 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEOS-Bench: A Comprehensive Benchmark for Earth Observation Satellite Scheduling
Apr 28, 2026Earth observation satellite imaging scheduling is a challenging NP-hard combinatorial optimisation problem central to space mission operations. While next-generation agile Earth observation satellites (EOS) increase operational flexibility, they also significantly raise scheduling complexity. The lack of a unified, open-source benchmark makes it difficult to compare algorithms across studies. This paper introduces EOS-Bench, a comprehensive framework for systematic and reproducible evaluation of scheduling methods. By integrating high-fidelity orbital dynamics and platform constraints, EOS-Bench generates 1,390 scenarios and 13,900 benchmark instances, spanning from small-scale validation cases to large coordination problems with up to 1,000 satellites and 10,000 requests. We further propose a scenario characterisation scheme to quantify structural difficulty based on factors such as opportunity density, task flexibility, conflict intensity, and satellite congestion. A multidimensional evaluation protocol is introduced, assessing performance across five metrics: task profit, completion rate, workload balance, timeliness, and runtime. The framework is evaluated using mixed-integer programming, heuristics, meta-heuristics, and deep reinforcement learning across both agile and non-agile settings. Results show that EOS-Bench effectively distinguishes solver performance across scales and conditions, revealing trade-offs between solution quality and computational efficiency, and providing deeper insight into scenario complexity. EOS-Bench offers a unified and extensible open testbed for advancing research in Earth observation satellite scheduling. The code and data are available at https://github.com/Ethan19YQ/EOS-Bench.
Informed Machine Learning with Knowledge Landmarks
Mar 31, 2026Informed Machine Learning has emerged as a viable generalization of Machine Learning (ML) by building a unified conceptual and algorithmic setting for constructing models on a unified basis of knowledge and data. Physics-informed ML involving physics equations is one of the developments within Informed Machine Learning. This study proposes a novel direction of Knowledge-Data ML, referred to as KD-ML, where numeric data are integrated with knowledge tidbits expressed in the form of granular knowledge landmarks. We advocate that data and knowledge are complementary in several fundamental ways: data are precise (numeric) and local, usually confined to some region of the input space, while knowledge is global and formulated at a higher level of abstraction. The knowledge can be represented as information granules and organized as a collection of input-output information granules called knowledge landmarks. In virtue of this evident complementarity, we develop a comprehensive design process of the KD-ML model and formulate an original augmented loss function L, which additively embraces the component responsible for optimizing the model based on available numeric data, while the second component, playing the role of a granular regularizer, so that it adheres to the granular constraints (knowledge landmarks). We show the role of the hyperparameter positioned in the loss function, which balances the contribution and guiding role of data and knowledge, and point to some essential tendencies associated with the quality of data (noise level) and the level of granularity of the knowledge landmarks. Experiments on two physics-governed benchmarks demonstrate that the proposed KD model consistently outperforms data-driven ML models.
Physics-Informed Neural Network with Adaptive Clustering Learning Mechanism for Information Popularity Prediction
Mar 20, 2026With society entering the Internet era, the volume and speed of data and information have been increasing. Predicting the popularity of information cascades can help with high-value information delivery and public opinion monitoring on the internet platforms. The current state-of-the-art models for predicting information popularity utilize deep learning methods such as graph convolution networks (GCNs) and recurrent neural networks (RNNs) to capture early cascades and temporal features to predict their popularity increments. However, these previous methods mainly focus on the micro features of information cascades, neglecting their general macroscopic patterns. Furthermore, they also lack consideration of the impact of information heterogeneity on spread popularity. To overcome these limitations, we propose a physics-informed neural network with adaptive clustering learning mechanism, PIACN, for predicting the popularity of information cascades. Our proposed model not only models the macroscopic patterns of information dissemination through physics-informed approach for the first time but also considers the influence of information heterogeneity through an adaptive clustering learning mechanism. Extensive experimental results on three real-world datasets demonstrate that our model significantly outperforms other state-of-the-art methods in predicting information popularity.
Theoretical Convergence of SMOTE-Generated Samples
Jan 05, 2026Imbalanced data affects a wide range of machine learning applications, from healthcare to network security. As SMOTE is one of the most popular approaches to addressing this issue, it is imperative to validate it not only empirically but also theoretically. In this paper, we provide a rigorous theoretical analysis of SMOTE's convergence properties. Concretely, we prove that the synthetic random variable Z converges in probability to the underlying random variable X. We further prove a stronger convergence in mean when X is compact. Finally, we show that lower values of the nearest neighbor rank lead to faster convergence offering actionable guidance to practitioners. The theoretical results are supported by numerical experiments using both real-life and synthetic data. Our work provides a foundational understanding that enhances data augmentation techniques beyond imbalanced data scenarios.
