 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreetCrafter: Street View Synthesis with Controllable Video Diffusion Models
Dec 17, 2024



This paper aims to tackle the problem of photorealistic view synthesis from vehicle sensor data. Recent advancements in neural scene representation have achieved notable success in rendering high-quality autonomous driving scenes, but the performance significantly degrades as the viewpoint deviates from the training trajectory. To mitigate this problem, we introduce StreetCrafter, a novel controllable video diffusion model that utilizes LiDAR point cloud renderings as pixel-level conditions, which fully exploits the generative prior for novel view synthesis, while preserving precise camera control. Moreover, the utilization of pixel-level LiDAR conditions allows us to make accurate pixel-level edits to target scenes. In addition, the generative prior of StreetCrafter can be effectively incorporated into dynamic scene representations to achieve real-time rendering. Experiments on Waymo Open Dataset and PandaSet demonstrate that our model enables flexible control over viewpoint changes, enlarging the view synthesis regions for satisfying rendering, which outperforms existing methods.
ReconDreamer: Crafting World Models for Driving Scene Reconstruction via Online Restoration
Nov 29, 2024



Closed-loop simulation is crucial for end-to-end autonomous driving. Existing sensor simulation methods (e.g., NeRF and 3DGS) reconstruct driving scenes based on conditions that closely mirror training data distributions. However, these methods struggle with rendering novel trajectories, such as lane changes. Recent works have demonstrated that integrating world model knowledge alleviates these issues. Despite their efficiency, these approaches still encounter difficulties in the accurate representation of more complex maneuvers, with multi-lane shifts being a notable example. Therefore, we introduce ReconDreamer, which enhances driving scene reconstruction through incremental integration of world model knowledge. Specifically, DriveRestorer is proposed to mitigate artifacts via online restoration. This is complemented by a progressive data update strategy designed to ensure high-quality rendering for more complex maneuvers. To the best of our knowledge, ReconDreamer is the first method to effectively render in large maneuvers. Experimental results demonstrate that ReconDreamer outperforms Street Gaussians in the NTA-IoU, NTL-IoU, and FID, with relative improvements by 24.87%, 6.72%, and 29.97%. Furthermore, ReconDreamer surpasses DriveDreamer4D with PVG during large maneuver rendering, as verified by a relative improvement of 195.87% in the NTA-IoU metric and a comprehensive user study.
Marconi: Prefix Caching for the Era of Hybrid LLMs
Nov 28, 2024



Hybrid models that combine the language modeling capabilities of Attention layers with the efficiency of Recurrent layers (e.g., State Space Models) have gained traction in practically supporting long contexts in Large Language Model serving. Yet, the unique properties of these models complicate the usage of complementary efficiency optimizations such as prefix caching that skip redundant computations across requests. Most notably, their use of in-place state updates for recurrent layers precludes rolling back cache entries for partial sequence overlaps, and instead mandates only exact-match cache hits; the effect is a deluge of (large) cache entries per sequence, most of which yield minimal reuse opportunities. We present Marconi, the first system that supports efficient prefix caching with Hybrid LLMs. Key to Marconi are its novel admission and eviction policies that more judiciously assess potential cache entries based not only on recency, but also on (1) forecasts of their reuse likelihood across a taxonomy of different hit scenarios, and (2) the compute savings that hits deliver relative to memory footprints. Across diverse workloads and Hybrid models, Marconi achieves up to 34.4$\times$ higher token hit rates (71.1% or 617 ms lower TTFT) compared to state-of-the-art prefix caching systems.
Training-free Regional Prompting for Diffusion Transformers
Nov 04, 2024
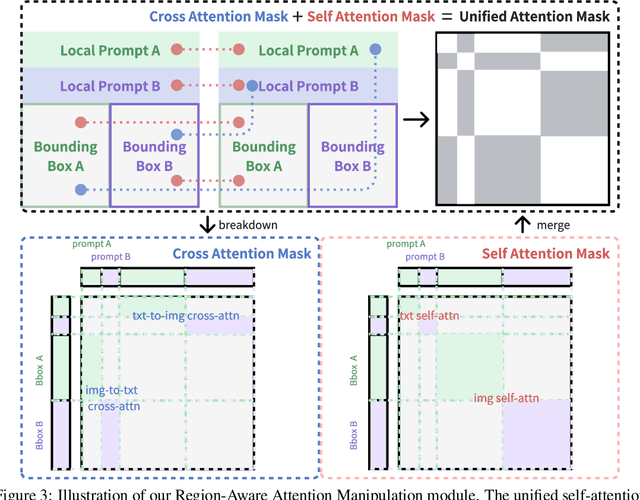
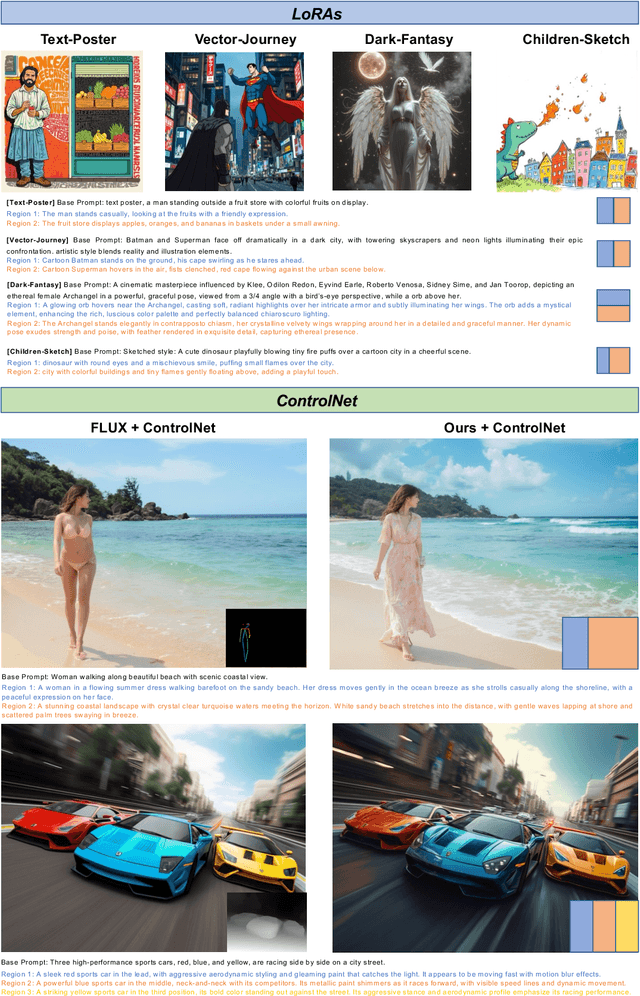

