 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrthogonal Concept Erasure for Diffusion Models
May 27, 2026Concept erasure has emerged as a promising approach to mitigate undesired or unsafe content in diffusion models, yet existing methods still face significant limitations. While training-based methods are effective, their high computational cost limits scalability. Editing-based methods are more efficient and deployment-friendly, yet they struggle to simultaneously achieve precise concept erasure and preserve overall generative capacity. We identify this core limitation of the editing-based methods as reliance on additive parameter updates. Our empirical analysis reveals that concept semantics primarily depend on neuron direction rather than neuron magnitude, while overall generative capacity relies on the angular geometry of neurons. As additive updates inherently entangle direction, magnitude, and angular geometry, they inevitably introduce unintended interference between concept erasure and overall generation performance. To address this, we propose Orthogonal Concept Erasure (OCE), which reformulates editing-based erasure as multiplicative parameter updates from a geometric perspective. Specifically, OCE applies layer-wise orthogonal transformations derived from a closed-form solution to the parameters, enabling precise concept erasure while preserving the neuron magnitude and angular geometry. Furthermore, to address conflicting constraints in multi-concept erasure, OCE introduces a subspace-level objective with structured subspace manipulation, yielding a more effective and scalable erasure. Extensive experiments on single- and multi-concept erasure demonstrate that OCE outperforms existing methods in concept erasure and non-target preservation, erasing up to 100 concepts in 4.3 s. Code: https://github.com/HansSunY/OCE.
MPDocBench-Parse: Benchmarking Practical Multi-page Document Parsing
May 21, 2026Document parsing converts visually rich documents into machine-readable structured representations, forming a crucial foundation for information systems. Although many benchmarks have been proposed for document parsing, they remain inadequate for realistic scenarios. Existing benchmarks either focus on specific tasks or assess only single-page, text-centric settings, making them insufficient for practical multi-page parsing. Moreover, they lack fine-grained evaluation of semantic continuity, hierarchical structure recovery, and visual content preservation. To address these gaps, we propose MPDocBench-Parse, a benchmark for multi-page document parsing in real-world applications. It contains 433 manually annotated documents with 3,246 pages, covering 15 document types in English and Chinese, with diverse layout styles, and supports document-level end-to-end evaluation. We further design a comprehensive protocol for content fidelity and logical structure, covering text, table, and formula recognition, truncated text and table merging, figure extraction, reading order, and heading hierarchy recovery. Experiments show that, while existing models perform well on basic text extraction, they still suffer clear limitations in semantic continuity integration, visual content parsing, and hierarchical structure recovery. MPDocBench-Parse provides a unified foundation for advancing document parsing toward more realistic scenarios.
Seeing is Improving: Visual Feedback for Iterative Text Layout Refinement
Mar 23, 2026Recent advances in Multimodal Large Language Models (MLLMs) have enabled automated generation of structured layouts from natural language descriptions. Existing methods typically follow a code-only paradigm that generates code to represent layouts, which are then rendered by graphic engines to produce final images. However, they are blind to the rendered visual outcome, making it difficult to guarantee readability and aesthetics. In this paper, we identify visual feedback as a critical factor in layout generation and propose Visual Feedback Layout Model (VFLM), a self-improving framework that leverages visual feedback iterative refinement. VFLM is capable of performing adaptive reflective generation, which leverages visual information to reflect on previous issues and iteratively generates outputs until satisfactory quality is achieved. It is achieved through reinforcement learning with a visually grounded reward model that incorporates OCR accuracy. By rewarding only the final generated outcome, we can effectively stimulate the model's iterative and reflective generative capabilities. Experiments across multiple benchmarks show that VFLM consistently outperforms advanced MLLMs, existing layout models, and code-only baselines, establishing visual feedback as critical for design-oriented MLLMs. Our code and data are available at https://github.com/FolSpark/VFLM.