GuardFed: A Trustworthy Federated Learning Framework Against Dual-Facet Attacks
Nov 12, 2025Federated learning (FL) enables privacy-preserving collaborative model training but remains vulnerable to adversarial behaviors that compromise model utility or fairness across sensitive groups. While extensive studies have examined attacks targeting either objective, strategies that simultaneously degrade both utility and fairness remain largely unexplored. To bridge this gap, we introduce the Dual-Facet Attack (DFA), a novel threat model that concurrently undermines predictive accuracy and group fairness. Two variants, Synchronous DFA (S-DFA) and Split DFA (Sp-DFA), are further proposed to capture distinct real-world collusion scenarios. Experimental results show that existing robust FL defenses, including hybrid aggregation schemes, fail to resist DFAs effectively. To counter these threats, we propose GuardFed, a self-adaptive defense framework that maintains a fairness-aware reference model using a small amount of clean server data augmented with synthetic samples. In each training round, GuardFed computes a dual-perspective trust score for every client by jointly evaluating its utility deviation and fairness degradation, thereby enabling selective aggregation of trustworthy updates. Extensive experiments on real-world datasets demonstrate that GuardFed consistently preserves both accuracy and fairness under diverse non-IID and adversarial conditions, achieving state-of-the-art performance compared with existing robust FL methods.
Clustering-based Anomaly Detection in Multivariate Time Series Data
Nov 11, 2025



Multivariate time series data come as a collection of time series describing different aspects of a certain temporal phenomenon. Anomaly detection in this type of data constitutes a challenging problem yet with numerous applications in science and engineering because anomaly scores come from the simultaneous consideration of the temporal and variable relationships. In this paper, we propose a clustering-based approach to detect anomalies concerning the amplitude and the shape of multivariate time series. First, we use a sliding window to generate a set of multivariate subsequences and thereafter apply an extended fuzzy clustering to reveal a structure present within the generated multivariate subsequences. Finally, a reconstruction criterion is employed to reconstruct the multivariate subsequences with the optimal cluster centers and the partition matrix. We construct a confidence index to quantify a level of anomaly detected in the series and apply Particle Swarm Optimization as an optimization vehicle for the problem of anomaly detection. Experimental studies completed on several synthetic and six real-world datasets suggest that the proposed methods can detect the anomalies in multivariate time series. With the help of available clusters revealed by the extended fuzzy clustering, the proposed framework can detect anomalies in the multivariate time series and is suitable for identifying anomalous amplitude and shape patterns in various application domains such as health care, weather data analysis, finance, and disease outbreak detection.
* 33 pages, 20 figures
An Integrated Fusion Framework for Ensemble Learning Leveraging Gradient Boosting and Fuzzy Rule-Based Models
Nov 11, 2025The integration of different learning paradigms has long been a focus of machine learning research, aimed at overcoming the inherent limitations of individual methods. Fuzzy rule-based models excel in interpretability and have seen widespread application across diverse fields. However, they face challenges such as complex design specifications and scalability issues with large datasets. The fusion of different techniques and strategies, particularly Gradient Boosting, with Fuzzy Rule-Based Models offers a robust solution to these challenges. This paper proposes an Integrated Fusion Framework that merges the strengths of both paradigms to enhance model performance and interpretability. At each iteration, a Fuzzy Rule-Based Model is constructed and controlled by a dynamic factor to optimize its contribution to the overall ensemble. This control factor serves multiple purposes: it prevents model dominance, encourages diversity, acts as a regularization parameter, and provides a mechanism for dynamic tuning based on model performance, thus mitigating the risk of overfitting. Additionally, the framework incorporates a sample-based correction mechanism that allows for adaptive adjustments based on feedback from a validation set. Experimental results substantiate the efficacy of the presented gradient boosting framework for fuzzy rule-based models, demonstrating performance enhancement, especially in terms of mitigating overfitting and complexity typically associated with many rules. By leveraging an optimal factor to govern the contribution of each model, the framework improves performance, maintains interpretability, and simplifies the maintenance and update of the models.
Multivariate Time series Anomaly Detection:A Framework of Hidden Markov Models
Nov 11, 2025In this study, we develop an approach to multivariate time series anomaly detection focused on the transformation of multivariate time series to univariate time series. Several transformation techniques involving Fuzzy C-Means (FCM) clustering and fuzzy integral are studied. In the sequel, a Hidden Markov Model (HMM), one of the commonly encountered statistical methods, is engaged here to detect anomalies in multivariate time series. We construct HMM-based anomaly detectors and in this context compare several transformation methods. A suite of experimental studies along with some comparative analysis is reported.
