 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePro-AD: Learning Comprehensive Prototypes with Prototype-based Constraint for Multi-class Unsupervised Anomaly Detection
Jun 16, 2025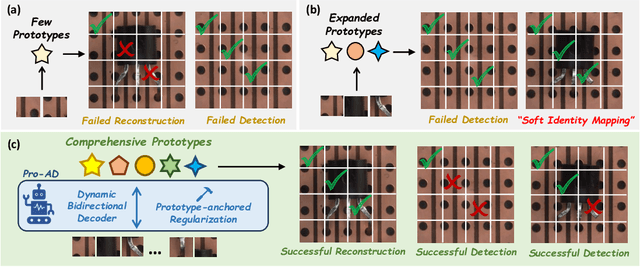

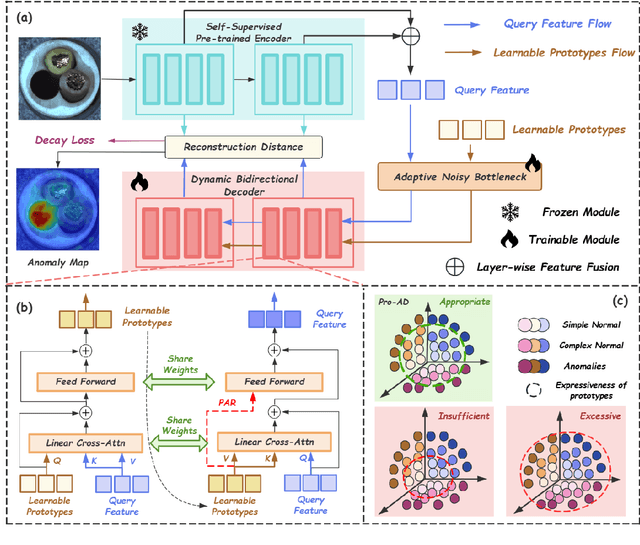

Prototype-based reconstruction methods for unsupervised anomaly detection utilize a limited set of learnable prototypes which only aggregates insufficient normal information, resulting in undesirable reconstruction. However, increasing the number of prototypes may lead to anomalies being well reconstructed through the attention mechanism, which we refer to as the "Soft Identity Mapping" problem. In this paper, we propose Pro-AD to address these issues and fully utilize the prototypes to boost the performance of anomaly detection. Specifically, we first introduce an expanded set of learnable prototypes to provide sufficient capacity for semantic information. Then we employ a Dynamic Bidirectional Decoder which integrates the process of the normal information aggregation and the target feature reconstruction via prototypes, with the aim of allowing the prototypes to aggregate more comprehensive normal semantic information from different levels of the image features and the target feature reconstruction to not only utilize its contextual information but also dynamically leverage the learned comprehensive prototypes. Additionally, to prevent the anomalies from being well reconstructed using sufficient semantic information through the attention mechanism, Pro-AD introduces a Prototype-based Constraint that applied within the target feature reconstruction process of the decoder, which further improves the performance of our approach. Extensive experiments on multiple challenging benchmarks demonstrate that our Pro-AD achieve state-of-the-art performance, highlighting its superior robustness and practical effectiveness for Multi-class Unsupervised Anomaly Detection task.
X-Scene: Large-Scale Driving Scene Generation with High Fidelity and Flexible Controllability
Jun 16, 2025



Diffusion models are advancing autonomous driving by enabling realistic data synthesis, predictive end-to-end planning, and closed-loop simulation, with a primary focus on temporally consistent generation. However, the generation of large-scale 3D scenes that require spatial coherence remains underexplored. In this paper, we propose X-Scene, a novel framework for large-scale driving scene generation that achieves both geometric intricacy and appearance fidelity, while offering flexible controllability. Specifically, X-Scene supports multi-granular control, including low-level conditions such as user-provided or text-driven layout for detailed scene composition and high-level semantic guidance such as user-intent and LLM-enriched text prompts for efficient customization. To enhance geometrical and visual fidelity, we introduce a unified pipeline that sequentially generates 3D semantic occupancy and the corresponding multiview images, while ensuring alignment between modalities. Additionally, we extend the generated local region into a large-scale scene through consistency-aware scene outpainting, which extrapolates new occupancy and images conditioned on the previously generated area, enhancing spatial continuity and preserving visual coherence. The resulting scenes are lifted into high-quality 3DGS representations, supporting diverse applications such as scene exploration. Comprehensive experiments demonstrate that X-Scene significantly advances controllability and fidelity for large-scale driving scene generation, empowering data generation and simulation for autonomous driving.
