 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePySpatial: A High-Speed Whole Slide Image Pathomics Toolkit
Jan 10, 2025



Whole Slide Image (WSI) analysis plays a crucial role in modern digital pathology, enabling large-scale feature extraction from tissue samples. However, traditional feature extraction pipelines based on tools like CellProfiler often involve lengthy workflows, requiring WSI segmentation into patches, feature extraction at the patch level, and subsequent mapping back to the original WSI. To address these challenges, we present PySpatial, a high-speed pathomics toolkit specifically designed for WSI-level analysis. PySpatial streamlines the conventional pipeline by directly operating on computational regions of interest, reducing redundant processing steps. Utilizing rtree-based spatial indexing and matrix-based computation, PySpatial efficiently maps and processes computational regions, significantly accelerating feature extraction while maintaining high accuracy. Our experiments on two datasets-Perivascular Epithelioid Cell (PEC) and data from the Kidney Precision Medicine Project (KPMP)-demonstrate substantial performance improvements. For smaller and sparse objects in PEC datasets, PySpatial achieves nearly a 10-fold speedup compared to standard CellProfiler pipelines. For larger objects, such as glomeruli and arteries in KPMP datasets, PySpatial achieves a 2-fold speedup. These results highlight PySpatial's potential to handle large-scale WSI analysis with enhanced efficiency and accuracy, paving the way for broader applications in digital pathology.
Retrieval-Augmented Generation with Graphs (GraphRAG)
Jan 08, 2025



Retrieval-augmented generation (RAG) is a powerful technique that enhances downstream task execution by retrieving additional information, such as knowledge, skills, and tools from external sources. Graph, by its intrinsic "nodes connected by edges" nature, encodes massive heterogeneous and relational information, making it a golden resource for RAG in tremendous real-world applications. As a result, we have recently witnessed increasing attention on equipping RAG with Graph, i.e., GraphRAG. However, unlike conventional RAG, where the retriever, generator, and external data sources can be uniformly designed in the neural-embedding space, the uniqueness of graph-structured data, such as diverse-formatted and domain-specific relational knowledge, poses unique and significant challenges when designing GraphRAG for different domains. Given the broad applicability, the associated design challenges, and the recent surge in GraphRAG, a systematic and up-to-date survey of its key concepts and techniques is urgently desired. Following this motivation, we present a comprehensive and up-to-date survey on GraphRAG. Our survey first proposes a holistic GraphRAG framework by defining its key components, including query processor, retriever, organizer, generator, and data source. Furthermore, recognizing that graphs in different domains exhibit distinct relational patterns and require dedicated designs, we review GraphRAG techniques uniquely tailored to each domain. Finally, we discuss research challenges and brainstorm directions to inspire cross-disciplinary opportunities. Our survey repository is publicly maintained at https://github.com/Graph-RAG/GraphRAG/.
Holistic Semantic Representation for Navigational Trajectory Generation
Jan 06, 2025



Trajectory generation has garnered significant attention from researchers in the field of spatio-temporal analysis, as it can generate substantial synthesized human mobility trajectories that enhance user privacy and alleviate data scarcity. However, existing trajectory generation methods often focus on improving trajectory generation quality from a singular perspective, lacking a comprehensive semantic understanding across various scales. Consequently, we are inspired to develop a HOlistic SEmantic Representation (HOSER) framework for navigational trajectory generation. Given an origin-and-destination (OD) pair and the starting time point of a latent trajectory, we first propose a Road Network Encoder to expand the receptive field of road- and zone-level semantics. Second, we design a Multi-Granularity Trajectory Encoder to integrate the spatio-temporal semantics of the generated trajectory at both the point and trajectory levels. Finally, we employ a Destination-Oriented Navigator to seamlessly integrate destination-oriented guidance. Extensive experiments on three real-world datasets demonstrate that HOSER outperforms state-of-the-art baselines by a significant margin. Moreover, the model's performance in few-shot learning and zero-shot learning scenarios further verifies the effectiveness of our holistic semantic representation.
Towards Omni-RAG: Comprehensive Retrieval-Augmented Generation for Large Language Models in Medical Applications
Jan 05, 2025