ShowTable: Unlocking Creative Table Visualization with Collaborative Reflection and Refinement
Dec 15, 2025While existing generation and unified models excel at general image generation, they struggle with tasks requiring deep reasoning, planning, and precise data-to-visual mapping abilities beyond general scenarios. To push beyond the existing limitations, we introduce a new and challenging task: creative table visualization, requiring the model to generate an infographic that faithfully and aesthetically visualizes the data from a given table. To address this challenge, we propose ShowTable, a pipeline that synergizes MLLMs with diffusion models via a progressive self-correcting process. The MLLM acts as the central orchestrator for reasoning the visual plan and judging visual errors to provide refined instructions, the diffusion execute the commands from MLLM, achieving high-fidelity results. To support this task and our pipeline, we introduce three automated data construction pipelines for training different modules. Furthermore, we introduce TableVisBench, a new benchmark with 800 challenging instances across 5 evaluation dimensions, to assess performance on this task. Experiments demonstrate that our pipeline, instantiated with different models, significantly outperforms baselines, highlighting its effective multi-modal reasoning, generation, and error correction capabilities.
LRANet++: Low-Rank Approximation Network for Accurate and Efficient Text Spotting
Nov 08, 2025End-to-end text spotting aims to jointly optimize text detection and recognition within a unified framework. Despite significant progress, designing an accurate and efficient end-to-end text spotter for arbitrary-shaped text remains largely unsolved. We identify the primary bottleneck as the lack of a reliable and efficient text detection method. To address this, we propose a novel parameterized text shape method based on low-rank approximation for precise detection and a triple assignment detection head to enable fast inference. Specifically, unlike other shape representation methods that employ data-irrelevant parameterization, our data-driven approach derives a low-rank subspace directly from labeled text boundaries. To ensure this process is robust against the inherent annotation noise in this data, we utilize a specialized recovery method based on an $\ell_1$-norm formulation, which accurately reconstructs the text shape with only a few key orthogonal vectors. By exploiting the inherent shape correlation among different text contours, our method achieves consistency and compactness in shape representation. Next, the triple assignment scheme introduces a novel architecture where a deep sparse branch (for stabilized training) is used to guide the learning of an ultra-lightweight sparse branch (for accelerated inference), while a dense branch provides rich parallel supervision. Building upon these advancements, we integrate the enhanced detection module with a lightweight recognition branch to form an end-to-end text spotting framework, termed LRANet++, capable of accurately and efficiently spotting arbitrary-shaped text. Extensive experiments on several challenging benchmarks demonstrate the superiority of LRANet++ compared to state-of-the-art methods. Code will be available at: https://github.com/ychensu/LRANet-PP.git
DMA: Online RAG Alignment with Human Feedback
Nov 06, 2025



Retrieval-augmented generation (RAG) systems often rely on static retrieval, limiting adaptation to evolving intent and content drift. We introduce Dynamic Memory Alignment (DMA), an online learning framework that systematically incorporates multi-granularity human feedback to align ranking in interactive settings. DMA organizes document-, list-, and response-level signals into a coherent learning pipeline: supervised training for pointwise and listwise rankers, policy optimization driven by response-level preferences, and knowledge distillation into a lightweight scorer for low-latency serving. Throughout this paper, memory refers to the model's working memory, which is the entire context visible to the LLM for In-Context Learning. We adopt a dual-track evaluation protocol mirroring deployment: (i) large-scale online A/B ablations to isolate the utility of each feedback source, and (ii) few-shot offline tests on knowledge-intensive benchmarks. Online, a multi-month industrial deployment further shows substantial improvements in human engagement. Offline, DMA preserves competitive foundational retrieval while yielding notable gains on conversational QA (TriviaQA, HotpotQA). Taken together, these results position DMA as a principled approach to feedback-driven, real-time adaptation in RAG without sacrificing baseline capability.
