 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Decoder Adapter: ID-Preserving Tokenizer Adaption for Autoregressive Text Rendering
Jun 01, 2026Visual Autoregressive (AR) models generate images by predicting discrete tokens that are decoded by a visual tokenizer. Despite demonstrating strong overall image generation ability, they still underperform on text rendering with blur strokes and disrupt letter shapes. In this work, we trace this limitation to the visual tokenizer, which struggles to reconstruct fine-grained detail. Improving the tokenizer is straightforward but expensive, as it necessitates retraining both the tokenizer and the AR model. Can we improve text rendering performance of AR models without retraining the existing tokenizer and AR model? To achieve this, we propose the Residual Decoder Adapter(RDA) that upgrades an existing tokenizer post-hoc without changing its token space. Specifically, it refines the decoder output of the visual tokenizer by introducing two novel components: (i) a paired codebook that shares the token distribution with the original one; (ii) a parallel branch to learn the tiny differences (residual) between the reconstructed image and the ground-truth images in the pixel space. This residual design allows us to enhance the tokenizer non-invasively while preserving compatibility with prior AR models. RDA substantially improves text rendering significantly by a large margin. For instance, we boost finetuned Janus-Pro OCR accuracy rises from 24.52% to 58.26% (TextVisionBlend), from 12.75% to 36.81% (StyledTextSynth) on competitive TextAtlas benchmark. The code is available at https://github.com/CSU-JPG/RDA
A geometry aware framework enhances noninvasive mapping of whole human brain dynamics
Apr 28, 2026Non-invasive electrophysiology lacks methods that accurately reconstruct whole-brain spatiotemporal dynamics while incorporating individual cortical geometry, leaving current electroencephalography and magnetoencephalography source imaging limited by simplistic or biologically implausible priors. Here, we show that embedding participant-specific Geometric Basis Functions (GBFs), eigenmodes derived from each individual's cortical surface, provides a powerful anatomic constraint that resolves the inverse problem and improves reconstruction fidelity. The method reconstructs neural sources as linear combinations of geometric basis functions, thereby aligning source estimates with the geometric organization of neural dynamics. We validate GBF across the Meta-Source Benchmark, task-evoked data, resting-state networks, intracranial stimulation, and epilepsy data. The results demonstrate that GBF yields high localization accuracy and captures fast spatiotemporal dynamics consistent with anatomical pathways. These findings suggest that both spontaneous and evoked whole-brain activity can be described by hundreds of geometric modes, providing a compact yet accurate representation of neural sources. By linking cortical geometry to electrophysiological dynamics, GBF offers a versatile source imaging tool for both scientific and clinical applications.
FlowInOne:Unifying Multimodal Generation as Image-in, Image-out Flow Matching
Apr 08, 2026Multimodal generation has long been dominated by text-driven pipelines where language dictates vision but cannot reason or create within it. We challenge this paradigm by asking whether all modalities, including textual descriptions, spatial layouts, and editing instructions, can be unified into a single visual representation. We present FlowInOne, a framework that reformulates multimodal generation as a purely visual flow, converting all inputs into visual prompts and enabling a clean image-in, image-out pipeline governed by a single flow matching model. This vision-centric formulation naturally eliminates cross-modal alignment bottlenecks, noise scheduling, and task-specific architectural branches, unifying text-to-image generation, layout-guided editing, and visual instruction following under one coherent paradigm. To support this, we introduce VisPrompt-5M, a large-scale dataset of 5 million visual prompt pairs spanning diverse tasks including physics-aware force dynamics and trajectory prediction, alongside VP-Bench, a rigorously curated benchmark assessing instruction faithfulness, spatial precision, visual realism, and content consistency. Extensive experiments demonstrate that FlowInOne achieves state-of-the-art performance across all unified generation tasks, surpassing both open-source models and competitive commercial systems, establishing a new foundation for fully vision-centric generative modeling where perception and creation coexist within a single continuous visual space.