Large language models (LLMs) hold promise for addressing healthcare challenges but often generate hallucinations due to limited integration of medical knowledge. Incorporating external medical knowledge is therefore critical, especially considering the breadth and complexity of medical content, which necessitates effective multi-source knowledge acquisition. We address this challenge by framing it as a source planning problem, where the task is to formulate context-appropriate queries tailored to the attributes of diverse knowledge sources. Existing approaches either overlook source planning or fail to achieve it effectively due to misalignment between the model's expectation of the sources and their actual content. To bridge this gap, we present MedOmniKB, a comprehensive repository comprising multigenre and multi-structured medical knowledge sources. Leveraging these sources, we propose the Source Planning Optimisation (SPO) method, which enhances multi-source utilisation through explicit planning optimisation. Our approach involves enabling an expert model to explore and evaluate potential plans while training a smaller model to learn source alignment using positive and negative planning samples. Experimental results demonstrate that our method substantially improves multi-source planning performance, enabling the optimised small model to achieve state-of-the-art results in leveraging diverse medical knowledge sources.
Personalized Graph-Based Retrieval for Large Language Models
Jan 04, 2025As large language models (LLMs) evolve, their ability to deliver personalized and context-aware responses offers transformative potential for improving user experiences. Existing personalization approaches, however, often rely solely on user history to augment the prompt, limiting their effectiveness in generating tailored outputs, especially in cold-start scenarios with sparse data. To address these limitations, we propose Personalized Graph-based Retrieval-Augmented Generation (PGraphRAG), a framework that leverages user-centric knowledge graphs to enrich personalization. By directly integrating structured user knowledge into the retrieval process and augmenting prompts with user-relevant context, PGraphRAG enhances contextual understanding and output quality. We also introduce the Personalized Graph-based Benchmark for Text Generation, designed to evaluate personalized text generation tasks in real-world settings where user history is sparse or unavailable. Experimental results show that PGraphRAG significantly outperforms state-of-the-art personalization methods across diverse tasks, demonstrating the unique advantages of graph-based retrieval for personalization.
Cold-Start Recommendation towards the Era of Large Language Models (LLMs): A Comprehensive Survey and Roadmap
Jan 03, 2025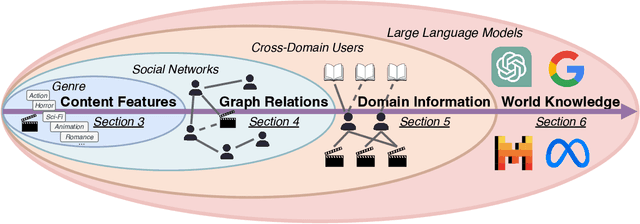
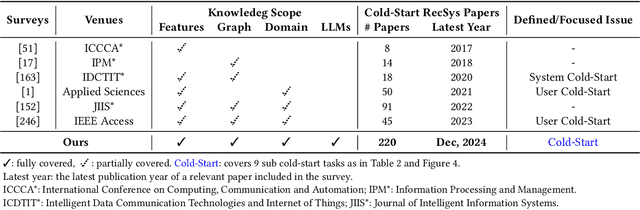
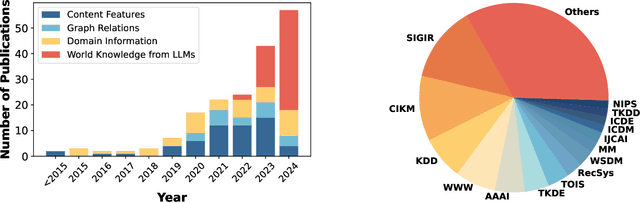
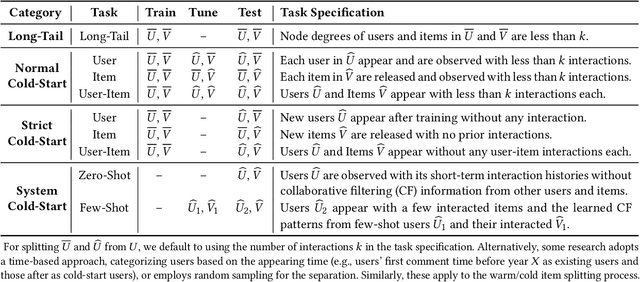
Cold-start problem is one of the long-standing challenges in recommender systems, focusing on accurately modeling new or interaction-limited users or items to provide better recommendations. Due to the diversification of internet platforms and the exponential growth of users and items, the importance of cold-start recommendation (CSR) is becoming increasingly evident. At the same time, large language models (LLMs) have achieved tremendous success and possess strong capabilities in modeling user and item information, providing new potential for cold-start recommendations. However, the research community on CSR still lacks a comprehensive review and reflection in this field. Based on this, in this paper, we stand in the context of the era of large language models and provide a comprehensive review and discussion on the roadmap, related literature, and future directions of CSR. Specifically, we have conducted an exploration of the development path of how existing CSR utilizes information, from content features, graph relations, and domain information, to the world knowledge possessed by large language models, aiming to provide new insights for both the research and industrial communities on CSR. Related resources of cold-start recommendations are collected and continuously updated for the community in https://github.com/YuanchenBei/Awesome-Cold-Start-Recommendation.
FrameFusion: Combining Similarity and Importance for Video Token Reduction on Large Visual Language Models
Dec 30, 2024
The increasing demand to process long and high-resolution videos significantly burdens Large Vision-Language Models (LVLMs) due to the enormous number of visual tokens. Existing token reduction methods primarily focus on importance-based token pruning, which overlooks the redundancy caused by frame resemblance and repetitive visual elements. In this paper, we analyze the high vision token similarities in LVLMs. We reveal that token similarity distribution condenses as layers deepen while maintaining ranking consistency. Leveraging the unique properties of similarity over importance, we introduce FrameFusion, a novel approach that combines similarity-based merging with importance-based pruning for better token reduction in LVLMs. FrameFusion identifies and merges similar tokens before pruning, opening up a new perspective for token reduction. We evaluate FrameFusion on diverse LVLMs, including Llava-Video-{7B,32B,72B}, and MiniCPM-V-8B, on video understanding, question-answering, and retrieval benchmarks. Experiments show that FrameFusion reduces vision tokens by 70$\%$, achieving 3.4-4.4x LLM speedups and 1.6-1.9x end-to-end speedups, with an average performance impact of less than 3$\%$. Our code is available at https://github.com/thu-nics/FrameFusion.
MBQ: Modality-Balanced Quantization for Large Vision-Language Models
Dec 27, 2024



