 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonaAgent: When Large Language Model Agents Meet Personalization at Test Time
Jun 06, 2025Large Language Model (LLM) empowered agents have recently emerged as advanced paradigms that exhibit impressive capabilities in a wide range of domains and tasks. Despite their potential, current LLM agents often adopt a one-size-fits-all approach, lacking the flexibility to respond to users' varying needs and preferences. This limitation motivates us to develop PersonaAgent, the first personalized LLM agent framework designed to address versatile personalization tasks. Specifically, PersonaAgent integrates two complementary components - a personalized memory module that includes episodic and semantic memory mechanisms; a personalized action module that enables the agent to perform tool actions tailored to the user. At the core, the persona (defined as unique system prompt for each user) functions as an intermediary: it leverages insights from personalized memory to control agent actions, while the outcomes of these actions in turn refine the memory. Based on the framework, we propose a test-time user-preference alignment strategy that simulate the latest n interactions to optimize the persona prompt, ensuring real-time user preference alignment through textual loss feedback between simulated and ground-truth responses. Experimental evaluations demonstrate that PersonaAgent significantly outperforms other baseline methods by not only personalizing the action space effectively but also scaling during test-time real-world applications. These results underscore the feasibility and potential of our approach in delivering tailored, dynamic user experiences.
Aligning Large Language Models with Implicit Preferences from User-Generated Content
Jun 04, 2025



Learning from preference feedback is essential for aligning large language models (LLMs) with human values and improving the quality of generated responses. However, existing preference learning methods rely heavily on curated data from humans or advanced LLMs, which is costly and difficult to scale. In this work, we present PUGC, a novel framework that leverages implicit human Preferences in unlabeled User-Generated Content (UGC) to generate preference data. Although UGC is not explicitly created to guide LLMs in generating human-preferred responses, it often reflects valuable insights and implicit preferences from its creators that has the potential to address readers' questions. PUGC transforms UGC into user queries and generates responses from the policy model. The UGC is then leveraged as a reference text for response scoring, aligning the model with these implicit preferences. This approach improves the quality of preference data while enabling scalable, domain-specific alignment. Experimental results on Alpaca Eval 2 show that models trained with DPO and PUGC achieve a 9.37% performance improvement over traditional methods, setting a 35.93% state-of-the-art length-controlled win rate using Mistral-7B-Instruct. Further studies highlight gains in reward quality, domain-specific alignment effectiveness, robustness against UGC quality, and theory of mind capabilities. Our code and dataset are available at https://zhaoxuan.info/PUGC.github.io/
Gradient Boosting Decision Tree with LSTM for Investment Prediction
May 29, 2025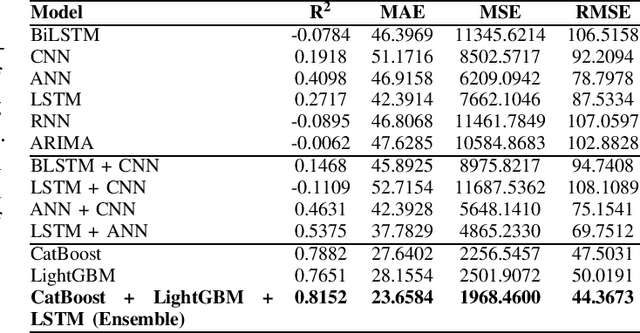
This paper proposes a hybrid framework combining LSTM (Long Short-Term Memory) networks with LightGBM and CatBoost for stock price prediction. The framework processes time-series financial data and evaluates performance using seven models: Artificial Neural Networks (ANNs), Convolutional Neural Networks (CNNs), Bidirectional LSTM (BiLSTM), vanilla LSTM, XGBoost, LightGBM, and standard Neural Networks (NNs). Key metrics, including MAE, R-squared, MSE, and RMSE, are used to establish benchmarks across different time scales. Building on these benchmarks, we develop an ensemble model that combines the strengths of sequential and tree-based approaches. Experimental results show that the proposed framework improves accuracy by 10 to 15 percent compared to individual models and reduces error during market changes. This study highlights the potential of ensemble methods for financial forecasting and provides a flexible design for integrating new machine learning techniques.