Diffusion models have demonstrated excellent capabilities in text-to-image generation. Their semantic understanding (i.e., prompt following) ability has also been greatly improved with large language models (e.g., T5, Llama). However, existing models cannot perfectly handle long and complex text prompts, especially when the text prompts contain various objects with numerous attributes and interrelated spatial relationships. While many regional prompting methods have been proposed for UNet-based models (SD1.5, SDXL), but there are still no implementations based on the recent Diffusion Transformer (DiT) architecture, such as SD3 and FLUX.1.In this report, we propose and implement regional prompting for FLUX.1 based on attention manipulation, which enables DiT with fined-grained compositional text-to-image generation capability in a training-free manner. Code is available at https://github.com/antonioo-c/Regional-Prompting-FLUX.
MVGS: Multi-view-regulated Gaussian Splatting for Novel View Synthesis
Oct 02, 2024



Recent works in volume rendering, \textit{e.g.} NeRF and 3D Gaussian Splatting (3DGS), significantly advance the rendering quality and efficiency with the help of the learned implicit neural radiance field or 3D Gaussians. Rendering on top of an explicit representation, the vanilla 3DGS and its variants deliver real-time efficiency by optimizing the parametric model with single-view supervision per iteration during training which is adopted from NeRF. Consequently, certain views are overfitted, leading to unsatisfying appearance in novel-view synthesis and imprecise 3D geometries. To solve aforementioned problems, we propose a new 3DGS optimization method embodying four key novel contributions: 1) We transform the conventional single-view training paradigm into a multi-view training strategy. With our proposed multi-view regulation, 3D Gaussian attributes are further optimized without overfitting certain training views. As a general solution, we improve the overall accuracy in a variety of scenarios and different Gaussian variants. 2) Inspired by the benefit introduced by additional views, we further propose a cross-intrinsic guidance scheme, leading to a coarse-to-fine training procedure concerning different resolutions. 3) Built on top of our multi-view regulated training, we further propose a cross-ray densification strategy, densifying more Gaussian kernels in the ray-intersect regions from a selection of views. 4) By further investigating the densification strategy, we found that the effect of densification should be enhanced when certain views are distinct dramatically. As a solution, we propose a novel multi-view augmented densification strategy, where 3D Gaussians are encouraged to get densified to a sufficient number accordingly, resulting in improved reconstruction accuracy.
Inference Optimization of Foundation Models on AI Accelerators
Jul 12, 2024