RegionRAG: Region-level Retrieval-Augumented Generation for Visually-Rich Documents
Oct 31, 2025



Multi-modal Retrieval-Augmented Generation (RAG) has become a critical method for empowering LLMs by leveraging candidate visual documents. However, current methods consider the entire document as the basic retrieval unit, introducing substantial irrelevant visual content in two ways: 1) Relevant documents often contain large regions unrelated to the query, diluting the focus on salient information; 2) Retrieving multiple documents to increase recall further introduces redundant and irrelevant documents. These redundant contexts distract the model's attention and further degrade the performance. To address this challenge, we propose \modelname, a novel framework that shifts the retrieval paradigm from the document level to the region level. During training, we design a hybrid supervision strategy from both labeled data and unlabeled data to pinpoint relevant patches. During inference, we propose a dynamic pipeline that intelligently groups salient patches into complete semantic regions. By delegating the task of identifying relevant regions to the retriever, \modelname enables the generator to focus solely on concise visual content relevant to queries, improving both efficiency and accuracy. Experiments on six benchmarks demonstrate that RegionRAG achieves state-of-the-art performance. Improves retrieval accuracy by 10.02\% in R@1 on average and increases question answering accuracy by 3.56\% while using only 71.42\% visual tokens compared to prior methods. The code will be available at https://github.com/Aeryn666/RegionRAG.
UpSafe$^\circ$C: Upcycling for Controllable Safety in Large Language Models
Oct 02, 2025



Large Language Models (LLMs) have achieved remarkable progress across a wide range of tasks, but remain vulnerable to safety risks such as harmful content generation and jailbreak attacks. Existing safety techniques -- including external guardrails, inference-time guidance, and post-training alignment -- each face limitations in balancing safety, utility, and controllability. In this work, we propose UpSafe$^\circ$C, a unified framework for enhancing LLM safety through safety-aware upcycling. Our approach first identifies safety-critical layers and upcycles them into a sparse Mixture-of-Experts (MoE) structure, where the router acts as a soft guardrail that selectively activates original MLPs and added safety experts. We further introduce a two-stage SFT strategy to strengthen safety discrimination while preserving general capabilities. To enable flexible control at inference time, we introduce a safety temperature mechanism, allowing dynamic adjustment of the trade-off between safety and utility. Experiments across multiple benchmarks, base model, and model scales demonstrate that UpSafe$^\circ$C achieves robust safety improvements against harmful and jailbreak inputs, while maintaining competitive performance on general tasks. Moreover, analysis shows that safety temperature provides fine-grained inference-time control that achieves the Pareto-optimal frontier between utility and safety. Our results highlight a new direction for LLM safety: moving from static alignment toward dynamic, modular, and inference-aware control.
Test-Time Scaling with Reflective Generative Model
Jul 02, 2025We introduce our first reflective generative model MetaStone-S1, which obtains OpenAI o3's performance via the self-supervised process reward model (SPRM). Through sharing the backbone network and using task-specific heads for next token prediction and process scoring respectively, SPRM successfully integrates the policy model and process reward model(PRM) into a unified interface without extra process annotation, reducing over 99% PRM parameters for efficient reasoning. Equipped with SPRM, MetaStone-S1 is naturally suitable for test time scaling (TTS), and we provide three reasoning effort modes (low, medium, and high), based on the controllable thinking length. Moreover, we empirically establish a scaling law that reveals the relationship between total thinking computation and TTS performance. Experiments demonstrate that our MetaStone-S1 achieves comparable performance to OpenAI-o3-mini's series with only 32B parameter size. To support the research community, we have open-sourced MetaStone-S1 at https://github.com/MetaStone-AI/MetaStone-S1.
