 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAMASSU: Streaming Language-Agnostic Multilingual Speech Recognition and Translation Using Neural Transducers
Nov 05, 2022



End-to-end formulation of automatic speech recognition (ASR) and speech translation (ST) makes it easy to use a single model for both multilingual ASR and many-to-many ST. In this paper, we propose streaming language-agnostic multilingual speech recognition and translation using neural transducers (LAMASSU). To enable multilingual text generation in LAMASSU, we conduct a systematic comparison between specified and unified prediction and joint networks. We leverage a language-agnostic multilingual encoder that substantially outperforms shared encoders. To enhance LAMASSU, we propose to feed target LID to encoders. We also apply connectionist temporal classification regularization to transducer training. Experimental results show that LAMASSU not only drastically reduces the model size but also outperforms monolingual ASR and bilingual ST models.
Two-Stream Network for Sign Language Recognition and Translation
Nov 02, 2022



Sign languages are visual languages using manual articulations and non-manual elements to convey information. For sign language recognition and translation, the majority of existing approaches directly encode RGB videos into hidden representations. RGB videos, however, are raw signals with substantial visual redundancy, leading the encoder to overlook the key information for sign language understanding. To mitigate this problem and better incorporate domain knowledge, such as handshape and body movement, we introduce a dual visual encoder containing two separate streams to model both the raw videos and the keypoint sequences generated by an off-the-shelf keypoint estimator. To make the two streams interact with each other, we explore a variety of techniques, including bidirectional lateral connection, sign pyramid network with auxiliary supervision, and frame-level self-distillation. The resulting model is called TwoStream-SLR, which is competent for sign language recognition (SLR). TwoStream-SLR is extended to a sign language translation (SLT) model, TwoStream-SLT, by simply attaching an extra translation network. Experimentally, our TwoStream-SLR and TwoStream-SLT achieve state-of-the-art performance on SLR and SLT tasks across a series of datasets including Phoenix-2014, Phoenix-2014T, and CSL-Daily.
Real-time Speech Interruption Analysis: From Cloud to Client Deployment
Oct 24, 2022Meetings are an essential form of communication for all types of organizations, and remote collaboration systems have been much more widely used since the COVID-19 pandemic. One major issue with remote meetings is that it is challenging for remote participants to interrupt and speak. We have recently developed the first speech interruption analysis model, which detects failed speech interruptions, shows very promising performance, and is being deployed in the cloud. To deliver this feature in a more cost-efficient and environment-friendly way, we reduced the model complexity and size to ship the WavLM_SI model in client devices. In this paper, we first describe how we successfully improved the True Positive Rate (TPR) at a 1% False Positive Rate (FPR) from 50.9% to 68.3% for the failed speech interruption detection model by training on a larger dataset and fine-tuning. We then shrank the model size from 222.7 MB to 9.3 MB with an acceptable loss in accuracy and reduced the complexity from 31.2 GMACS (Giga Multiply-Accumulate Operations per Second) to 4.3 GMACS. We also estimated the environmental impact of the complexity reduction, which can be used as a general guideline for large Transformer-based models, and thus make those models more accessible with less computation overhead.