Powerful foundation models, including large language models (LLMs), with Transformer architectures have ushered in a new era of Generative AI across various industries. Industry and research community have witnessed a large number of new applications, based on those foundation models. Such applications include question and answer, customer services, image and video generation, and code completions, among others. However, as the number of model parameters reaches to hundreds of billions, their deployment incurs prohibitive inference costs and high latency in real-world scenarios. As a result, the demand for cost-effective and fast inference using AI accelerators is ever more higher. To this end, our tutorial offers a comprehensive discussion on complementary inference optimization techniques using AI accelerators. Beginning with an overview of basic Transformer architectures and deep learning system frameworks, we deep dive into system optimization techniques for fast and memory-efficient attention computations and discuss how they can be implemented efficiently on AI accelerators. Next, we describe architectural elements that are key for fast transformer inference. Finally, we examine various model compression and fast decoding strategies in the same context.
RaNeuS: Ray-adaptive Neural Surface Reconstruction
Jun 14, 2024Our objective is to leverage a differentiable radiance field \eg NeRF to reconstruct detailed 3D surfaces in addition to producing the standard novel view renderings. There have been related methods that perform such tasks, usually by utilizing a signed distance field (SDF). However, the state-of-the-art approaches still fail to correctly reconstruct the small-scale details, such as the leaves, ropes, and textile surfaces. Considering that different methods formulate and optimize the projection from SDF to radiance field with a globally constant Eikonal regularization, we improve with a ray-wise weighting factor to prioritize the rendering and zero-crossing surface fitting on top of establishing a perfect SDF. We propose to adaptively adjust the regularization on the signed distance field so that unsatisfying rendering rays won't enforce strong Eikonal regularization which is ineffective, and allow the gradients from regions with well-learned radiance to effectively back-propagated to the SDF. Consequently, balancing the two objectives in order to generate accurate and detailed surfaces. Additionally, concerning whether there is a geometric bias between the zero-crossing surface in SDF and rendering points in the radiance field, the projection becomes adjustable as well depending on different 3D locations during optimization. Our proposed \textit{RaNeuS} are extensively evaluated on both synthetic and real datasets, achieving state-of-the-art results on both novel view synthesis and geometric reconstruction.
Lancet: Accelerating Mixture-of-Experts Training via Whole Graph Computation-Communication Overlapping
Apr 30, 2024



The Mixture-of-Expert (MoE) technique plays a crucial role in expanding the size of DNN model parameters. However, it faces the challenge of extended all-to-all communication latency during the training process. Existing methods attempt to mitigate this issue by overlapping all-to-all with expert computation. Yet, these methods frequently fall short of achieving sufficient overlap, consequently restricting the potential for performance enhancements. In our study, we extend the scope of this challenge by considering overlap at the broader training graph level. During the forward pass, we enable non-MoE computations to overlap with all-to-all through careful partitioning and pipelining. In the backward pass, we achieve overlap with all-to-all by scheduling gradient weight computations. We implement these techniques in Lancet, a system using compiler-based optimization to automatically enhance MoE model training. Our extensive evaluation reveals that Lancet significantly reduces the time devoted to non-overlapping communication, by as much as 77%. Moreover, it achieves a notable end-to-end speedup of up to 1.3 times when compared to the state-of-the-art solutions.
High-fidelity Endoscopic Image Synthesis by Utilizing Depth-guided Neural Surfaces
Apr 20, 2024In surgical oncology, screening colonoscopy plays a pivotal role in providing diagnostic assistance, such as biopsy, and facilitating surgical navigation, particularly in polyp detection. Computer-assisted endoscopic surgery has recently gained attention and amalgamated various 3D computer vision techniques, including camera localization, depth estimation, surface reconstruction, etc. Neural Radiance Fields (NeRFs) and Neural Implicit Surfaces (NeuS) have emerged as promising methodologies for deriving accurate 3D surface models from sets of registered images, addressing the limitations of existing colon reconstruction approaches stemming from constrained camera movement. However, the inadequate tissue texture representation and confused scale problem in monocular colonoscopic image reconstruction still impede the progress of the final rendering results. In this paper, we introduce a novel method for colon section reconstruction by leveraging NeuS applied to endoscopic images, supplemented by a single frame of depth map. Notably, we pioneered the exploration of utilizing only one frame depth map in photorealistic reconstruction and neural rendering applications while this single depth map can be easily obtainable from other monocular depth estimation networks with an object scale. Through rigorous experimentation and validation on phantom imagery, our approach demonstrates exceptional accuracy in completely rendering colon sections, even capturing unseen portions of the surface. This breakthrough opens avenues for achieving stable and consistently scaled reconstructions, promising enhanced quality in cancer screening procedures and treatment interventions.
HLAT: High-quality Large Language Model Pre-trained on AWS Trainium
Apr 16, 2024



Getting large language models (LLMs) to perform well on the downstream tasks requires pre-training over trillions of tokens. This typically demands a large number of powerful computational devices in addition to a stable distributed training framework to accelerate the training. The growing number of applications leveraging AI/ML had led to a scarcity of the expensive conventional accelerators (such as GPUs), which begs the need for the alternative specialized-accelerators that are scalable and cost-efficient. AWS Trainium is the second-generation machine learning accelerator that has been purposely built for training large deep learning models. Its corresponding instance, Amazon EC2 trn1, is an alternative to GPU instances for LLM training. However, training LLMs with billions of parameters on trn1 is challenging due to its relatively nascent software ecosystem. In this paper, we showcase HLAT: a 7 billion parameter decoder-only LLM pre-trained using trn1 instances over 1.8 trillion tokens. The performance of HLAT is benchmarked against popular open source baseline models including LLaMA and OpenLLaMA, which have been trained on NVIDIA GPUs and Google TPUs, respectively. On various evaluation tasks, we show that HLAT achieves model quality on par with the baselines. We also share the best practice of using the Neuron Distributed Training Library (NDTL), a customized distributed training library for AWS Trainium to achieve efficient training. Our work demonstrates that AWS Trainium powered by the NDTL is able to successfully pre-train state-of-the-art LLM models with high performance and cost-effectiveness.