 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Contrastive Learning Inspired by the Philosophy of "The Blind Men and the Elephant"
Dec 21, 2024



Contrastive learning is a prevalent technique in self-supervised vision representation learning, typically generating positive pairs by applying two data augmentations to the same image. Designing effective data augmentation strategies is crucial for the success of contrastive learning. Inspired by the story of the blind men and the elephant, we introduce JointCrop and JointBlur. These methods generate more challenging positive pairs by leveraging the joint distribution of the two augmentation parameters, thereby enabling contrastive learning to acquire more effective feature representations. To the best of our knowledge, this is the first effort to explicitly incorporate the joint distribution of two data augmentation parameters into contrastive learning. As a plug-and-play framework without additional computational overhead, JointCrop and JointBlur enhance the performance of SimCLR, BYOL, MoCo v1, MoCo v2, MoCo v3, SimSiam, and Dino baselines with notable improvements.
E-CAR: Efficient Continuous Autoregressive Image Generation via Multistage Modeling
Dec 19, 2024



Recent advances in autoregressive (AR) models with continuous tokens for image generation show promising results by eliminating the need for discrete tokenization. However, these models face efficiency challenges due to their sequential token generation nature and reliance on computationally intensive diffusion-based sampling. We present ECAR (Efficient Continuous Auto-Regressive Image Generation via Multistage Modeling), an approach that addresses these limitations through two intertwined innovations: (1) a stage-wise continuous token generation strategy that reduces computational complexity and provides progressively refined token maps as hierarchical conditions, and (2) a multistage flow-based distribution modeling method that transforms only partial-denoised distributions at each stage comparing to complete denoising in normal diffusion models. Holistically, ECAR operates by generating tokens at increasing resolutions while simultaneously denoising the image at each stage. This design not only reduces token-to-image transformation cost by a factor of the stage number but also enables parallel processing at the token level. Our approach not only enhances computational efficiency but also aligns naturally with image generation principles by operating in continuous token space and following a hierarchical generation process from coarse to fine details. Experimental results demonstrate that ECAR achieves comparable image quality to DiT Peebles & Xie [2023] while requiring 10$\times$ FLOPs reduction and 5$\times$ speedup to generate a 256$\times$256 image.
GUI Agents: A Survey
Dec 18, 2024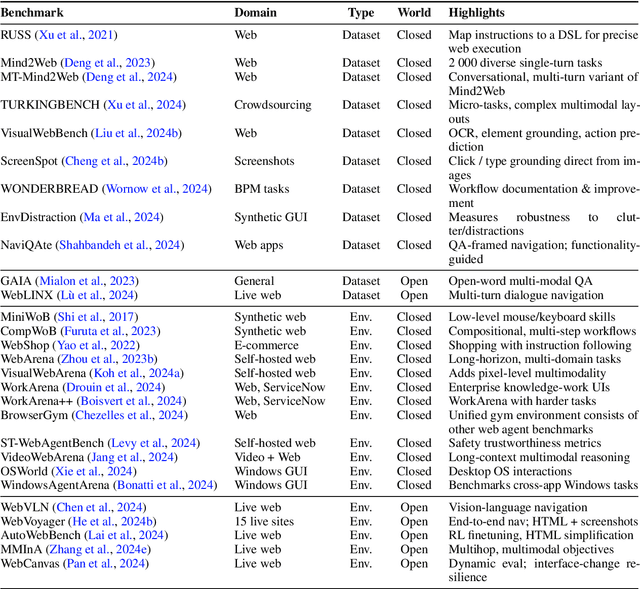
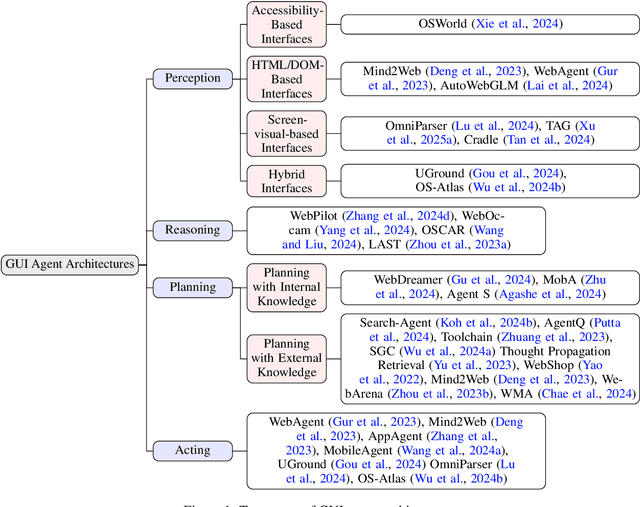