Foundation Transformers
Oct 19, 2022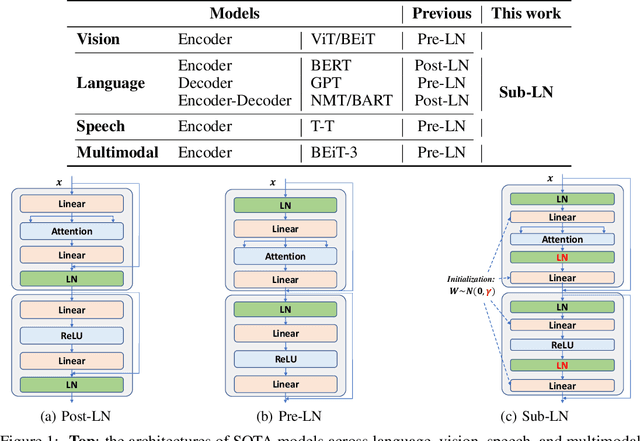
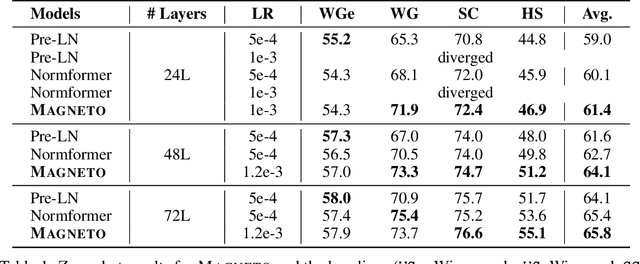
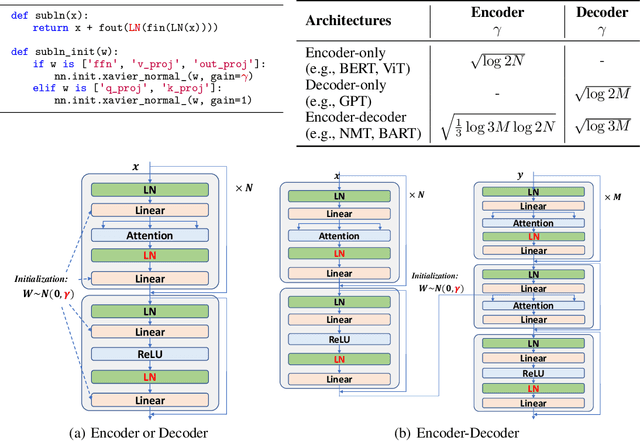
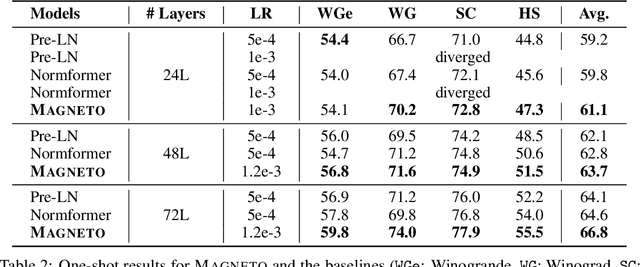
A big convergence of model architectures across language, vision, speech, and multimodal is emerging. However, under the same name "Transformers", the above areas use different implementations for better performance, e.g., Post-LayerNorm for BERT, and Pre-LayerNorm for GPT and vision Transformers. We call for the development of Foundation Transformer for true general-purpose modeling, which serves as a go-to architecture for various tasks and modalities with guaranteed training stability. In this work, we introduce a Transformer variant, named Magneto, to fulfill the goal. Specifically, we propose Sub-LayerNorm for good expressivity, and the initialization strategy theoretically derived from DeepNet for stable scaling up. Extensive experiments demonstrate its superior performance and better stability than the de facto Transformer variants designed for various applications, including language modeling (i.e., BERT, and GPT), machine translation, vision pretraining (i.e., BEiT), speech recognition, and multimodal pretraining (i.e., BEiT-3).
