 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement-aware Knowledge Distillation for LLM Reasoning
Feb 26, 2026Reinforcement learning (RL) post-training has recently driven major gains in long chain-of-thought reasoning large language models (LLMs), but the high inference cost of such models motivates distillation into smaller students. Most existing knowledge distillation (KD) methods are designed for supervised fine-tuning (SFT), relying on fixed teacher traces or teacher-student Kullback-Leibler (KL) divergence-based regularization. When combined with RL, these approaches often suffer from distribution mismatch and objective interference: teacher supervision may not align with the student's evolving rollout distribution, and the KL regularizer can compete with reward maximization and require careful loss balancing. To address these issues, we propose RL-aware distillation (RLAD), which performs selective imitation during RL -- guiding the student toward the teacher only when it improves the current policy update. Our core component, Trust Region Ratio Distillation (TRRD), replaces the teacher-student KL regularizer with a PPO/GRPO-style likelihood-ratio objective anchored to a teacher--old-policy mixture, yielding advantage-aware, trust-region-bounded distillation on student rollouts and naturally balancing exploration, exploitation, and imitation. Across diverse logic reasoning and math benchmarks, RLAD consistently outperforms offline distillation, standard GRPO, and KL-based on-policy teacher-student knowledge distillation.
Learning to Focus: Focal Attention for Selective and Scalable Transformers
Nov 10, 2025Attention is a core component of transformer architecture, whether encoder-only, decoder-only, or encoder-decoder model. However, the standard softmax attention often produces noisy probability distribution, which can impair effective feature selection at every layer of these models, particularly for long contexts. We propose Focal Attention, a simple yet effective modification that sharpens the attention distribution by controlling the softmax temperature, either as a fixed hyperparameter or as a learnable parameter during training. This sharpening enables the model to concentrate on the most relevant tokens while suppressing irrelevant ones. Empirically, Focal Attention scales more favorably than standard transformer with respect to model size, training data, and context length. Across diverse benchmarks, it achieves the same accuracy with up to 42% fewer parameters or 33% less training data. On long-context tasks, it delivers substantial relative improvements ranging from 17% to 82%, demonstrating its effectiveness in real world applications.
Sequence-level Large Language Model Training with Contrastive Preference Optimization
Feb 23, 2025



The next token prediction loss is the dominant self-supervised training objective for large language models and has achieved promising results in a variety of downstream tasks. However, upon closer investigation of this objective, we find that it lacks an understanding of sequence-level signals, leading to a mismatch between training and inference processes. To bridge this gap, we introduce a contrastive preference optimization (CPO) procedure that can inject sequence-level information into the language model at any training stage without expensive human labeled data. Our experiments show that the proposed objective surpasses the next token prediction in terms of win rate in the instruction-following and text generation tasks.
DEM: Distribution Edited Model for Training with Mixed Data Distributions
Jun 21, 2024



Training with mixed data distributions is a common and important part of creating multi-task and instruction-following models. The diversity of the data distributions and cost of joint training makes the optimization procedure extremely challenging. Data mixing methods partially address this problem, albeit having a sub-optimal performance across data sources and require multiple expensive training runs. In this paper, we propose a simple and efficient alternative for better optimization of the data sources by combining models individually trained on each data source with the base model using basic element-wise vector operations. The resulting model, namely Distribution Edited Model (DEM), is 11x cheaper than standard data mixing and outperforms strong baselines on a variety of benchmarks, yielding up to 6.2% improvement on MMLU, 11.5% on BBH, 16.1% on DROP, and 9.3% on HELM with models of size 3B to 13B. Notably, DEM does not require full re-training when modifying a single data-source, thus making it very flexible and scalable for training with diverse data sources.
HLAT: High-quality Large Language Model Pre-trained on AWS Trainium
Apr 16, 2024



Getting large language models (LLMs) to perform well on the downstream tasks requires pre-training over trillions of tokens. This typically demands a large number of powerful computational devices in addition to a stable distributed training framework to accelerate the training. The growing number of applications leveraging AI/ML had led to a scarcity of the expensive conventional accelerators (such as GPUs), which begs the need for the alternative specialized-accelerators that are scalable and cost-efficient. AWS Trainium is the second-generation machine learning accelerator that has been purposely built for training large deep learning models. Its corresponding instance, Amazon EC2 trn1, is an alternative to GPU instances for LLM training. However, training LLMs with billions of parameters on trn1 is challenging due to its relatively nascent software ecosystem. In this paper, we showcase HLAT: a 7 billion parameter decoder-only LLM pre-trained using trn1 instances over 1.8 trillion tokens. The performance of HLAT is benchmarked against popular open source baseline models including LLaMA and OpenLLaMA, which have been trained on NVIDIA GPUs and Google TPUs, respectively. On various evaluation tasks, we show that HLAT achieves model quality on par with the baselines. We also share the best practice of using the Neuron Distributed Training Library (NDTL), a customized distributed training library for AWS Trainium to achieve efficient training. Our work demonstrates that AWS Trainium powered by the NDTL is able to successfully pre-train state-of-the-art LLM models with high performance and cost-effectiveness.