Vision-Language Models (VLMs) have enabled a variety of real-world applications. The large parameter size of VLMs brings large memory and computation overhead which poses significant challenges for deployment. Post-Training Quantization (PTQ) is an effective technique to reduce the memory and computation overhead. Existing PTQ methods mainly focus on large language models (LLMs), without considering the differences across other modalities. In this paper, we discover that there is a significant difference in sensitivity between language and vision tokens in large VLMs. Therefore, treating tokens from different modalities equally, as in existing PTQ methods, may over-emphasize the insensitive modalities, leading to significant accuracy loss. To deal with the above issue, we propose a simple yet effective method, Modality-Balanced Quantization (MBQ), for large VLMs. Specifically, MBQ incorporates the different sensitivities across modalities during the calibration process to minimize the reconstruction loss for better quantization parameters. Extensive experiments show that MBQ can significantly improve task accuracy by up to 4.4% and 11.6% under W3 and W4A8 quantization for 7B to 70B VLMs, compared to SOTA baselines. Additionally, we implement a W3 GPU kernel that fuses the dequantization and GEMV operators, achieving a 1.4x speedup on LLaVA-onevision-7B on the RTX 4090. The code is available at https://github.com/thu-nics/MBQ.
MR-COGraphs: Communication-efficient Multi-Robot Open-vocabulary Mapping System via 3D Scene Graphs
Dec 24, 2024Collaborative perception in unknown environments is crucial for multi-robot systems. With the emergence of foundation models, robots can now not only perceive geometric information but also achieve open-vocabulary scene understanding. However, existing map representations that support open-vocabulary queries often involve large data volumes, which becomes a bottleneck for multi-robot transmission in communication-limited environments. To address this challenge, we develop a method to construct a graph-structured 3D representation called COGraph, where nodes represent objects with semantic features and edges capture their spatial relationships. Before transmission, a data-driven feature encoder is applied to compress the feature dimensions of the COGraph. Upon receiving COGraphs from other robots, the semantic features of each node are recovered using a decoder. We also propose a feature-based approach for place recognition and translation estimation, enabling the merging of local COGraphs into a unified global map. We validate our framework using simulation environments built on Isaac Sim and real-world datasets. The results demonstrate that, compared to transmitting semantic point clouds and 512-dimensional COGraphs, our framework can reduce the data volume by two orders of magnitude, without compromising mapping and query performance. For more details, please visit our website at https://github.com/efc-robot/MR-COGraphs.
Distilled Decoding 1: One-step Sampling of Image Auto-regressive Models with Flow Matching
Dec 24, 2024Autoregressive (AR) models have achieved state-of-the-art performance in text and image generation but suffer from slow generation due to the token-by-token process. We ask an ambitious question: can a pre-trained AR model be adapted to generate outputs in just one or two steps? If successful, this would significantly advance the development and deployment of AR models. We notice that existing works that try to speed up AR generation by generating multiple tokens at once fundamentally cannot capture the output distribution due to the conditional dependencies between tokens, limiting their effectiveness for few-step generation. To address this, we propose Distilled Decoding (DD), which uses flow matching to create a deterministic mapping from Gaussian distribution to the output distribution of the pre-trained AR model. We then train a network to distill this mapping, enabling few-step generation. DD doesn't need the training data of the original AR model, making it more practical. We evaluate DD on state-of-the-art image AR models and present promising results on ImageNet-256. For VAR, which requires 10-step generation, DD enables one-step generation (6.3$\times$ speed-up), with an acceptable increase in FID from 4.19 to 9.96. For LlamaGen, DD reduces generation from 256 steps to 1, achieving an 217.8$\times$ speed-up with a comparable FID increase from 4.11 to 11.35. In both cases, baseline methods completely fail with FID>100. DD also excels on text-to-image generation, reducing the generation from 256 steps to 2 for LlamaGen with minimal FID increase from 25.70 to 28.95. As the first work to demonstrate the possibility of one-step generation for image AR models, DD challenges the prevailing notion that AR models are inherently slow, and opens up new opportunities for efficient AR generation. The project website is at https://imagination-research.github.io/distilled-decoding.