STAR: Zero-Shot Chinese Character Recognition with Stroke- and Radical-Level Decompositions
Oct 16, 2022
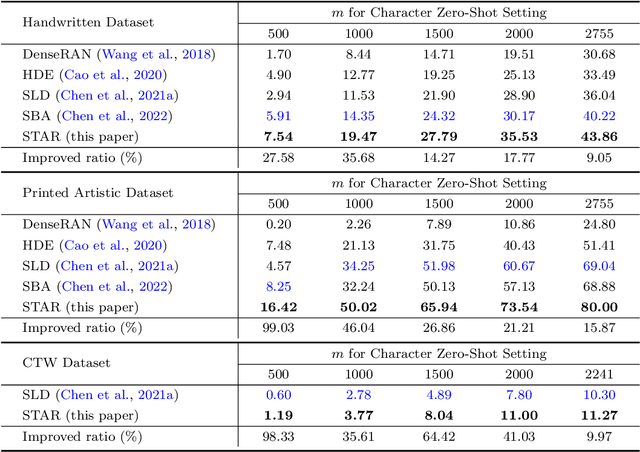
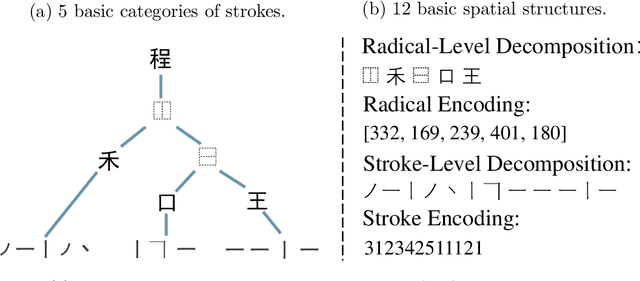
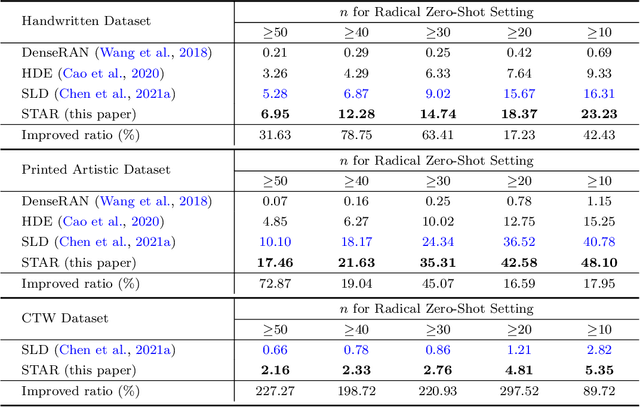
Zero-shot Chinese character recognition has attracted rising attention in recent years. Existing methods for this problem are mainly based on either certain low-level stroke-based decomposition or medium-level radical-based decomposition. Considering that the stroke- and radical-level decompositions can provide different levels of information, we propose an effective zero-shot Chinese character recognition method by combining them. The proposed method consists of a training stage and an inference stage. In the training stage, we adopt two similar encoder-decoder models to yield the estimates of stroke and radical encodings, which together with the true encodings are then used to formalize the associated stroke and radical losses for training. A similarity loss is introduced to regularize stroke and radical encoders to yield features of the same characters with high correlation. In the inference stage, two key modules, i.e., the stroke screening module (SSM) and feature matching module (FMM) are introduced to tackle the deterministic and confusing cases respectively. In particular, we introduce an effective stroke rectification scheme in FMM to enlarge the candidate set of characters for final inference. Numerous experiments over three benchmark datasets covering the handwritten, printed artistic and street view scenarios are conducted to demonstrate the effectiveness of the proposed method. Numerical results show that the proposed method outperforms the state-of-the-art methods in both character and radical zero-shot settings, and maintains competitive performance in the traditional seen character setting.