Efficient Long-Range Transformers: You Need to Attend More, but Not Necessarily at Every Layer
Oct 19, 2023



Pretrained transformer models have demonstrated remarkable performance across various natural language processing tasks. These models leverage the attention mechanism to capture long- and short-range dependencies in the sequence. However, the (full) attention mechanism incurs high computational cost - quadratic in the sequence length, which is not affordable in tasks with long sequences, e.g., inputs with 8k tokens. Although sparse attention can be used to improve computational efficiency, as suggested in existing work, it has limited modeling capacity and often fails to capture complicated dependencies in long sequences. To tackle this challenge, we propose MASFormer, an easy-to-implement transformer variant with Mixed Attention Spans. Specifically, MASFormer is equipped with full attention to capture long-range dependencies, but only at a small number of layers. For the remaining layers, MASformer only employs sparse attention to capture short-range dependencies. Our experiments on natural language modeling and generation tasks show that a decoder-only MASFormer model of 1.3B parameters can achieve competitive performance to vanilla transformers with full attention while significantly reducing computational cost (up to 75%). Additionally, we investigate the effectiveness of continual training with long sequence data and how sequence length impacts downstream generation performance, which may be of independent interest.
Neural Network based End-to-End Query by Example Spoken Term Detection
Nov 19, 2019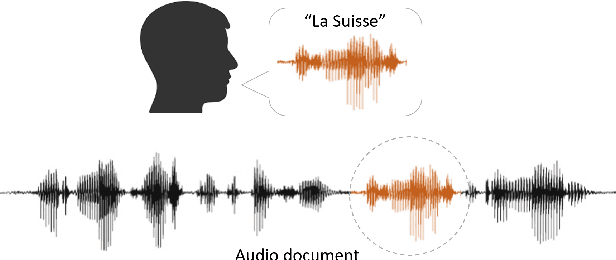
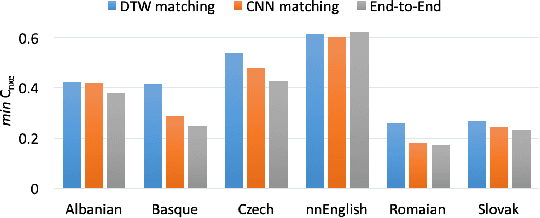
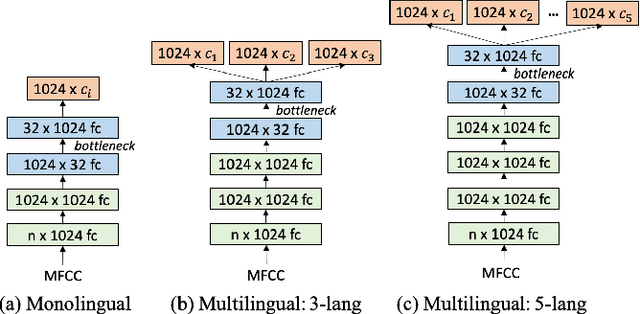
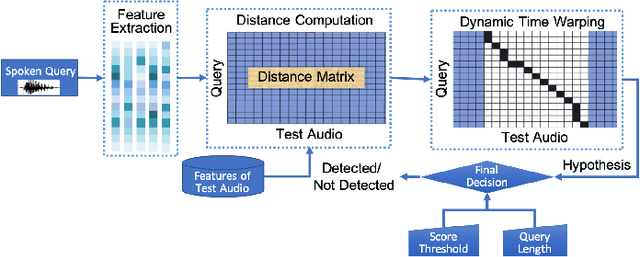
This paper focuses on the problem of query by example spoken term detection (QbE-STD) in zero-resource scenario. State-of-the-art approaches primarily rely on dynamic time warping (DTW) based template matching techniques using phone posterior or bottleneck features extracted from a deep neural network (DNN). We use both monolingual and multilingual bottleneck features, and show that multilingual features perform increasingly better with more training languages. Previously, it has been shown that the DTW based matching can be replaced with a CNN based matching while using posterior features. Here, we show that the CNN based matching outperforms DTW based matching using bottleneck features as well. In this case, the feature extraction and pattern matching stages of our QbE-STD system are optimized independently of each other. We propose to integrate these two stages in a fully neural network based end-to-end learning framework to enable joint optimization of those two stages simultaneously. The proposed approaches are evaluated on two challenging multilingual datasets: Spoken Web Search 2013 and Query by Example Search on Speech Task 2014, demonstrating in each case significant improvements.