* 25 pages, 8 figures, 6 tables
HyColor: An Efficient Heuristic Algorithm for Graph Coloring
Jun 09, 2025



The graph coloring problem (GCP) is a classic combinatorial optimization problem that aims to find the minimum number of colors assigned to vertices of a graph such that no two adjacent vertices receive the same color. GCP has been extensively studied by researchers from various fields, including mathematics, computer science, and biological science. Due to the NP-hard nature, many heuristic algorithms have been proposed to solve GCP. However, existing GCP algorithms focus on either small hard graphs or large-scale sparse graphs (with up to 10^7 vertices). This paper presents an efficient hybrid heuristic algorithm for GCP, named HyColor, which excels in handling large-scale sparse graphs while achieving impressive results on small dense graphs. The efficiency of HyColor comes from the following three aspects: a local decision strategy to improve the lower bound on the chromatic number; a graph-reduction strategy to reduce the working graph; and a k-core and mixed degree-based greedy heuristic for efficiently coloring graphs. HyColor is evaluated against three state-of-the-art GCP algorithms across four benchmarks, comprising three large-scale sparse graph benchmarks and one small dense graph benchmark, totaling 209 instances. The results demonstrate that HyColor consistently outperforms existing heuristic algorithms in both solution accuracy and computational efficiency for the majority of instances. Notably, HyColor achieved the best solutions in 194 instances (over 93%), with 34 of these solutions significantly surpassing those of other algorithms. Furthermore, HyColor successfully determined the chromatic number and achieved optimal coloring in 128 instances.
MAMBO-NET: Multi-Causal Aware Modeling Backdoor-Intervention Optimization for Medical Image Segmentation Network
May 28, 2025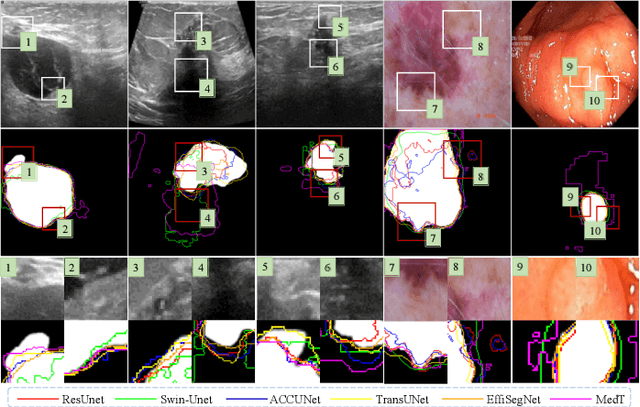
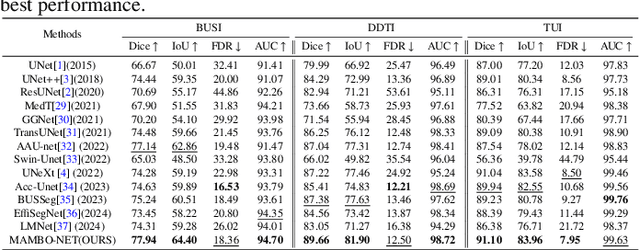
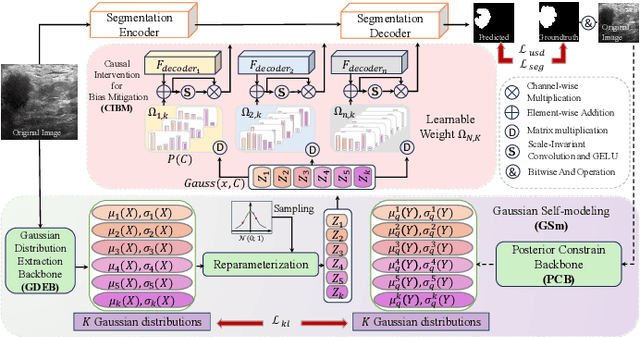
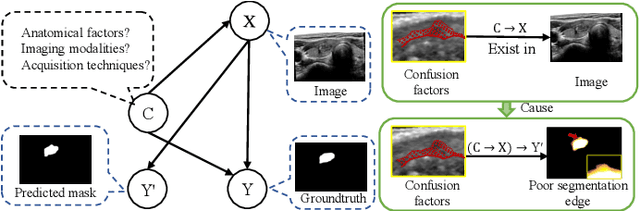
Medical image segmentation methods generally assume that the process from medical image to segmentation is unbiased, and use neural networks to establish conditional probability models to complete the segmentation task. This assumption does not consider confusion factors, which can affect medical images, such as complex anatomical variations and imaging modality limitations. Confusion factors obfuscate the relevance and causality of medical image segmentation, leading to unsatisfactory segmentation results. To address this issue, we propose a multi-causal aware modeling backdoor-intervention optimization (MAMBO-NET) network for medical image segmentation. Drawing insights from causal inference, MAMBO-NET utilizes self-modeling with multi-Gaussian distributions to fit the confusion factors and introduce causal intervention into the segmentation process. Moreover, we design appropriate posterior probability constraints to effectively train the distributions of confusion factors. For the distributions to effectively guide the segmentation and mitigate and eliminate the Impact of confusion factors on the segmentation, we introduce classical backdoor intervention techniques and analyze their feasibility in the segmentation task. To evaluate the effectiveness of our approach, we conducted extensive experiments on five medical image datasets. The results demonstrate that our method significantly reduces the influence of confusion factors, leading to enhanced segmentation accuracy.