Vision+X: A Survey on Multimodal Learning in the Light of Data
Oct 05, 2022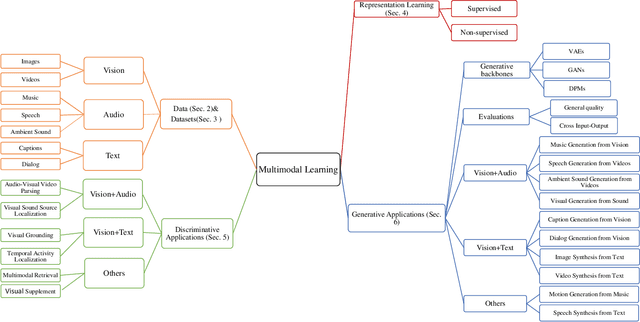

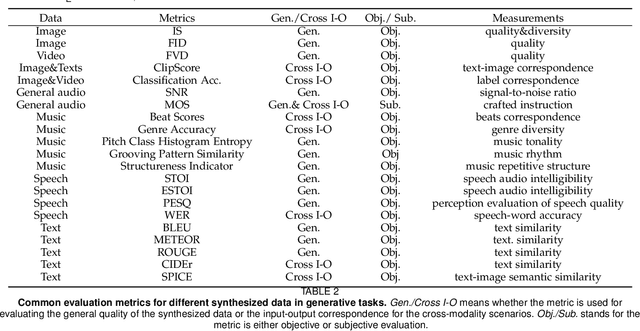
We are perceiving and communicating with the world in a multisensory manner, where different information sources are sophisticatedly processed and interpreted by separate parts of the human brain to constitute a complex, yet harmonious and unified sensing system. To endow the machines with true intelligence, the multimodal machine learning that incorporates data from various modalities has become an increasingly popular research area with emerging technical advances in recent years. In this paper, we present a survey on multimodal machine learning from a novel perspective considering not only the purely technical aspects but also the nature of different data modalities. We analyze the commonness and uniqueness of each data format ranging from vision, audio, text and others, and then present the technical development categorized by the combination of Vision+X, where the vision data play a fundamental role in most multimodal learning works. We investigate the existing literature on multimodal learning from both the representation learning and downstream application levels, and provide an additional comparison in the light of their technical connections with the data nature, e.g., the semantic consistency between image objects and textual descriptions, or the rhythm correspondence between video dance moves and musical beats. The exploitation of the alignment, as well as the existing gap between the intrinsic nature of data modality and the technical designs, will benefit future research studies to better address and solve a specific challenge related to the concrete multimodal task, and to prompt a unified multimodal machine learning framework closer to a real human intelligence system.
SpeechLM: Enhanced Speech Pre-Training with Unpaired Textual Data
Sep 30, 2022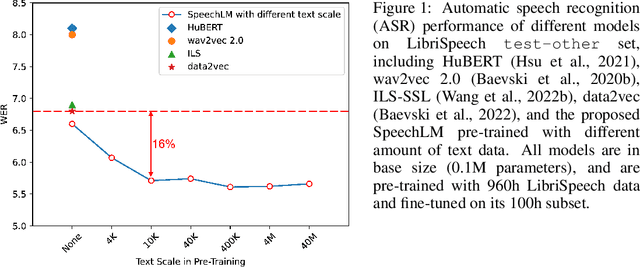
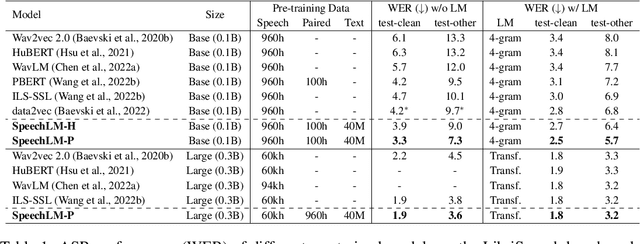
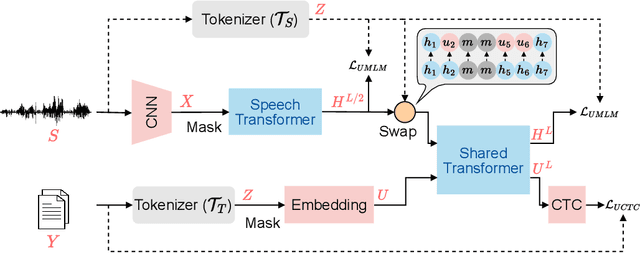
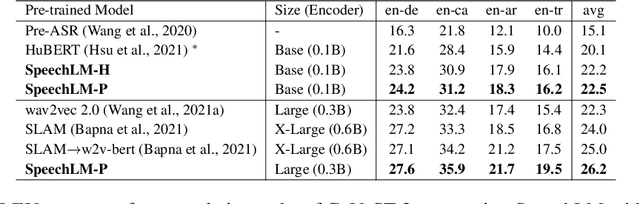