UltraVideo: High-Quality UHD Video Dataset with Comprehensive Captions
Jun 16, 2025The quality of the video dataset (image quality, resolution, and fine-grained caption) greatly influences the performance of the video generation model. The growing demand for video applications sets higher requirements for high-quality video generation models. For example, the generation of movie-level Ultra-High Definition (UHD) videos and the creation of 4K short video content. However, the existing public datasets cannot support related research and applications. In this paper, we first propose a high-quality open-sourced UHD-4K (22.4\% of which are 8K) text-to-video dataset named UltraVideo, which contains a wide range of topics (more than 100 kinds), and each video has 9 structured captions with one summarized caption (average of 824 words). Specifically, we carefully design a highly automated curation process with four stages to obtain the final high-quality dataset: \textit{i)} collection of diverse and high-quality video clips. \textit{ii)} statistical data filtering. \textit{iii)} model-based data purification. \textit{iv)} generation of comprehensive, structured captions. In addition, we expand Wan to UltraWan-1K/-4K, which can natively generate high-quality 1K/4K videos with more consistent text controllability, demonstrating the effectiveness of our data curation.We believe that this work can make a significant contribution to future research on UHD video generation. UltraVideo dataset and UltraWan models are available at https://xzc-zju.github.io/projects/UltraVideo.
Omni-AdaVideoRAG: Omni-Contextual Adaptive Retrieval-Augmented for Efficient Long Video Understanding
Jun 16, 2025Multimodal Large Language Models (MLLMs) struggle with long videos due to fixed context windows and weak long-term dependency modeling. Existing Retrieval-Augmented Generation (RAG) methods for videos use static retrieval strategies, leading to inefficiencies for simple queries and information loss for complex tasks. To address this, we propose AdaVideoRAG, a novel framework that dynamically adapts retrieval granularity based on query complexity using a lightweight intent classifier. Our framework employs an Omni-Knowledge Indexing module to build hierarchical databases from text (captions, ASR, OCR), visual features, and semantic graphs, enabling optimal resource allocation across tasks. We also introduce the HiVU benchmark for comprehensive evaluation. Experiments demonstrate improved efficiency and accuracy for long-video understanding, with seamless integration into existing MLLMs. AdaVideoRAG establishes a new paradigm for adaptive retrieval in video analysis. Codes will be open-sourced at https://github.com/xzc-zju/AdaVideoRAG.
Text to Image for Multi-Label Image Recognition with Joint Prompt-Adapter Learning
Jun 12, 2025



Benefited from image-text contrastive learning, pre-trained vision-language models, e.g., CLIP, allow to direct leverage texts as images (TaI) for parameter-efficient fine-tuning (PEFT). While CLIP is capable of making image features to be similar to the corresponding text features, the modality gap remains a nontrivial issue and limits image recognition performance of TaI. Using multi-label image recognition (MLR) as an example, we present a novel method, called T2I-PAL to tackle the modality gap issue when using only text captions for PEFT. The core design of T2I-PAL is to leverage pre-trained text-to-image generation models to generate photo-realistic and diverse images from text captions, thereby reducing the modality gap. To further enhance MLR, T2I-PAL incorporates a class-wise heatmap and learnable prototypes. This aggregates local similarities, making the representation of local visual features more robust and informative for multi-label recognition. For better PEFT, we further combine both prompt tuning and adapter learning to enhance classification performance. T2I-PAL offers significant advantages: it eliminates the need for fully semantically annotated training images, thereby reducing the manual annotation workload, and it preserves the intrinsic mode of the CLIP model, allowing for seamless integration with any existing CLIP framework. Extensive experiments on multiple benchmarks, including MS-COCO, VOC2007, and NUS-WIDE, show that our T2I-PAL can boost recognition performance by 3.47% in average above the top-ranked state-of-the-art methods.
Decentralized Optimization on Compact Submanifolds by Quantized Riemannian Gradient Tracking
Jun 09, 2025This paper considers the problem of decentralized optimization on compact submanifolds, where a finite sum of smooth (possibly non-convex) local functions is minimized by $n$ agents forming an undirected and connected graph. However, the efficiency of distributed optimization is often hindered by communication bottlenecks. To mitigate this, we propose the Quantized Riemannian Gradient Tracking (Q-RGT) algorithm, where agents update their local variables using quantized gradients. The introduction of quantization noise allows our algorithm to bypass the constraints of the accurate Riemannian projection operator (such as retraction), further improving iterative efficiency. To the best of our knowledge, this is the first algorithm to achieve an $\mathcal{O}(1/K)$ convergence rate in the presence of quantization, matching the convergence rate of methods without quantization. Additionally, we explicitly derive lower bounds on decentralized consensus associated with a function of quantization levels. Numerical experiments demonstrate that Q-RGT performs comparably to non-quantized methods while reducing communication bottlenecks and computational overhead.