SETransformer: A Hybrid Attention-Based Architecture for Robust Human Activity Recognition
May 25, 2025



Human Activity Recognition (HAR) using wearable sensor data has become a central task in mobile computing, healthcare, and human-computer interaction. Despite the success of traditional deep learning models such as CNNs and RNNs, they often struggle to capture long-range temporal dependencies and contextual relevance across multiple sensor channels. To address these limitations, we propose SETransformer, a hybrid deep neural architecture that combines Transformer-based temporal modeling with channel-wise squeeze-and-excitation (SE) attention and a learnable temporal attention pooling mechanism. The model takes raw triaxial accelerometer data as input and leverages global self-attention to capture activity-specific motion dynamics over extended time windows, while adaptively emphasizing informative sensor channels and critical time steps. We evaluate SETransformer on the WISDM dataset and demonstrate that it significantly outperforms conventional models including LSTM, GRU, BiLSTM, and CNN baselines. The proposed model achieves a validation accuracy of 84.68\% and a macro F1-score of 84.64\%, surpassing all baseline architectures by a notable margin. Our results show that SETransformer is a competitive and interpretable solution for real-world HAR tasks, with strong potential for deployment in mobile and ubiquitous sensing applications.
EcomScriptBench: A Multi-task Benchmark for E-commerce Script Planning via Step-wise Intention-Driven Product Association
May 21, 2025Goal-oriented script planning, or the ability to devise coherent sequences of actions toward specific goals, is commonly employed by humans to plan for typical activities. In e-commerce, customers increasingly seek LLM-based assistants to generate scripts and recommend products at each step, thereby facilitating convenient and efficient shopping experiences. However, this capability remains underexplored due to several challenges, including the inability of LLMs to simultaneously conduct script planning and product retrieval, difficulties in matching products caused by semantic discrepancies between planned actions and search queries, and a lack of methods and benchmark data for evaluation. In this paper, we step forward by formally defining the task of E-commerce Script Planning (EcomScript) as three sequential subtasks. We propose a novel framework that enables the scalable generation of product-enriched scripts by associating products with each step based on the semantic similarity between the actions and their purchase intentions. By applying our framework to real-world e-commerce data, we construct the very first large-scale EcomScript dataset, EcomScriptBench, which includes 605,229 scripts sourced from 2.4 million products. Human annotations are then conducted to provide gold labels for a sampled subset, forming an evaluation benchmark. Extensive experiments reveal that current (L)LMs face significant challenges with EcomScript tasks, even after fine-tuning, while injecting product purchase intentions improves their performance.
WeGA: Weakly-Supervised Global-Local Affinity Learning Framework for Lymph Node Metastasis Prediction in Rectal Cancer
May 15, 2025Accurate lymph node metastasis (LNM) assessment in rectal cancer is essential for treatment planning, yet current MRI-based evaluation shows unsatisfactory accuracy, leading to suboptimal clinical decisions. Developing automated systems also faces significant obstacles, primarily the lack of node-level annotations. Previous methods treat lymph nodes as isolated entities rather than as an interconnected system, overlooking valuable spatial and contextual information. To solve this problem, we present WeGA, a novel weakly-supervised global-local affinity learning framework that addresses these challenges through three key innovations: 1) a dual-branch architecture with DINOv2 backbone for global context and residual encoder for local node details; 2) a global-local affinity extractor that aligns features across scales through cross-attention fusion; and 3) a regional affinity loss that enforces structural coherence between classification maps and anatomical regions. Experiments across one internal and two external test centers demonstrate that WeGA outperforms existing methods, achieving AUCs of 0.750, 0.822, and 0.802 respectively. By effectively modeling the relationships between individual lymph nodes and their collective context, WeGA provides a more accurate and generalizable approach for lymph node metastasis prediction, potentially enhancing diagnostic precision and treatment selection for rectal cancer patients.