How to boost speech pre-training with textual data is an unsolved problem due to the fact that speech and text are very different modalities with distinct characteristics. In this paper, we propose a cross-modal Speech and Language Model (SpeechLM) to explicitly align speech and text pre-training with a pre-defined unified discrete representation. Specifically, we introduce two alternative discrete tokenizers to bridge the speech and text modalities, including phoneme-unit and hidden-unit tokenizers, which can be trained using a small amount of paired speech-text data. Based on the trained tokenizers, we convert the unlabeled speech and text data into tokens of phoneme units or hidden units. The pre-training objective is designed to unify the speech and the text into the same discrete semantic space with a unified Transformer network. Leveraging only 10K text sentences, our SpeechLM gets a 16\% relative WER reduction over the best base model performance (from 6.8 to 5.7) on the public LibriSpeech ASR benchmark. Moreover, SpeechLM with fewer parameters even outperforms previous SOTA models on CoVoST-2 speech translation tasks. We also evaluate our SpeechLM on various spoken language processing tasks under the universal representation evaluation framework SUPERB, demonstrating significant improvements on content-related tasks. Our code and models are available at https://aka.ms/SpeechLM.
SiRi: A Simple Selective Retraining Mechanism for Transformer-based Visual Grounding
Jul 27, 2022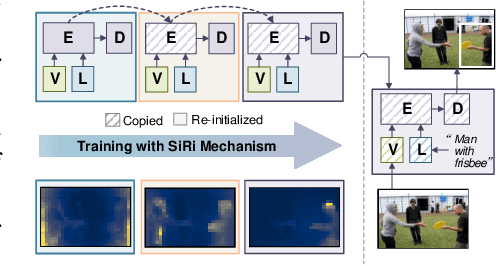
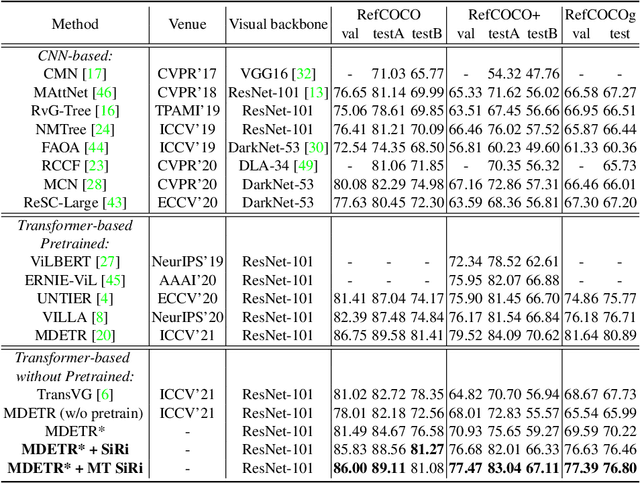
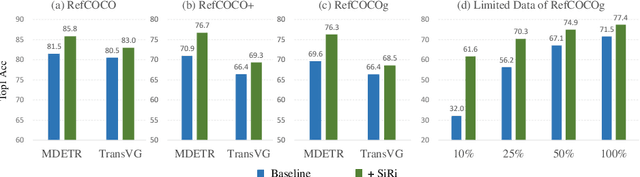
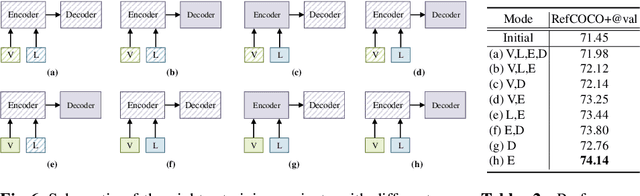
In this paper, we investigate how to achieve better visual grounding with modern vision-language transformers, and propose a simple yet powerful Selective Retraining (SiRi) mechanism for this challenging task. Particularly, SiRi conveys a significant principle to the research of visual grounding, i.e., a better initialized vision-language encoder would help the model converge to a better local minimum, advancing the performance accordingly. In specific, we continually update the parameters of the encoder as the training goes on, while periodically re-initialize rest of the parameters to compel the model to be better optimized based on an enhanced encoder. SiRi can significantly outperform previous approaches on three popular benchmarks. Specifically, our method achieves 83.04% Top1 accuracy on RefCOCO+ testA, outperforming the state-of-the-art approaches (training from scratch) by more than 10.21%. Additionally, we reveal that SiRi performs surprisingly superior even with limited training data. We also extend it to transformer-based visual grounding models and other vision-language tasks to verify the validity.