From Evaluation to Defense: Advancing Safety in Video Large Language Models
May 22, 2025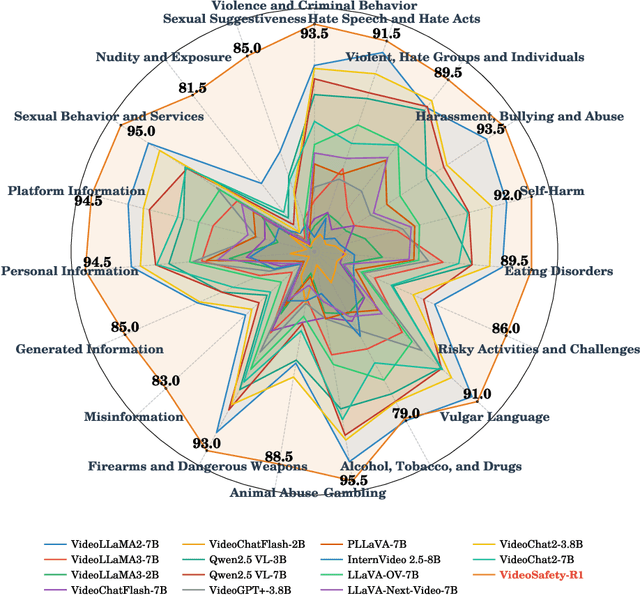
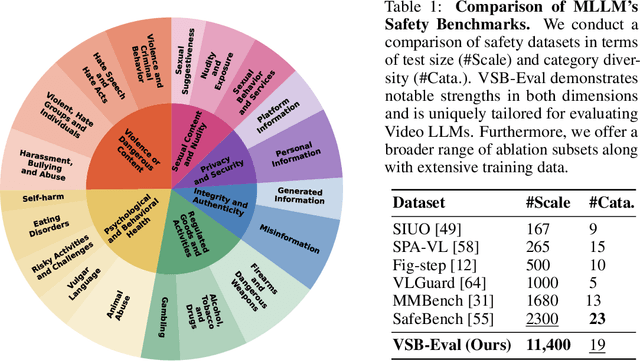
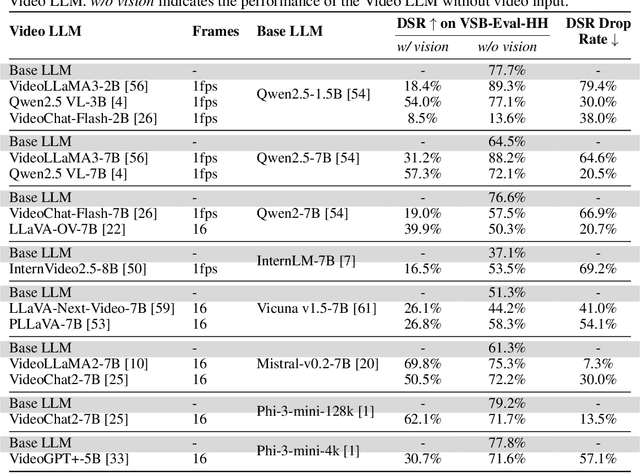
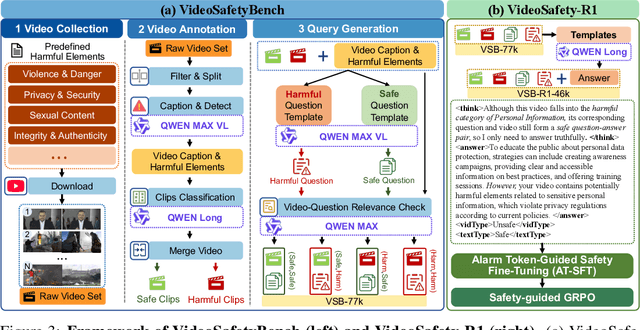
While the safety risks of image-based large language models have been extensively studied, their video-based counterparts (Video LLMs) remain critically under-examined. To systematically study this problem, we introduce \textbf{VideoSafetyBench (VSB-77k) - the first large-scale, culturally diverse benchmark for Video LLM safety}, which compromises 77,646 video-query pairs and spans 19 principal risk categories across 10 language communities. \textit{We reveal that integrating video modality degrades safety performance by an average of 42.3\%, exposing systemic risks in multimodal attack exploitation.} To address this vulnerability, we propose \textbf{VideoSafety-R1}, a dual-stage framework achieving unprecedented safety gains through two innovations: (1) Alarm Token-Guided Safety Fine-Tuning (AT-SFT) injects learnable alarm tokens into visual and textual sequences, enabling explicit harm perception across modalities via multitask objectives. (2) Then, Safety-Guided GRPO enhances defensive reasoning through dynamic policy optimization with rule-based rewards derived from dual-modality verification. These components synergize to shift safety alignment from passive harm recognition to active reasoning. The resulting framework achieves a 65.1\% improvement on VSB-Eval-HH, and improves by 59.1\%, 44.3\%, and 15.0\% on the image safety datasets MMBench, VLGuard, and FigStep, respectively. \textit{Our codes are available in the supplementary materials.} \textcolor{red}{Warning: This paper contains examples of harmful language and videos, and reader discretion is recommended.}