ArtiSG: Functional 3D Scene Graph Construction via Human-demonstrated Articulated Objects Manipulation
Dec 31, 20253D scene graphs have empowered robots with semantic understanding for navigation and planning, yet they often lack the functional information required for physical manipulation, particularly regarding articulated objects. Existing approaches for inferring articulation mechanisms from static observations are prone to visual ambiguity, while methods that estimate parameters from state changes typically rely on constrained settings such as fixed cameras and unobstructed views. Furthermore, fine-grained functional elements like small handles are frequently missed by general object detectors. To bridge this gap, we present ArtiSG, a framework that constructs functional 3D scene graphs by encoding human demonstrations into structured robotic memory. Our approach leverages a robust articulation data collection pipeline utilizing a portable setup to accurately estimate 6-DoF articulation trajectories and axes even under camera ego-motion. We integrate these kinematic priors into a hierarchical and open-vocabulary graph while utilizing interaction data to discover inconspicuous functional elements missed by visual perception. Extensive real-world experiments demonstrate that ArtiSG significantly outperforms baselines in functional element recall and articulation estimation precision. Moreover, we show that the constructed graph serves as a reliable functional memory that effectively guides robots to perform language-directed manipulation tasks in real-world environments containing diverse articulated objects.
MR-COGraphs: Communication-efficient Multi-Robot Open-vocabulary Mapping System via 3D Scene Graphs
Dec 24, 2024Collaborative perception in unknown environments is crucial for multi-robot systems. With the emergence of foundation models, robots can now not only perceive geometric information but also achieve open-vocabulary scene understanding. However, existing map representations that support open-vocabulary queries often involve large data volumes, which becomes a bottleneck for multi-robot transmission in communication-limited environments. To address this challenge, we develop a method to construct a graph-structured 3D representation called COGraph, where nodes represent objects with semantic features and edges capture their spatial relationships. Before transmission, a data-driven feature encoder is applied to compress the feature dimensions of the COGraph. Upon receiving COGraphs from other robots, the semantic features of each node are recovered using a decoder. We also propose a feature-based approach for place recognition and translation estimation, enabling the merging of local COGraphs into a unified global map. We validate our framework using simulation environments built on Isaac Sim and real-world datasets. The results demonstrate that, compared to transmitting semantic point clouds and 512-dimensional COGraphs, our framework can reduce the data volume by two orders of magnitude, without compromising mapping and query performance. For more details, please visit our website at https://github.com/efc-robot/MR-COGraphs.
Explore-Bench: Data Sets, Metrics and Evaluations for Frontier-based and Deep-reinforcement-learning-based Autonomous Exploration
Feb 24, 2022
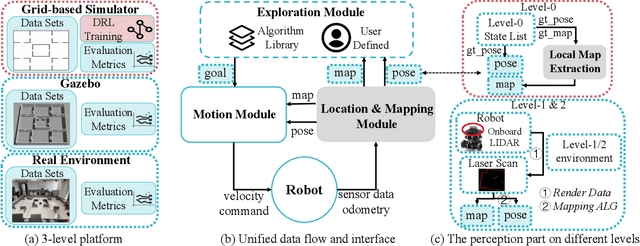
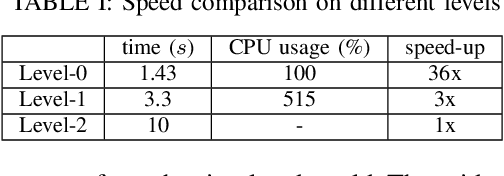
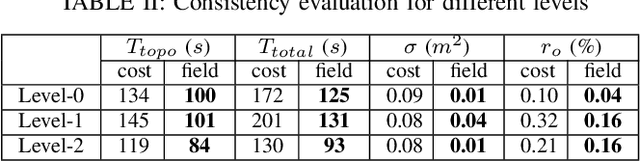
Autonomous exploration and mapping of unknown terrains employing single or multiple robots is an essential task in mobile robotics and has therefore been widely investigated. Nevertheless, given the lack of unified data sets, metrics, and platforms to evaluate the exploration approaches, we develop an autonomous robot exploration benchmark entitled Explore-Bench. The benchmark involves various exploration scenarios and presents two types of quantitative metrics to evaluate exploration efficiency and multi-robot cooperation. Explore-Bench is extremely useful as, recently, deep reinforcement learning (DRL) has been widely used for robot exploration tasks and achieved promising results. However, training DRL-based approaches requires large data sets, and additionally, current benchmarks rely on realistic simulators with a slow simulation speed, which is not appropriate for training exploration strategies. Hence, to support efficient DRL training and comprehensive evaluation, the suggested Explore-Bench designs a 3-level platform with a unified data flow and $12 \times$ speed-up that includes a grid-based simulator for fast evaluation and efficient training, a realistic Gazebo simulator, and a remotely accessible robot testbed for high-accuracy tests in physical environments. The practicality of the proposed benchmark is highlighted with the application of one DRL-based and three frontier-based exploration approaches. Furthermore, we analyze the performance differences and provide some insights about the selection and design of exploration methods. Our benchmark is available at https://github.com/efc-robot/Explore-Bench.