Multilingual Bottleneck Features for Query by Example Spoken Term Detection
Jun 30, 2019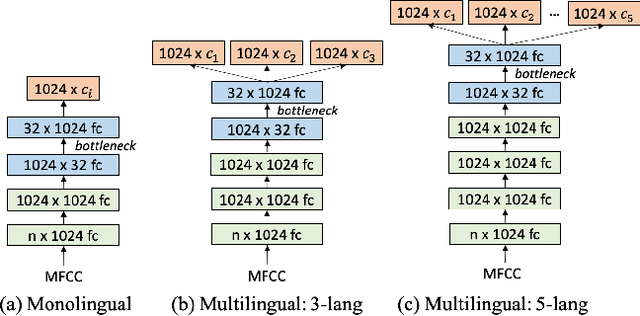
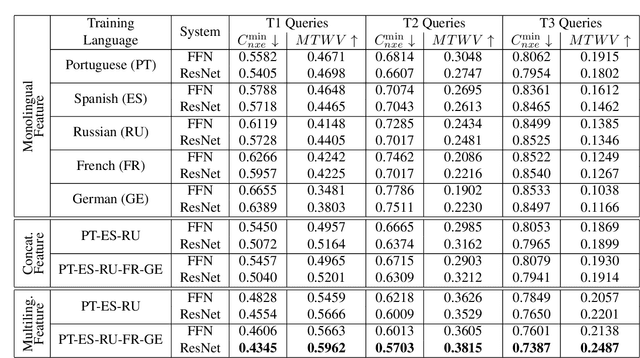
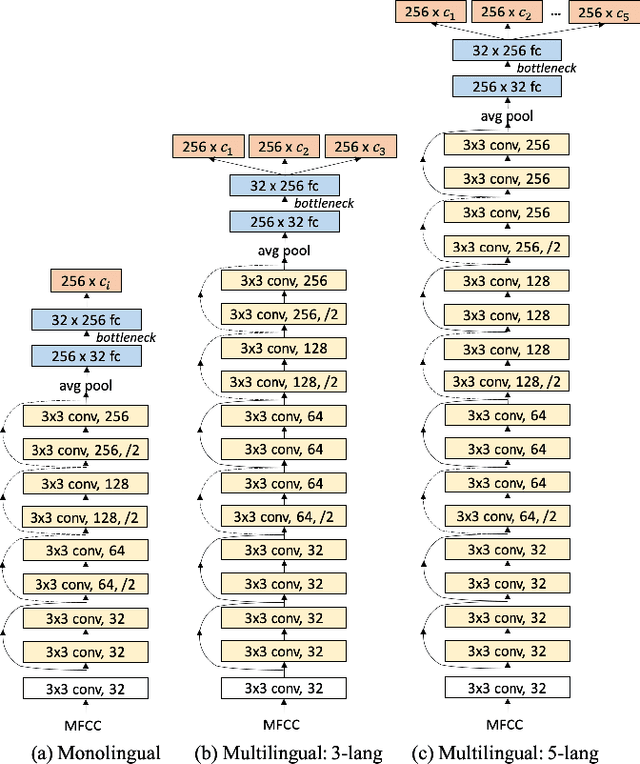
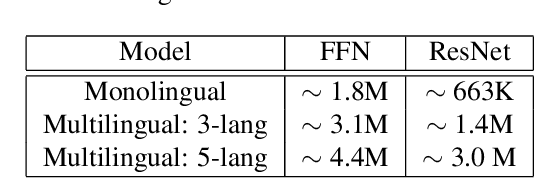
State of the art solutions to query by example spoken term detection (QbE-STD) usually rely on bottleneck feature representation of the query and audio document to perform dynamic time warping (DTW) based template matching. Here, we present a study on QbE-STD performance using several monolingual as well as multilingual bottleneck features extracted from feed forward networks. Then, we propose to employ residual networks (ResNet) to estimate the bottleneck features and show significant improvements over the corresponding feed forward network based features. The neural networks are trained on GlobalPhone corpus and QbE-STD experiments are performed on a very challenging QUESST 2014 database.