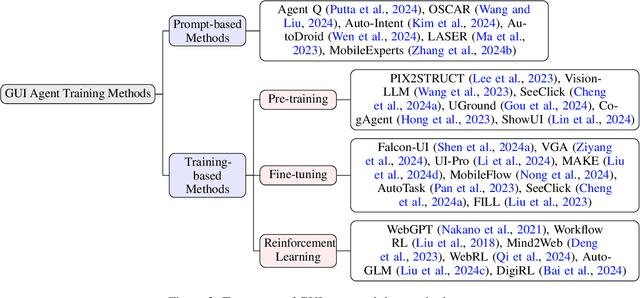
Graphical User Interface (GUI) agents, powered by Large Foundation Models, have emerged as a transformative approach to automating human-computer interaction. These agents autonomously interact with digital systems or software applications via GUIs, emulating human actions such as clicking, typing, and navigating visual elements across diverse platforms. Motivated by the growing interest and fundamental importance of GUI agents, we provide a comprehensive survey that categorizes their benchmarks, evaluation metrics, architectures, and training methods. We propose a unified framework that delineates their perception, reasoning, planning, and acting capabilities. Furthermore, we identify important open challenges and discuss key future directions. Finally, this work serves as a basis for practitioners and researchers to gain an intuitive understanding of current progress, techniques, benchmarks, and critical open problems that remain to be addressed.
What Matters in Learning A Zero-Shot Sim-to-Real RL Policy for Quadrotor Control? A Comprehensive Study
Dec 17, 2024Executing precise and agile flight maneuvers is critical for quadrotors in various applications. Traditional quadrotor control approaches are limited by their reliance on flat trajectories or time-consuming optimization, which restricts their flexibility. Recently, RL-based policy has emerged as a promising alternative due to its ability to directly map observations to actions, reducing the need for detailed system knowledge and actuation constraints. However, a significant challenge remains in bridging the sim-to-real gap, where RL-based policies often experience instability when deployed in real world. In this paper, we investigate key factors for learning robust RL-based control policies that are capable of zero-shot deployment in real-world quadrotors. We identify five critical factors and we develop a PPO-based training framework named SimpleFlight, which integrates these five techniques. We validate the efficacy of SimpleFlight on Crazyflie quadrotor, demonstrating that it achieves more than a 50% reduction in trajectory tracking error compared to state-of-the-art RL baselines, and achieves 70% improvement over the traditional MPC. The policy derived by SimpleFlight consistently excels across both smooth polynominal trajectories and challenging infeasible zigzag trajectories on small thrust-to-weight quadrotors. In contrast, baseline methods struggle with high-speed or infeasible trajectories. To support further research and reproducibility, we integrate SimpleFlight into a GPU-based simulator Omnidrones and provide open-source access to the code and model checkpoints. We hope SimpleFlight will offer valuable insights for advancing RL-based quadrotor control. For more details, visit our project website at https://sites.google.com/view/simpleflight/.
Drawing the Line: Enhancing Trustworthiness of MLLMs Through the Power of Refusal
Dec 15, 2024



Multimodal large language models (MLLMs) excel at multimodal perception and understanding, yet their tendency to generate hallucinated or inaccurate responses undermines their trustworthiness. Existing methods have largely overlooked the importance of refusal responses as a means of enhancing MLLMs reliability. To bridge this gap, we present the Information Boundary-aware Learning Framework (InBoL), a novel approach that empowers MLLMs to refuse to answer user queries when encountering insufficient information. To the best of our knowledge, InBoL is the first framework that systematically defines the conditions under which refusal is appropriate for MLLMs using the concept of information boundaries proposed in our paper. This framework introduces a comprehensive data generation pipeline and tailored training strategies to improve the model's ability to deliver appropriate refusal responses. To evaluate the trustworthiness of MLLMs, we further propose a user-centric alignment goal along with corresponding metrics. Experimental results demonstrate a significant improvement in refusal accuracy without noticeably compromising the model's helpfulness, establishing InBoL as a pivotal advancement in building more trustworthy MLLMs.
A4-Unet: Deformable Multi-Scale Attention Network for Brain Tumor Segmentation
Dec 08, 2024



Brain tumor segmentation models have aided diagnosis in recent years. However, they face MRI complexity and variability challenges, including irregular shapes and unclear boundaries, leading to noise, misclassification, and incomplete segmentation, thereby limiting accuracy. To address these issues, we adhere to an outstanding Convolutional Neural Networks (CNNs) design paradigm and propose a novel network named A4-Unet. In A4-Unet, Deformable Large Kernel Attention (DLKA) is incorporated in the encoder, allowing for improved capture of multi-scale tumors. Swin Spatial Pyramid Pooling (SSPP) with cross-channel attention is employed in a bottleneck further to study long-distance dependencies within images and channel relationships. To enhance accuracy, a Combined Attention Module (CAM) with Discrete Cosine Transform (DCT) orthogonality for channel weighting and convolutional element-wise multiplication is introduced for spatial weighting in the decoder. Attention gates (AG) are added in the skip connection to highlight the foreground while suppressing irrelevant background information. The proposed network is evaluated on three authoritative MRI brain tumor benchmarks and a proprietary dataset, and it achieves a 94.4% Dice score on the BraTS 2020 dataset, thereby establishing multiple new state-of-the-art benchmarks. The code is available here: https://github.com/WendyWAAAAANG/A4-Unet.
GenMAC: Compositional Text-to-Video Generation with Multi-Agent Collaboration
Dec 05, 2024



