 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIQ-LUT: interpolated and quantized LUT for efficient image super-resolution
Apr 08, 2026Lookup table (LUT) methods demonstrate considerable potential in accelerating image super-resolution inference. However, pursuing higher image quality through larger receptive fields and bit-depth triggers exponential growth in the LUT's index space, creating a storage bottleneck that limits deployment on resource-constrained devices. We introduce IQ-LUT, which achieves a reduction in LUT size while simultaneously enhancing super-resolution quality. First, we integrate interpolation and quantization into the single-input, multiple-output ECNN, which dramatically reduces the index space and thereby the overall LUT size. Second, the integration of residual learning mitigates the dependence on LUT bit-depth, which facilitates training stability and prioritizes the reconstruction of fine-grained details for superior visual quality. Finally, guided by knowledge distillation, our non-uniform quantization process optimizes the quantization levels, thereby reducing storage while also compensating for quantization loss. Extensive benchmarking demonstrates our approach substantially reduces storage costs (by up to 50x compared to ECNN) while achieving superior super-resolution quality.
Joint Degradation-Aware Arbitrary-Scale Super-Resolution for Variable-Rate Extreme Image Compression
Mar 18, 2026Recent diffusion-based extreme image compression methods have demonstrated remarkable performance at ultra-low bitrates. However, most approaches require training separate diffusion models for each target bitrate, resulting in substantial computational overhead and hindering practical deployment. Meanwhile, recent studies have shown that joint super-resolution can serve as an effective approach for enhancing low-bitrate reconstruction. However, when moving toward ultra-low bitrate regimes, these methods struggle due to severe information loss, and their reliance on fixed super-resolution scales prevents flexible adaptation across diverse bitrates. To address these limitations, we propose ASSR-EIC, a novel image compression framework that leverages arbitrary-scale super-resolution (ASSR) to support variable-rate extreme image compression (EIC). An arbitrary-scale downsampling module is introduced at the encoder side to provide controllable rate reduction, while a diffusion-based, joint degradation-aware ASSR decoder enables rate-adaptive reconstruction within a single model. We exploit the compression- and rescaling-aware diffusion prior to guide the reconstruction, yielding high fidelity and high realism restoration across diverse compression and rescaling settings. Specifically, we design a global compression-rescaling adaptor that offers holistic guidance for rate adaptation, and a local compression-rescaling modulator that dynamically balances generative and fidelity-oriented behaviors to achieve fine-grained, bitrate-adaptive detail restoration. To further enhance reconstruction quality, we introduce a dual semantic-enhanced design. Extensive experiments demonstrate that ASSR-EIC delivers state-of-the-art performance in extreme image compression while simultaneously supporting flexible bitrate control and adaptive rate-dependent reconstruction.
Distillation-Supervised Convolutional Low-Rank Adaptation for Efficient Image Super-Resolution
Apr 15, 2025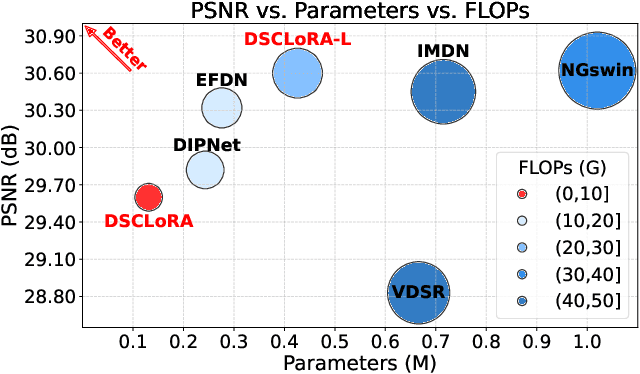
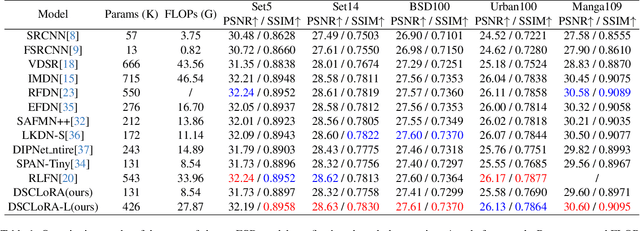
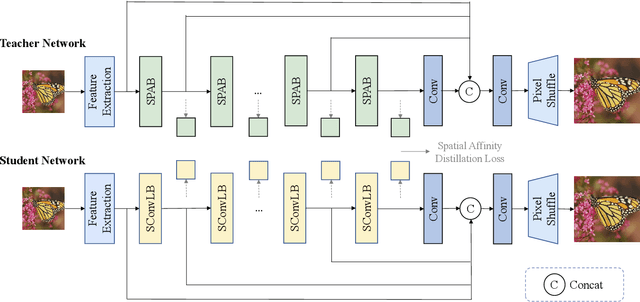

