 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAMBO-NET: Multi-Causal Aware Modeling Backdoor-Intervention Optimization for Medical Image Segmentation Network
May 28, 2025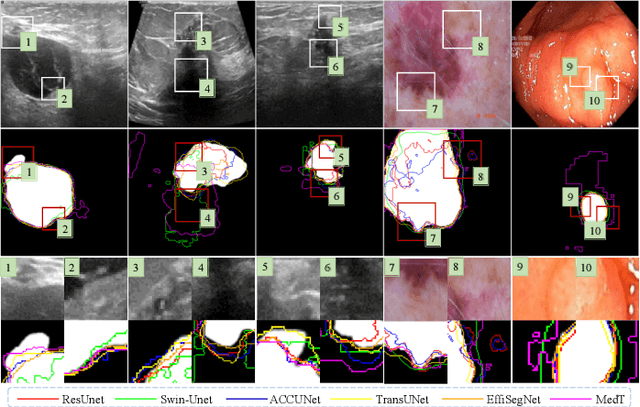
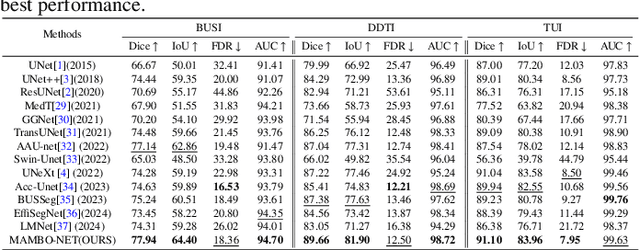
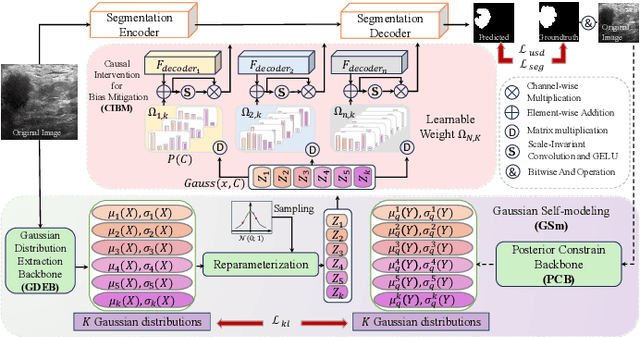
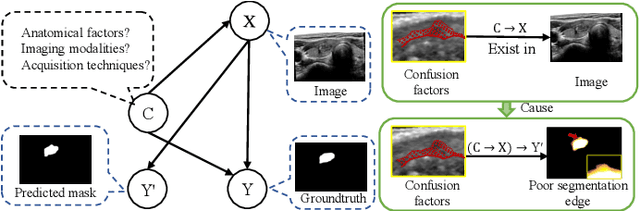
Medical image segmentation methods generally assume that the process from medical image to segmentation is unbiased, and use neural networks to establish conditional probability models to complete the segmentation task. This assumption does not consider confusion factors, which can affect medical images, such as complex anatomical variations and imaging modality limitations. Confusion factors obfuscate the relevance and causality of medical image segmentation, leading to unsatisfactory segmentation results. To address this issue, we propose a multi-causal aware modeling backdoor-intervention optimization (MAMBO-NET) network for medical image segmentation. Drawing insights from causal inference, MAMBO-NET utilizes self-modeling with multi-Gaussian distributions to fit the confusion factors and introduce causal intervention into the segmentation process. Moreover, we design appropriate posterior probability constraints to effectively train the distributions of confusion factors. For the distributions to effectively guide the segmentation and mitigate and eliminate the Impact of confusion factors on the segmentation, we introduce classical backdoor intervention techniques and analyze their feasibility in the segmentation task. To evaluate the effectiveness of our approach, we conducted extensive experiments on five medical image datasets. The results demonstrate that our method significantly reduces the influence of confusion factors, leading to enhanced segmentation accuracy.
