 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaming Actor-Observer Asymmetry in Agents via Dialectical Alignment
Apr 21, 2026Large Language Model agents have rapidly evolved from static text generators into dynamic systems capable of executing complex autonomous workflows. To enhance reliability, multi-agent frameworks assigning specialized roles are increasingly adopted to enable self-reflection and mutual auditing. While such role-playing effectively leverages domain expert knowledge, we find it simultaneously induces a human-like cognitive bias known as Actor-Observer Asymmetry (AOA). Specifically, an agent acting as an actor (during self-reflection) tends to attribute failures to external factors, whereas an observer (during mutual auditing) attributes the same errors to internal faults. We quantify this using our new Ambiguous Failure Benchmark, which reveals that simply swapping perspectives triggers the AOA effect in over 20% of cases for most models. To tame this bias, we introduce ReTAS (Reasoning via Thesis-Antithesis-Synthesis), a model trained through dialectical alignment to enforce perspective-invariant reasoning. By integrating dialectical chain-of-thought with Group Relative Policy Optimization, ReTAS guides agents to synthesize conflicting viewpoints into an objective consensus. Experiments demonstrate that ReTAS effectively mitigates attribution inconsistency and significantly improves fault resolution rates in ambiguous scenarios.
Orthogonal Spatial-temporal Distributional Transfer for 4D Generation
Mar 05, 2026In the AIGC era, generating high-quality 4D content has garnered increasing research attention. Unfortunately, current 4D synthesis research is severely constrained by the lack of large-scale 4D datasets, preventing models from adequately learning the critical spatial-temporal features necessary for high-quality 4D generation, thus hindering progress in this domain. To combat this, we propose a novel framework that transfers rich spatial priors from existing 3D diffusion models and temporal priors from video diffusion models to enhance 4D synthesis. We develop a spatial-temporal-disentangled 4D (STD-4D) Diffusion model, which synthesizes 4D-aware videos through disentangled spatial and temporal latents. To facilitate the best feature transfer, we design a novel Orthogonal Spatial-temporal Distributional Transfer (Orster) mechanism, where the spatiotemporal feature distributions are carefully modeled and injected into the STD-4D Diffusion. Furthermore, during the 4D construction, we devise a spatial-temporal-aware HexPlane (ST-HexPlane) to integrate the transferred spatiotemporal features, thereby improving 4D deformation and 4D Gaussian feature modeling. Experiments demonstrate that our method significantly outperforms existing approaches, achieving superior spatial-temporal consistency and higher-quality 4D synthesis.
UniM: A Unified Any-to-Any Interleaved Multimodal Benchmark
Mar 05, 2026In real-world multimodal applications, systems usually need to comprehend arbitrarily combined and interleaved multimodal inputs from users, while also generating outputs in any interleaved multimedia form. This capability defines the goal of any-to-any interleaved multimodal learning under a unified paradigm of understanding and generation, posing new challenges and opportunities for advancing Multimodal Large Language Models (MLLMs). To foster and benchmark this capability, this paper introduces the UniM benchmark, the first Unified Any-to-Any Interleaved Multimodal dataset. UniM contains 31K high-quality instances across 30 domains and 7 representative modalities: text, image, audio, video, document, code, and 3D, each requiring multiple intertwined reasoning and generation capabilities. We further introduce the UniM Evaluation Suite, which assesses models along three dimensions: Semantic Correctness & Generation Quality, Response Structure Integrity, and Interleaved Coherence. In addition, we propose UniMA, an agentic baseline model equipped with traceable reasoning for structured interleaved generation. Comprehensive experiments demonstrate the difficulty of UniM and highlight key challenges and directions for advancing unified any-to-any multimodal intelligence. The project page is https://any2any-mllm.github.io/unim.
Spatial Causal Prediction in Video
Mar 04, 2026Spatial reasoning, the ability to understand spatial relations, causality, and dynamic evolution, is central to human intelligence and essential for real-world applications such as autonomous driving and robotics. Existing studies, however, primarily assess models on visible spatio-temporal understanding, overlooking their ability to infer unseen past or future spatial states. In this work, we introduce Spatial Causal Prediction (SCP), a new task paradigm that challenges models to reason beyond observation and predict spatial causal outcomes. We further construct SCP-Bench, a benchmark comprising 2,500 QA pairs across 1,181 videos spanning diverse viewpoints, scenes, and causal directions, to support systematic evaluation. Through comprehensive experiments on {23} state-of-the-art models, we reveal substantial gaps between human and model performance, limited temporal extrapolation, and weak causal grounding. We further analyze key factors influencing performance and propose perception-enhancement and reasoning-guided strategies toward advancing spatial causal intelligence. The project page is https://guangstrip.github.io/SCP-Bench.