Provably Efficient Reinforcement Learning for Online Adaptive Influence Maximization
Jun 29, 2022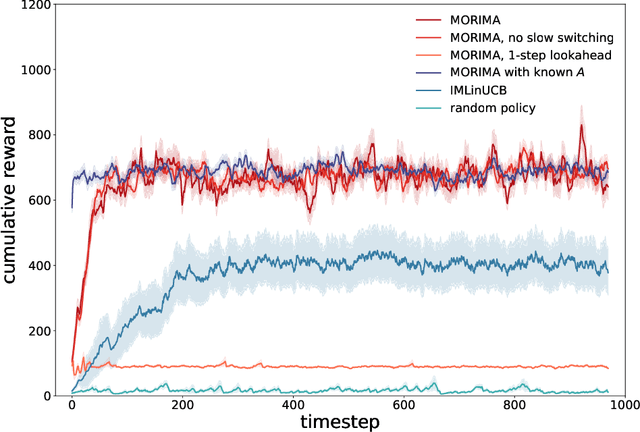
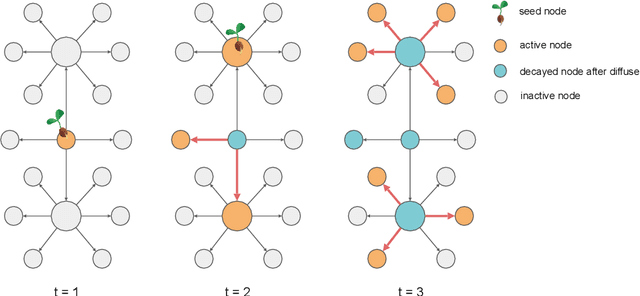
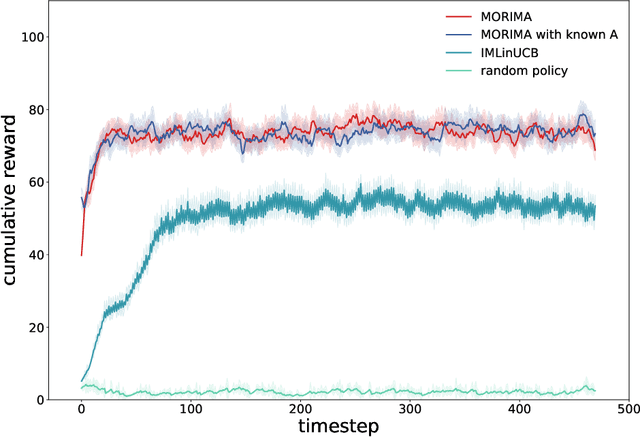
Online influence maximization aims to maximize the influence spread of a content in a social network with unknown network model by selecting a few seed nodes. Recent studies followed a non-adaptive setting, where the seed nodes are selected before the start of the diffusion process and network parameters are updated when the diffusion stops. We consider an adaptive version of content-dependent online influence maximization problem where the seed nodes are sequentially activated based on real-time feedback. In this paper, we formulate the problem as an infinite-horizon discounted MDP under a linear diffusion process and present a model-based reinforcement learning solution. Our algorithm maintains a network model estimate and selects seed users adaptively, exploring the social network while improving the optimal policy optimistically. We establish $\widetilde O(\sqrt{T})$ regret bound for our algorithm. Empirical evaluations on synthetic network demonstrate the efficiency of our algorithm.