Perceptual Quality Assessment for Embodied AI
May 22, 2025



Embodied AI has developed rapidly in recent years, but it is still mainly deployed in laboratories, with various distortions in the Real-world limiting its application. Traditionally, Image Quality Assessment (IQA) methods are applied to predict human preferences for distorted images; however, there is no IQA method to assess the usability of an image in embodied tasks, namely, the perceptual quality for robots. To provide accurate and reliable quality indicators for future embodied scenarios, we first propose the topic: IQA for Embodied AI. Specifically, we (1) based on the Mertonian system and meta-cognitive theory, constructed a perception-cognition-decision-execution pipeline and defined a comprehensive subjective score collection process; (2) established the Embodied-IQA database, containing over 36k reference/distorted image pairs, with more than 5m fine-grained annotations provided by Vision Language Models/Vision Language Action-models/Real-world robots; (3) trained and validated the performance of mainstream IQA methods on Embodied-IQA, demonstrating the need to develop more accurate quality indicators for Embodied AI. We sincerely hope that through evaluation, we can promote the application of Embodied AI under complex distortions in the Real-world. Project page: https://github.com/lcysyzxdxc/EmbodiedIQA
Advancing Generalizable Tumor Segmentation with Anomaly-Aware Open-Vocabulary Attention Maps and Frozen Foundation Diffusion Models
May 05, 2025We explore Generalizable Tumor Segmentation, aiming to train a single model for zero-shot tumor segmentation across diverse anatomical regions. Existing methods face limitations related to segmentation quality, scalability, and the range of applicable imaging modalities. In this paper, we uncover the potential of the internal representations within frozen medical foundation diffusion models as highly efficient zero-shot learners for tumor segmentation by introducing a novel framework named DiffuGTS. DiffuGTS creates anomaly-aware open-vocabulary attention maps based on text prompts to enable generalizable anomaly segmentation without being restricted by a predefined training category list. To further improve and refine anomaly segmentation masks, DiffuGTS leverages the diffusion model, transforming pathological regions into high-quality pseudo-healthy counterparts through latent space inpainting, and applies a novel pixel-level and feature-level residual learning approach, resulting in segmentation masks with significantly enhanced quality and generalization. Comprehensive experiments on four datasets and seven tumor categories demonstrate the superior performance of our method, surpassing current state-of-the-art models across multiple zero-shot settings. Codes are available at https://github.com/Yankai96/DiffuGTS.
PuzzleBench: A Fully Dynamic Evaluation Framework for Large Multimodal Models on Puzzle Solving
Apr 15, 2025Large Multimodal Models (LMMs) have demonstrated impressive capabilities across a wide range of multimodal tasks, achieving ever-increasing performance on various evaluation benchmarks. However, existing benchmarks are typically static and often overlap with pre-training datasets, leading to fixed complexity constraints and substantial data contamination issues. Meanwhile, manually annotated datasets are labor-intensive, time-consuming, and subject to human bias and inconsistency, leading to reliability and reproducibility issues. To address these problems, we propose a fully dynamic multimodal evaluation framework, named Open-ended Visual Puzzle Generation (OVPG), which aims to generate fresh, diverse, and verifiable evaluation data automatically in puzzle-solving tasks. Specifically, the OVPG pipeline consists of a raw material sampling module, a visual content generation module, and a puzzle rule design module, which ensures that each evaluation instance is primitive, highly randomized, and uniquely solvable, enabling continual adaptation to the evolving capabilities of LMMs. Built upon OVPG, we construct PuzzleBench, a dynamic and scalable benchmark comprising 11,840 VQA samples. It features six carefully designed puzzle tasks targeting three core LMM competencies, visual recognition, logical reasoning, and context understanding. PuzzleBench differs from static benchmarks that quickly become outdated. It enables ongoing dataset refreshing through OVPG and a rich set of open-ended puzzle designs, allowing seamless adaptation to the evolving capabilities of LMMs.
The Tenth NTIRE 2025 Efficient Super-Resolution Challenge Report
Apr 14, 2025This paper presents a comprehensive review of the NTIRE 2025 Challenge on Single-Image Efficient Super-Resolution (ESR). The challenge aimed to advance the development of deep models that optimize key computational metrics, i.e., runtime, parameters, and FLOPs, while achieving a PSNR of at least 26.90 dB on the $\operatorname{DIV2K\_LSDIR\_valid}$ dataset and 26.99 dB on the $\operatorname{DIV2K\_LSDIR\_test}$ dataset. A robust participation saw \textbf{244} registered entrants, with \textbf{43} teams submitting valid entries. This report meticulously analyzes these methods and results, emphasizing groundbreaking advancements in state-of-the-art single-image ESR techniques. The analysis highlights innovative approaches and establishes benchmarks for future research in the field.
Image Quality Assessment: From Human to Machine Preference
Mar 13, 2025Image Quality Assessment (IQA) based on human subjective preferences has undergone extensive research in the past decades. However, with the development of communication protocols, the visual data consumption volume of machines has gradually surpassed that of humans. For machines, the preference depends on downstream tasks such as segmentation and detection, rather than visual appeal. Considering the huge gap between human and machine visual systems, this paper proposes the topic: Image Quality Assessment for Machine Vision for the first time. Specifically, we (1) defined the subjective preferences of machines, including downstream tasks, test models, and evaluation metrics; (2) established the Machine Preference Database (MPD), which contains 2.25M fine-grained annotations and 30k reference/distorted image pair instances; (3) verified the performance of mainstream IQA algorithms on MPD. Experiments show that current IQA metrics are human-centric and cannot accurately characterize machine preferences. We sincerely hope that MPD can promote the evolution of IQA from human to machine preferences. Project page is on: https://github.com/lcysyzxdxc/MPD.