QIME: Constructing Interpretable Medical Text Embeddings via Ontology-Grounded Questions
Mar 03, 2026While dense biomedical embeddings achieve strong performance, their black-box nature limits their utility in clinical decision-making. Recent question-based interpretable embeddings represent text as binary answers to natural-language questions, but these approaches often rely on heuristic or surface-level contrastive signals and overlook specialized domain knowledge. We propose QIME, an ontology-grounded framework for constructing interpretable medical text embeddings in which each dimension corresponds to a clinically meaningful yes/no question. By conditioning on cluster-specific medical concept signatures, QIME generates semantically atomic questions that capture fine-grained distinctions in biomedical text. Furthermore, QIME supports a training-free embedding construction strategy that eliminates per-question classifier training while further improving performance. Experiments across biomedical semantic similarity, clustering, and retrieval benchmarks show that QIME consistently outperforms prior interpretable embedding methods and substantially narrows the gap to strong black-box biomedical encoders, while providing concise and clinically informative explanations.
Unveiling the Cognitive Compass: Theory-of-Mind-Guided Multimodal Emotion Reasoning
Feb 01, 2026Despite rapid progress in multimodal large language models (MLLMs), their capability for deep emotional understanding remains limited. We argue that genuine affective intelligence requires explicit modeling of Theory of Mind (ToM), the cognitive substrate from which emotions arise. To this end, we introduce HitEmotion, a ToM-grounded hierarchical benchmark that diagnoses capability breakpoints across increasing levels of cognitive depth. Second, we propose a ToM-guided reasoning chain that tracks mental states and calibrates cross-modal evidence to achieve faithful emotional reasoning. We further introduce TMPO, a reinforcement learning method that uses intermediate mental states as process-level supervision to guide and strengthen model reasoning. Extensive experiments show that HitEmotion exposes deep emotional reasoning deficits in state-of-the-art models, especially on cognitively demanding tasks. In evaluation, the ToM-guided reasoning chain and TMPO improve end-task accuracy and yield more faithful, more coherent rationales. In conclusion, our work provides the research community with a practical toolkit for evaluating and enhancing the cognition-based emotional understanding capabilities of MLLMs. Our dataset and code are available at: https://HitEmotion.github.io/.
Training LLMs with LogicReward for Faithful and Rigorous Reasoning
Dec 20, 2025



Although LLMs exhibit strong reasoning capabilities, existing training methods largely depend on outcome-based feedback, which can produce correct answers with flawed reasoning. Prior work introduces supervision on intermediate steps but still lacks guarantees of logical soundness, which is crucial in high-stakes scenarios where logical consistency is paramount. To address this, we propose LogicReward, a novel reward system that guides model training by enforcing step-level logical correctness with a theorem prover. We further introduce Autoformalization with Soft Unification, which reduces natural language ambiguity and improves formalization quality, enabling more effective use of the theorem prover. An 8B model trained on data constructed with LogicReward surpasses GPT-4o and o4-mini by 11.6\% and 2\% on natural language inference and logical reasoning tasks with simple training procedures. Further analysis shows that LogicReward enhances reasoning faithfulness, improves generalizability to unseen tasks such as math and commonsense reasoning, and provides a reliable reward signal even without ground-truth labels. We will release all data and code at https://llm-symbol.github.io/LogicReward.
Multi-Part Object Representations via Graph Structures and Co-Part Discovery
Dec 20, 2025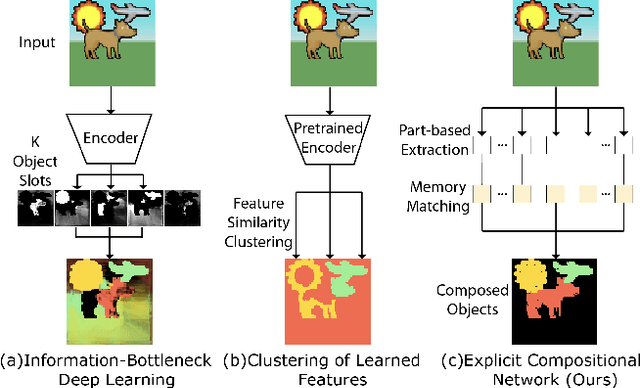
