images, including impressionist paintings. Our viewpoint-conditioned diffusion approach can further be used for the task of 3D reconstruction from a single image. Qualitative and quantitative experiments show that our method significantly outperforms state-of-the-art single-view 3D reconstruction and novel view synthesis models by leveraging Internet-scale pre-training.
Revealing Occlusions with 4D Neural Fields
Apr 22, 2022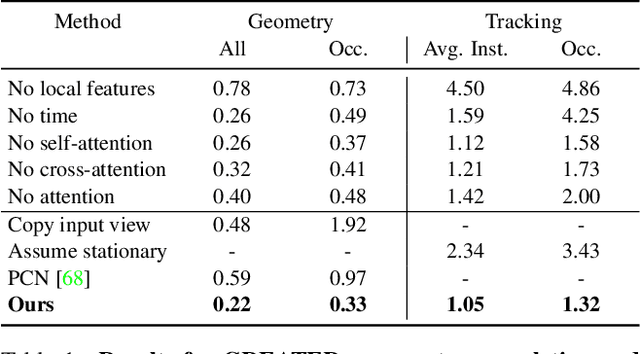
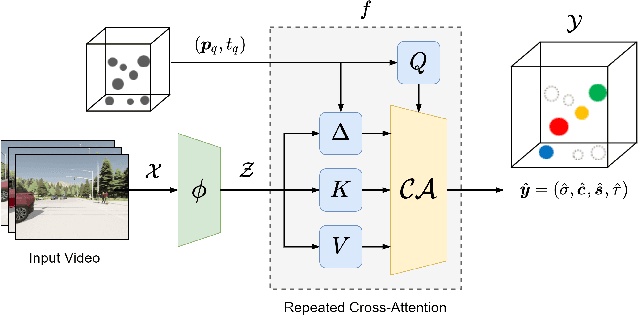
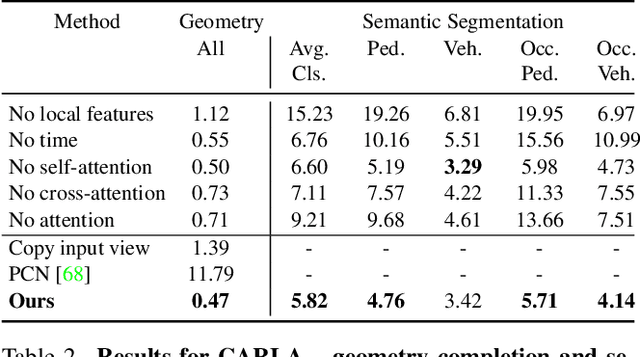
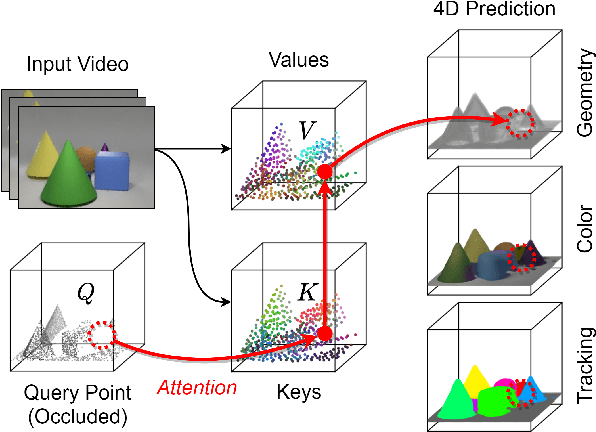
For computer vision systems to operate in dynamic situations, they need to be able to represent and reason about object permanence. We introduce a framework for learning to estimate 4D visual representations from monocular RGB-D, which is able to persist objects, even once they become obstructed by occlusions. Unlike traditional video representations, we encode point clouds into a continuous representation, which permits the model to attend across the spatiotemporal context to resolve occlusions. On two large video datasets that we release along with this paper, our experiments show that the representation is able to successfully reveal occlusions for several tasks, without any architectural changes. Visualizations show that the attention mechanism automatically learns to follow occluded objects. Since our approach can be trained end-to-end and is easily adaptable, we believe it will be useful for handling occlusions in many video understanding tasks. Data, code, and models are available at https://occlusions.cs.columbia.edu/.