Information Density Principle for MLLM Benchmarks
Mar 13, 2025With the emergence of Multimodal Large Language Models (MLLMs), hundreds of benchmarks have been developed to ensure the reliability of MLLMs in downstream tasks. However, the evaluation mechanism itself may not be reliable. For developers of MLLMs, questions remain about which benchmark to use and whether the test results meet their requirements. Therefore, we propose a critical principle of Information Density, which examines how much insight a benchmark can provide for the development of MLLMs. We characterize it from four key dimensions: (1) Fallacy, (2) Difficulty, (3) Redundancy, (4) Diversity. Through a comprehensive analysis of more than 10,000 samples, we measured the information density of 19 MLLM benchmarks. Experiments show that using the latest benchmarks in testing can provide more insight compared to previous ones, but there is still room for improvement in their information density. We hope this principle can promote the development and application of future MLLM benchmarks. Project page: https://github.com/lcysyzxdxc/bench4bench
Towards All-in-One Medical Image Re-Identification
Mar 11, 2025Medical image re-identification (MedReID) is under-explored so far, despite its critical applications in personalized healthcare and privacy protection. In this paper, we introduce a thorough benchmark and a unified model for this problem. First, to handle various medical modalities, we propose a novel Continuous Modality-based Parameter Adapter (ComPA). ComPA condenses medical content into a continuous modality representation and dynamically adjusts the modality-agnostic model with modality-specific parameters at runtime. This allows a single model to adaptively learn and process diverse modality data. Furthermore, we integrate medical priors into our model by aligning it with a bag of pre-trained medical foundation models, in terms of the differential features. Compared to single-image feature, modeling the inter-image difference better fits the re-identification problem, which involves discriminating multiple images. We evaluate the proposed model against 25 foundation models and 8 large multi-modal language models across 11 image datasets, demonstrating consistently superior performance. Additionally, we deploy the proposed MedReID technique to two real-world applications, i.e., history-augmented personalized diagnosis and medical privacy protection. Codes and model is available at \href{https://github.com/tianyuan168326/All-in-One-MedReID-Pytorch}{https://github.com/tianyuan168326/All-in-One-MedReID-Pytorch}.
CGMatch: A Different Perspective of Semi-supervised Learning
Mar 04, 2025



Semi-supervised learning (SSL) has garnered significant attention due to its ability to leverage limited labeled data and a large amount of unlabeled data to improve model generalization performance. Recent approaches achieve impressive successes by combining ideas from both consistency regularization and pseudo-labeling. However, these methods tend to underperform in the more realistic situations with relatively scarce labeled data. We argue that this issue arises because existing methods rely solely on the model's confidence, making them challenging to accurately assess the model's state and identify unlabeled examples contributing to the training phase when supervision information is limited, especially during the early stages of model training. In this paper, we propose a novel SSL model called CGMatch, which, for the first time, incorporates a new metric known as Count-Gap (CG). We demonstrate that CG is effective in discovering unlabeled examples beneficial for model training. Along with confidence, a commonly used metric in SSL, we propose a fine-grained dynamic selection (FDS) strategy. This strategy dynamically divides the unlabeled dataset into three subsets with different characteristics: easy-to-learn set, ambiguous set, and hard-to-learn set. By selective filtering subsets, and applying corresponding regularization with selected subsets, we mitigate the negative impact of incorrect pseudo-labels on model optimization and generalization. Extensive experimental results on several common SSL benchmarks indicate the effectiveness of CGMatch especially when the labeled data are particularly limited. Source code is available at https://github.com/BoCheng-96/CGMatch.
Text-to-SQL Domain Adaptation via Human-LLM Collaborative Data Annotation
Feb 21, 2025Text-to-SQL models, which parse natural language (NL) questions to executable SQL queries, are increasingly adopted in real-world applications. However, deploying such models in the real world often requires adapting them to the highly specialized database schemas used in specific applications. We find that existing text-to-SQL models experience significant performance drops when applied to new schemas, primarily due to the lack of domain-specific data for fine-tuning. This data scarcity also limits the ability to effectively evaluate model performance in new domains. Continuously obtaining high-quality text-to-SQL data for evolving schemas is prohibitively expensive in real-world scenarios. To bridge this gap, we propose SQLsynth, a human-in-the-loop text-to-SQL data annotation system. SQLsynth streamlines the creation of high-quality text-to-SQL datasets through human-LLM collaboration in a structured workflow. A within-subjects user study comparing SQLsynth with manual annotation and ChatGPT shows that SQLsynth significantly accelerates text-to-SQL data annotation, reduces cognitive load, and produces datasets that are more accurate, natural, and diverse. Our code is available at https://github.com/adobe/nl_sql_analyzer.