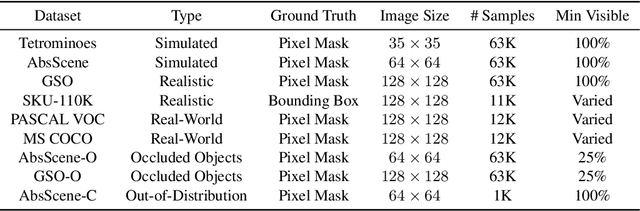
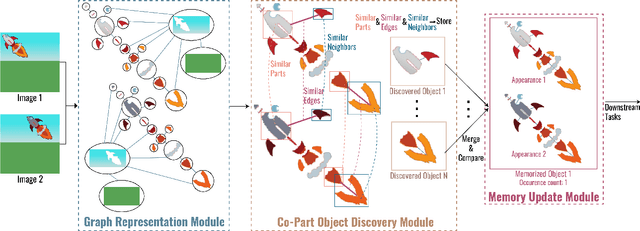
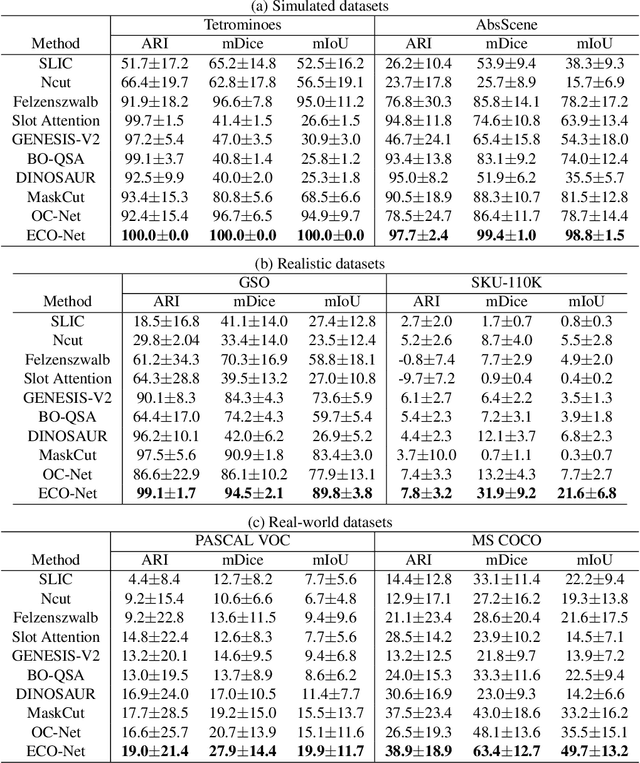
Discovering object-centric representations from images can significantly enhance the robustness, sample efficiency and generalizability of vision models. Works on images with multi-part objects typically follow an implicit object representation approach, which fail to recognize these learned objects in occluded or out-of-distribution contexts. This is due to the assumption that object part-whole relations are implicitly encoded into the representations through indirect training objectives. We address this limitation by proposing a novel method that leverages on explicit graph representations for parts and present a co-part object discovery algorithm. We then introduce three benchmarks to evaluate the robustness of object-centric methods in recognizing multi-part objects within occluded and out-of-distribution settings. Experimental results on simulated, realistic, and real-world images show marked improvements in the quality of discovered objects compared to state-of-the-art methods, as well as the accurate recognition of multi-part objects in occluded and out-of-distribution contexts. We also show that the discovered object-centric representations can more accurately predict key object properties in a downstream task, highlighting the potential of our method to advance the field of object-centric representations.
Multi-Modal Continual Learning via Cross-Modality Adapters and Representation Alignment with Knowledge Preservation
Nov 10, 2025Continual learning is essential for adapting models to new tasks while retaining previously acquired knowledge. While existing approaches predominantly focus on uni-modal data, multi-modal learning offers substantial benefits by utilizing diverse sensory inputs, akin to human perception. However, multi-modal continual learning presents additional challenges, as the model must effectively integrate new information from various modalities while preventing catastrophic forgetting. In this work, we propose a pre-trained model-based framework for multi-modal continual learning. Our framework includes a novel cross-modality adapter with a mixture-of-experts structure to facilitate effective integration of multi-modal information across tasks. We also introduce a representation alignment loss that fosters learning of robust multi-modal representations, and regularize relationships between learned representations to preserve knowledge from previous tasks. Experiments on several multi-modal datasets demonstrate that our approach consistently outperforms baselines in both class-incremental and domain-incremental learning, achieving higher accuracy and reduced forgetting.
* Accepted to ECAI 2025
TRUST-VL: An Explainable News Assistant for General Multimodal Misinformation Detection
Sep 04, 2025Multimodal misinformation, encompassing textual, visual, and cross-modal distortions, poses an increasing societal threat that is amplified by generative AI. Existing methods typically focus on a single type of distortion and struggle to generalize to unseen scenarios. In this work, we observe that different distortion types share common reasoning capabilities while also requiring task-specific skills. We hypothesize that joint training across distortion types facilitates knowledge sharing and enhances the model's ability to generalize. To this end, we introduce TRUST-VL, a unified and explainable vision-language model for general multimodal misinformation detection. TRUST-VL incorporates a novel Question-Aware Visual Amplifier module, designed to extract task-specific visual features. To support training, we also construct TRUST-Instruct, a large-scale instruction dataset containing 198K samples featuring structured reasoning chains aligned with human fact-checking workflows. Extensive experiments on both in-domain and zero-shot benchmarks demonstrate that TRUST-VL achieves state-of-the-art performance, while also offering strong generalization and interpretability.