On the Emergence of Weak-to-Strong Generalization: A Bias-Variance Perspective
May 30, 2025Weak-to-strong generalization (W2SG) refers to the phenomenon where a strong student model, trained on a dataset labeled by a weak teacher, ultimately outperforms the teacher on the target task. Recent studies attribute this performance gain to the prediction misfit between the student and teacher models. In this work, we theoretically investigate the emergence of W2SG through a generalized bias-variance decomposition of Bregman divergence. Specifically, we show that the expected population risk gap between the student and teacher is quantified by the expected misfit between the two models. While this aligns with previous results, our analysis removes several restrictive assumptions, most notably, the convexity of the student's hypothesis class, required in earlier works. Moreover, we show that W2SG is more likely to emerge when the student model approximates its posterior mean teacher, rather than mimicking an individual teacher. Using a concrete example, we demonstrate that if the student model has significantly larger capacity than the teacher, it can indeed converge to this posterior mean. Our analysis also suggests that avoiding overfitting to the teacher's supervision and reducing the entropy of student's prediction further facilitate W2SG. In addition, we show that the reverse cross-entropy loss, unlike the standard forward cross-entropy, is less sensitive to the predictive uncertainty of the teacher. Finally, we empirically verify our theoretical insights and demonstrate that incorporating the reverse cross-entropy loss consistently improves student performance.
Towards Reward Fairness in RLHF: From a Resource Allocation Perspective
May 29, 2025Rewards serve as proxies for human preferences and play a crucial role in Reinforcement Learning from Human Feedback (RLHF). However, if these rewards are inherently imperfect, exhibiting various biases, they can adversely affect the alignment of large language models (LLMs). In this paper, we collectively define the various biases present in rewards as the problem of reward unfairness. We propose a bias-agnostic method to address the issue of reward fairness from a resource allocation perspective, without specifically designing for each type of bias, yet effectively mitigating them. Specifically, we model preference learning as a resource allocation problem, treating rewards as resources to be allocated while considering the trade-off between utility and fairness in their distribution. We propose two methods, Fairness Regularization and Fairness Coefficient, to achieve fairness in rewards. We apply our methods in both verification and reinforcement learning scenarios to obtain a fairness reward model and a policy model, respectively. Experiments conducted in these scenarios demonstrate that our approach aligns LLMs with human preferences in a more fair manner.
UltraVSR: Achieving Ultra-Realistic Video Super-Resolution with Efficient One-Step Diffusion Space
May 26, 2025Diffusion models have shown great potential in generating realistic image detail. However, adapting these models to video super-resolution (VSR) remains challenging due to their inherent stochasticity and lack of temporal modeling. In this paper, we propose UltraVSR, a novel framework that enables ultra-realistic and temporal-coherent VSR through an efficient one-step diffusion space. A central component of UltraVSR is the Degradation-aware Restoration Schedule (DRS), which estimates a degradation factor from the low-resolution input and transforms iterative denoising process into a single-step reconstruction from from low-resolution to high-resolution videos. This design eliminates randomness from diffusion noise and significantly speeds up inference. To ensure temporal consistency, we propose a lightweight yet effective Recurrent Temporal Shift (RTS) module, composed of an RTS-convolution unit and an RTS-attention unit. By partially shifting feature components along the temporal dimension, these two units collaboratively facilitate effective feature propagation, fusion, and alignment across neighboring frames, without relying on explicit temporal layers. The RTS module is integrated into a pretrained text-to-image diffusion model and is further enhanced through Spatio-temporal Joint Distillation (SJD), which improves temporal coherence while preserving realistic details. Additionally, we introduce a Temporally Asynchronous Inference (TAI) strategy to capture long-range temporal dependencies under limited memory constraints. Extensive experiments show that UltraVSR achieves state-of-the-art performance, both qualitatively and quantitatively, in a single sampling step.
SRDiffusion: Accelerate Video Diffusion Inference via Sketching-Rendering Cooperation
May 25, 2025Leveraging the diffusion transformer (DiT) architecture, models like Sora, CogVideoX and Wan have achieved remarkable progress in text-to-video, image-to-video, and video editing tasks. Despite these advances, diffusion-based video generation remains computationally intensive, especially for high-resolution, long-duration videos. Prior work accelerates its inference by skipping computation, usually at the cost of severe quality degradation. In this paper, we propose SRDiffusion, a novel framework that leverages collaboration between large and small models to reduce inference cost. The large model handles high-noise steps to ensure semantic and motion fidelity (Sketching), while the smaller model refines visual details in low-noise steps (Rendering). Experimental results demonstrate that our method outperforms existing approaches, over 3$\times$ speedup for Wan with nearly no quality loss for VBench, and 2$\times$ speedup for CogVideoX. Our method is introduced as a new direction orthogonal to existing acceleration strategies, offering a practical solution for scalable video generation.