Convolutional neural networks (CNNs) have been widely used in efficient image super-resolution. However, for CNN-based methods, performance gains often require deeper networks and larger feature maps, which increase complexity and inference costs. Inspired by LoRA's success in fine-tuning large language models, we explore its application to lightweight models and propose Distillation-Supervised Convolutional Low-Rank Adaptation (DSCLoRA), which improves model performance without increasing architectural complexity or inference costs. Specifically, we integrate ConvLoRA into the efficient SR network SPAN by replacing the SPAB module with the proposed SConvLB module and incorporating ConvLoRA layers into both the pixel shuffle block and its preceding convolutional layer. DSCLoRA leverages low-rank decomposition for parameter updates and employs a spatial feature affinity-based knowledge distillation strategy to transfer second-order statistical information from teacher models (pre-trained SPAN) to student models (ours). This method preserves the core knowledge of lightweight models and facilitates optimal solution discovery under certain conditions. Experiments on benchmark datasets show that DSCLoRA improves PSNR and SSIM over SPAN while maintaining its efficiency and competitive image quality. Notably, DSCLoRA ranked first in the Overall Performance Track of the NTIRE 2025 Efficient Super-Resolution Challenge. Our code and models are made publicly available at https://github.com/Yaozzz666/DSCF-SR.
Enhanced Semantic Extraction and Guidance for UGC Image Super Resolution
Apr 14, 2025Due to the disparity between real-world degradations in user-generated content(UGC) images and synthetic degradations, traditional super-resolution methods struggle to generalize effectively, necessitating a more robust approach to model real-world distortions. In this paper, we propose a novel approach to UGC image super-resolution by integrating semantic guidance into a diffusion framework. Our method addresses the inconsistency between degradations in wild and synthetic datasets by separately simulating the degradation processes on the LSDIR dataset and combining them with the official paired training set. Furthermore, we enhance degradation removal and detail generation by incorporating a pretrained semantic extraction model (SAM2) and fine-tuning key hyperparameters for improved perceptual fidelity. Extensive experiments demonstrate the superiority of our approach against state-of-the-art methods. Additionally, the proposed model won second place in the CVPR NTIRE 2025 Short-form UGC Image Super-Resolution Challenge, further validating its effectiveness. The code is available at https://github.c10pom/Moonsofang/NTIRE-2025-SRlab.
The Tenth NTIRE 2025 Efficient Super-Resolution Challenge Report
Apr 14, 2025This paper presents a comprehensive review of the NTIRE 2025 Challenge on Single-Image Efficient Super-Resolution (ESR). The challenge aimed to advance the development of deep models that optimize key computational metrics, i.e., runtime, parameters, and FLOPs, while achieving a PSNR of at least 26.90 dB on the $\operatorname{DIV2K\_LSDIR\_valid}$ dataset and 26.99 dB on the $\operatorname{DIV2K\_LSDIR\_test}$ dataset. A robust participation saw \textbf{244} registered entrants, with \textbf{43} teams submitting valid entries. This report meticulously analyzes these methods and results, emphasizing groundbreaking advancements in state-of-the-art single-image ESR techniques. The analysis highlights innovative approaches and establishes benchmarks for future research in the field.
MRIR: Integrating Multimodal Insights for Diffusion-based Realistic Image Restoration
Jul 04, 2024



Realistic image restoration is a crucial task in computer vision, and the use of diffusion-based models for image restoration has garnered significant attention due to their ability to produce realistic results. However, the quality of the generated images is still a significant challenge due to the severity of image degradation and the uncontrollability of the diffusion model. In this work, we delve into the potential of utilizing pre-trained stable diffusion for image restoration and propose MRIR, a diffusion-based restoration method with multimodal insights. Specifically, we explore the problem from two perspectives: textual level and visual level. For the textual level, we harness the power of the pre-trained multimodal large language model to infer meaningful semantic information from low-quality images. Furthermore, we employ the CLIP image encoder with a designed Refine Layer to capture image details as a supplement. For the visual level, we mainly focus on the pixel level control. Thus, we utilize a Pixel-level Processor and ControlNet to control spatial structures. Finally, we integrate the aforementioned control information into the denoising U-Net using multi-level attention mechanisms and realize controllable image restoration with multimodal insights. The qualitative and quantitative results demonstrate our method's superiority over other state-of-the-art methods on both synthetic and real-world datasets.
Diff-Restorer: Unleashing Visual Prompts for Diffusion-based Universal Image Restoration
Jul 04, 2024



Image restoration is a classic low-level problem aimed at recovering high-quality images from low-quality images with various degradations such as blur, noise, rain, haze, etc. However, due to the inherent complexity and non-uniqueness of degradation in real-world images, it is challenging for a model trained for single tasks to handle real-world restoration problems effectively. Moreover, existing methods often suffer from over-smoothing and lack of realism in the restored results. To address these issues, we propose Diff-Restorer, a universal image restoration method based on the diffusion model, aiming to leverage the prior knowledge of Stable Diffusion to remove degradation while generating high perceptual quality restoration results. Specifically, we utilize the pre-trained visual language model to extract visual prompts from degraded images, including semantic and degradation embeddings. The semantic embeddings serve as content prompts to guide the diffusion model for generation. In contrast, the degradation embeddings modulate the Image-guided Control Module to generate spatial priors for controlling the spatial structure of the diffusion process, ensuring faithfulness to the original image. Additionally, we design a Degradation-aware Decoder to perform structural correction and convert the latent code to the pixel domain. We conducted comprehensive qualitative and quantitative analysis on restoration tasks with different degradations, demonstrating the effectiveness and superiority of our approach.
Multimodal Semantic-Aware Automatic Colorization with Diffusion Prior
Apr 25, 2024



Colorizing grayscale images offers an engaging visual experience. Existing automatic colorization methods often fail to generate satisfactory results due to incorrect semantic colors and unsaturated colors. In this work, we propose an automatic colorization pipeline to overcome these challenges. We leverage the extraordinary generative ability of the diffusion prior to synthesize color with plausible semantics. To overcome the artifacts introduced by the diffusion prior, we apply the luminance conditional guidance. Moreover, we adopt multimodal high-level semantic priors to help the model understand the image content and deliver saturated colors. Besides, a luminance-aware decoder is designed to restore details and enhance overall visual quality. The proposed pipeline synthesizes saturated colors while maintaining plausible semantics. Experiments indicate that our proposed method considers both diversity and fidelity, surpassing previous methods in terms of perceptual realism and gain most human preference.