ABS-Mamba: SAM2-Driven Bidirectional Spiral Mamba Network for Medical Image Translation
May 12, 2025Accurate multi-modal medical image translation requires ha-rmonizing global anatomical semantics and local structural fidelity, a challenge complicated by intermodality information loss and structural distortion. We propose ABS-Mamba, a novel architecture integrating the Segment Anything Model 2 (SAM2) for organ-aware semantic representation, specialized convolutional neural networks (CNNs) for preserving modality-specific edge and texture details, and Mamba's selective state-space modeling for efficient long- and short-range feature dependencies. Structurally, our dual-resolution framework leverages SAM2's image encoder to capture organ-scale semantics from high-resolution inputs, while a parallel CNNs branch extracts fine-grained local features. The Robust Feature Fusion Network (RFFN) integrates these epresentations, and the Bidirectional Mamba Residual Network (BMRN) models spatial dependencies using spiral scanning and bidirectional state-space dynamics. A three-stage skip fusion decoder enhances edge and texture fidelity. We employ Efficient Low-Rank Adaptation (LoRA+) fine-tuning to enable precise domain specialization while maintaining the foundational capabilities of the pre-trained components. Extensive experimental validation on the SynthRAD2023 and BraTS2019 datasets demonstrates that ABS-Mamba outperforms state-of-the-art methods, delivering high-fidelity cross-modal synthesis that preserves anatomical semantics and structural details to enhance diagnostic accuracy in clinical applications. The code is available at https://github.com/gatina-yone/ABS-Mamba
PosterMaker: Towards High-Quality Product Poster Generation with Accurate Text Rendering
Apr 09, 2025Product posters, which integrate subject, scene, and text, are crucial promotional tools for attracting customers. Creating such posters using modern image generation methods is valuable, while the main challenge lies in accurately rendering text, especially for complex writing systems like Chinese, which contains over 10,000 individual characters. In this work, we identify the key to precise text rendering as constructing a character-discriminative visual feature as a control signal. Based on this insight, we propose a robust character-wise representation as control and we develop TextRenderNet, which achieves a high text rendering accuracy of over 90%. Another challenge in poster generation is maintaining the fidelity of user-specific products. We address this by introducing SceneGenNet, an inpainting-based model, and propose subject fidelity feedback learning to further enhance fidelity. Based on TextRenderNet and SceneGenNet, we present PosterMaker, an end-to-end generation framework. To optimize PosterMaker efficiently, we implement a two-stage training strategy that decouples text rendering and background generation learning. Experimental results show that PosterMaker outperforms existing baselines by a remarkable margin, which demonstrates its effectiveness.
END: Early Noise Dropping for Efficient and Effective Context Denoising
Feb 26, 2025Large Language Models (LLMs) have demonstrated remarkable performance across a wide range of natural language processing tasks. However, they are often distracted by irrelevant or noisy context in input sequences that degrades output quality. This problem affects both long- and short-context scenarios, such as retrieval-augmented generation, table question-answering, and in-context learning. We reveal that LLMs can implicitly identify whether input sequences contain useful information at early layers, prior to token generation. Leveraging this insight, we introduce Early Noise Dropping (\textsc{END}), a novel approach to mitigate this issue without requiring fine-tuning the LLMs. \textsc{END} segments input sequences into chunks and employs a linear prober on the early layers of LLMs to differentiate between informative and noisy chunks. By discarding noisy chunks early in the process, \textsc{END} preserves critical information, reduces distraction, and lowers computational overhead. Extensive experiments demonstrate that \textsc{END} significantly improves both performance and efficiency across different LLMs on multiple evaluation datasets. Furthermore, by investigating LLMs' implicit understanding to the input with the prober, this work also deepens understanding of how LLMs do reasoning with contexts internally.
IHEval: Evaluating Language Models on Following the Instruction Hierarchy
Feb 12, 2025The instruction hierarchy, which establishes a priority order from system messages to user messages, conversation history, and tool outputs, is essential for ensuring consistent and safe behavior in language models (LMs). Despite its importance, this topic receives limited attention, and there is a lack of comprehensive benchmarks for evaluating models' ability to follow the instruction hierarchy. We bridge this gap by introducing IHEval, a novel benchmark comprising 3,538 examples across nine tasks, covering cases where instructions in different priorities either align or conflict. Our evaluation of popular LMs highlights their struggle to recognize instruction priorities. All evaluated models experience a sharp performance decline when facing conflicting instructions, compared to their original instruction-following performance. Moreover, the most competitive open-source model only achieves 48% accuracy in resolving such conflicts. Our results underscore the need for targeted optimization in the future development of LMs.