 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvances and Frontiers of LLM-based Issue Resolution in Software Engineering: A Comprehensive Survey
Jan 15, 2026Issue resolution, a complex Software Engineering (SWE) task integral to real-world development, has emerged as a compelling challenge for artificial intelligence. The establishment of benchmarks like SWE-bench revealed this task as profoundly difficult for large language models, thereby significantly accelerating the evolution of autonomous coding agents. This paper presents a systematic survey of this emerging domain. We begin by examining data construction pipelines, covering automated collection and synthesis approaches. We then provide a comprehensive analysis of methodologies, spanning training-free frameworks with their modular components to training-based techniques, including supervised fine-tuning and reinforcement learning. Subsequently, we discuss critical analyses of data quality and agent behavior, alongside practical applications. Finally, we identify key challenges and outline promising directions for future research. An open-source repository is maintained at https://github.com/DeepSoftwareAnalytics/Awesome-Issue-Resolution to serve as a dynamic resource in this field.
SWE-Factory: Your Automated Factory for Issue Resolution Training Data and Evaluation Benchmarks
Jun 12, 2025Constructing large-scale datasets for the GitHub issue resolution task is crucial for both training and evaluating the software engineering capabilities of Large Language Models (LLMs). However, the traditional process for creating such benchmarks is notoriously challenging and labor-intensive, particularly in the stages of setting up evaluation environments, grading test outcomes, and validating task instances. In this paper, we propose SWE-Factory, an automated pipeline designed to address these challenges. To tackle these issues, our pipeline integrates three core automated components. First, we introduce SWE-Builder, a multi-agent system that automates evaluation environment construction, which employs four specialized agents that work in a collaborative, iterative loop and leverages an environment memory pool to enhance efficiency. Second, we introduce a standardized, exit-code-based grading method that eliminates the need for manually writing custom parsers. Finally, we automate the fail2pass validation process using these reliable exit code signals. Experiments on 671 issues across four programming languages show that our pipeline can effectively construct valid task instances; for example, with GPT-4.1-mini, our SWE-Builder constructs 269 valid instances at $0.045 per instance, while with Gemini-2.5-flash, it achieves comparable performance at the lowest cost of $0.024 per instance. We also demonstrate that our exit-code-based grading achieves 100% accuracy compared to manual inspection, and our automated fail2pass validation reaches a precision of 0.92 and a recall of 1.00. We hope our automated pipeline will accelerate the collection of large-scale, high-quality GitHub issue resolution datasets for both training and evaluation. Our code and datasets are released at https://github.com/DeepSoftwareAnalytics/swe-factory.
MappedTrace: Tracing Pointer Remotely with Compiler-generated Maps
Jan 18, 2025Existing precise pointer tracing methods introduce substantial runtime overhead to the program being traced and are applicable only at specific program execution points. We propose MappedTrace that leverages compiler-generated read-only maps to accurately identify all pointers in any given snapshot of a program's execution state. The maps record the locations and types of pointers, allowing the tracer to precisely identify pointers without requiring the traced program to maintain bookkeeping data structures or poll at safe points, thereby reducing runtime overhead. By running the tracer from a different address space or machine, MappedTrace presents new opportunities to improve memory management techniques like memory leak detection and enables novel use cases such as infinite memory abstraction for resource-constrained environments.
Confidential Prompting: Protecting User Prompts from Cloud LLM Providers
Sep 27, 2024



Our work tackles the challenge of securing user inputs in cloud-based large language model (LLM) services while ensuring output consistency, model confidentiality, and compute efficiency. We introduce Secure Multi-party Decoding (SMD), which leverages confidential computing to confine user prompts to a trusted execution environment, namely a confidential virtual machine (CVM), while allowing service providers to generate tokens efficiently. We also introduce a novel cryptographic method, Prompt Obfuscation (PO), to ensure robustness against reconstruction attacks on SMD. We demonstrate that our approach preserves both prompt confidentiality and LLM serving efficiency. Our solution can enable privacy-preserving cloud LLM services that handle sensitive prompts, such as clinical records, financial data, and personal information.
Real Multi-Sense or Pseudo Multi-Sense: An Approach to Improve Word Representation
Jan 06, 2017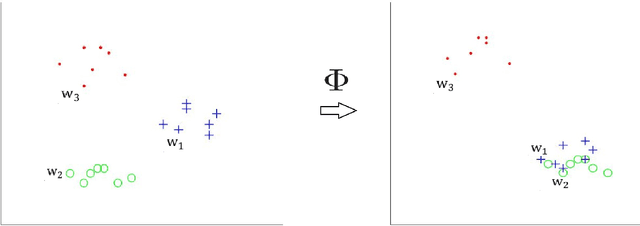
Previous researches have shown that learning multiple representations for polysemous words can improve the performance of word embeddings on many tasks. However, this leads to another problem. Several vectors of a word may actually point to the same meaning, namely pseudo multi-sense. In this paper, we introduce the concept of pseudo multi-sense, and then propose an algorithm to detect such cases. With the consideration of the detected pseudo multi-sense cases, we try to refine the existing word embeddings to eliminate the influence of pseudo multi-sense. Moreover, we apply our algorithm on previous released multi-sense word embeddings and tested it on artificial word similarity tasks and the analogy task. The result of the experiments shows that diminishing pseudo multi-sense can improve the quality of word representations. Thus, our method is actually an efficient way to reduce linguistic complexity.