Self-Attentive Residual Decoder for Neural Machine Translation
Oct 01, 2018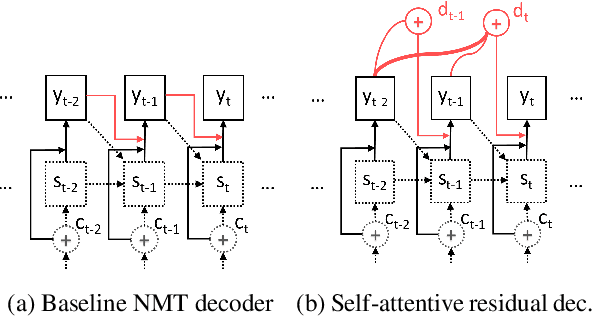
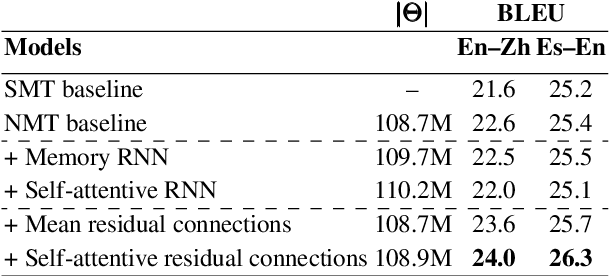
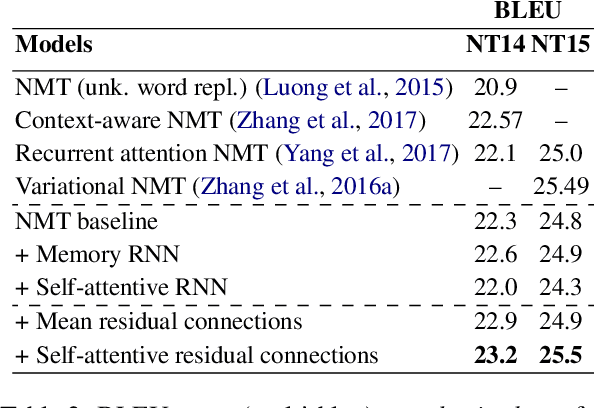
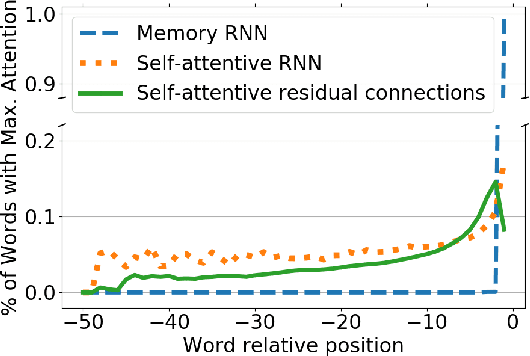
Neural sequence-to-sequence networks with attention have achieved remarkable performance for machine translation. One of the reasons for their effectiveness is their ability to capture relevant source-side contextual information at each time-step prediction through an attention mechanism. However, the target-side context is solely based on the sequence model which, in practice, is prone to a recency bias and lacks the ability to capture effectively non-sequential dependencies among words. To address this limitation, we propose a target-side-attentive residual recurrent network for decoding, where attention over previous words contributes directly to the prediction of the next word. The residual learning facilitates the flow of information from the distant past and is able to emphasize any of the previously translated words, hence it gains access to a wider context. The proposed model outperforms a neural MT baseline as well as a memory and self-attention network on three language pairs. The analysis of the attention learned by the decoder confirms that it emphasizes a wider context, and that it captures syntactic-like structures.
Document-Level Neural Machine Translation with Hierarchical Attention Networks
Oct 01, 2018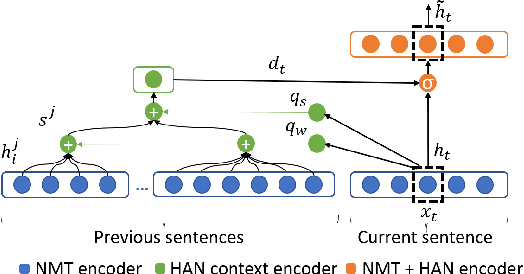
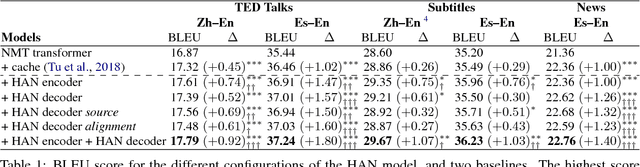
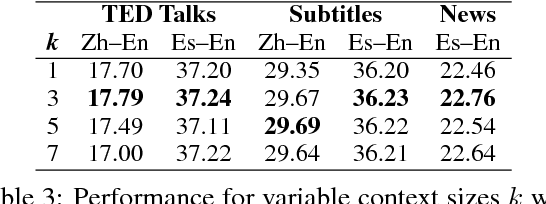
Neural Machine Translation (NMT) can be improved by including document-level contextual information. For this purpose, we propose a hierarchical attention model to capture the context in a structured and dynamic manner. The model is integrated in the original NMT architecture as another level of abstraction, conditioning on the NMT model's own previous hidden states. Experiments show that hierarchical attention significantly improves the BLEU score over a strong NMT baseline with the state-of-the-art in context-aware methods, and that both the encoder and decoder benefit from context in complementary ways.