Supervision-Guided Codebooks for Masked Prediction in Speech Pre-training
Jun 21, 2022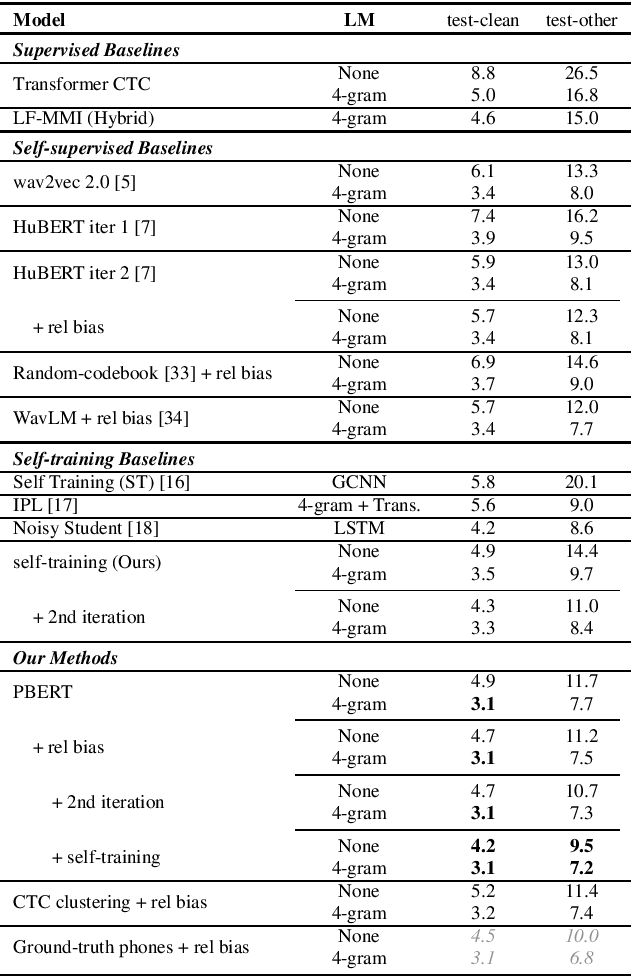
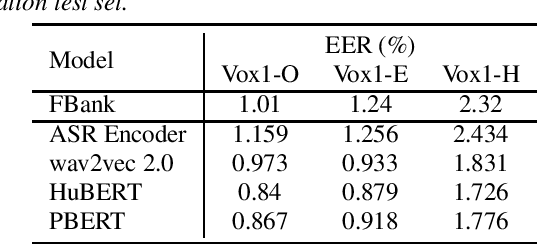
Recently, masked prediction pre-training has seen remarkable progress in self-supervised learning (SSL) for speech recognition. It usually requires a codebook obtained in an unsupervised way, making it less accurate and difficult to interpret. We propose two supervision-guided codebook generation approaches to improve automatic speech recognition (ASR) performance and also the pre-training efficiency, either through decoding with a hybrid ASR system to generate phoneme-level alignments (named PBERT), or performing clustering on the supervised speech features extracted from an end-to-end CTC model (named CTC clustering). Both the hybrid and CTC models are trained on the same small amount of labeled speech as used in fine-tuning. Experiments demonstrate significant superiority of our methods to various SSL and self-training baselines, with up to 17.0% relative WER reduction. Our pre-trained models also show good transferability in a non-ASR speech task.