Text-to-video generation models have shown significant progress in the recent years. However, they still struggle with generating complex dynamic scenes based on compositional text prompts, such as attribute binding for multiple objects, temporal dynamics associated with different objects, and interactions between objects. Our key motivation is that complex tasks can be decomposed into simpler ones, each handled by a role-specialized MLLM agent. Multiple agents can collaborate together to achieve collective intelligence for complex goals. We propose GenMAC, an iterative, multi-agent framework that enables compositional text-to-video generation. The collaborative workflow includes three stages: Design, Generation, and Redesign, with an iterative loop between the Generation and Redesign stages to progressively verify and refine the generated videos. The Redesign stage is the most challenging stage that aims to verify the generated videos, suggest corrections, and redesign the text prompts, frame-wise layouts, and guidance scales for the next iteration of generation. To avoid hallucination of a single MLLM agent, we decompose this stage to four sequentially-executed MLLM-based agents: verification agent, suggestion agent, correction agent, and output structuring agent. Furthermore, to tackle diverse scenarios of compositional text-to-video generation, we design a self-routing mechanism to adaptively select the proper correction agent from a collection of correction agents each specialized for one scenario. Extensive experiments demonstrate the effectiveness of GenMAC, achieving state-of-the art performance in compositional text-to-video generation.
ASIGN: An Anatomy-aware Spatial Imputation Graphic Network for 3D Spatial Transcriptomics
Dec 04, 2024



Spatial transcriptomics (ST) is an emerging technology that enables medical computer vision scientists to automatically interpret the molecular profiles underlying morphological features. Currently, however, most deep learning-based ST analyses are limited to two-dimensional (2D) sections, which can introduce diagnostic errors due to the heterogeneity of pathological tissues across 3D sections. Expanding ST to three-dimensional (3D) volumes is challenging due to the prohibitive costs; a 2D ST acquisition already costs over 50 times more than whole slide imaging (WSI), and a full 3D volume with 10 sections can be an order of magnitude more expensive. To reduce costs, scientists have attempted to predict ST data directly from WSI without performing actual ST acquisition. However, these methods typically yield unsatisfying results. To address this, we introduce a novel problem setting: 3D ST imputation using 3D WSI histology sections combined with a single 2D ST slide. To do so, we present the Anatomy-aware Spatial Imputation Graph Network (ASIGN) for more precise, yet affordable, 3D ST modeling. The ASIGN architecture extends existing 2D spatial relationships into 3D by leveraging cross-layer overlap and similarity-based expansion. Moreover, a multi-level spatial attention graph network integrates features comprehensively across different data sources. We evaluated ASIGN on three public spatial transcriptomics datasets, with experimental results demonstrating that ASIGN achieves state-of-the-art performance on both 2D and 3D scenarios. Code is available at https://github.com/hrlblab/ASIGN.
Jailbreak Large Vision-Language Models Through Multi-Modal Linkage
Dec 03, 2024



With the significant advancement of Large Vision-Language Models (VLMs), concerns about their potential misuse and abuse have grown rapidly. Previous studies have highlighted VLMs' vulnerability to jailbreak attacks, where carefully crafted inputs can lead the model to produce content that violates ethical and legal standards. However, existing methods struggle against state-of-the-art VLMs like GPT-4o, due to the over-exposure of harmful content and lack of stealthy malicious guidance. In this work, we propose a novel jailbreak attack framework: Multi-Modal Linkage (MML) Attack. Drawing inspiration from cryptography, MML utilizes an encryption-decryption process across text and image modalities to mitigate over-exposure of malicious information. To align the model's output with malicious intent covertly, MML employs a technique called "evil alignment", framing the attack within a video game production scenario. Comprehensive experiments demonstrate MML's effectiveness. Specifically, MML jailbreaks GPT-4o with attack success rates of 97.80% on SafeBench, 98.81% on MM-SafeBench and 99.07% on HADES-Dataset. Our code is available at https://github.com/wangyu-ovo/MML
Personalized Multimodal Large Language Models: A Survey
Dec 03, 2024Multimodal Large Language Models (MLLMs) have become increasingly important due to their state-of-the-art performance and ability to integrate multiple data modalities, such as text, images, and audio, to perform complex tasks with high accuracy. This paper presents a comprehensive survey on personalized multimodal large language models, focusing on their architecture, training methods, and applications. We propose an intuitive taxonomy for categorizing the techniques used to personalize MLLMs to individual users, and discuss the techniques accordingly. Furthermore, we discuss how such techniques can be combined or adapted when appropriate, highlighting their advantages and underlying rationale. We also provide a succinct summary of personalization tasks investigated in existing research, along with the evaluation metrics commonly used. Additionally, we summarize the datasets that are useful for benchmarking personalized MLLMs. Finally, we outline critical open challenges. This survey aims to serve as a valuable resource for researchers and practitioners seeking to understand and advance the development of personalized multimodal large language models.