 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAPNext++: What's Next for Tracking Any Point (TAP)?
Apr 12, 2026Tracking-Any-Point (TAP) models aim to track any point through a video which is a crucial task in AR/XR and robotics applications. The recently introduced TAPNext approach proposes an end-to-end, recurrent transformer architecture to track points frame-by-frame in a purely online fashion -- demonstrating competitive performance at minimal latency. However, we show that TAPNext struggles with longer video sequences and also frequently fails to re-detect query points that reappear after being occluded or leaving the frame. In this work, we present TAPNext++, a model that tracks points in sequences that are orders of magnitude longer while preserving the low memory and compute footprint of the architecture. We train the recurrent video transformer using several data-driven solutions, including training on long 1024-frame sequences enabled by sequence parallelism techniques. We highlight that re-detection performance is a blind spot in the current literature and introduce a new metric, Re-Detection Average Jaccard ($AJ_{RD}$), to explicitly evaluate tracking on re-appearing points. To improve re-detection of points, we introduce tailored geometric augmentations, such as periodic roll that simulates point re-entries, and supervising occluded points. We demonstrate that recurrent transformers can be substantially improved for point tracking and set a new state-of-the-art on multiple benchmarks. Model and code can be found at https://tap-next-plus-plus.github.io.
Towards Real-Time Open-Vocabulary Video Instance Segmentation
Dec 05, 2024In this paper, we address the challenge of performing open-vocabulary video instance segmentation (OV-VIS) in real-time. We analyze the computational bottlenecks of state-of-the-art foundation models that performs OV-VIS, and propose a new method, TROY-VIS, that significantly improves processing speed while maintaining high accuracy. We introduce three key techniques: (1) Decoupled Attention Feature Enhancer to speed up information interaction between different modalities and scales; (2) Flash Embedding Memory for obtaining fast text embeddings of object categories; and, (3) Kernel Interpolation for exploiting the temporal continuity in videos. Our experiments demonstrate that TROY-VIS achieves the best trade-off between accuracy and speed on two large-scale OV-VIS benchmarks, BURST and LV-VIS, running 20x faster than GLEE-Lite (25 FPS v.s. 1.25 FPS) with comparable or even better accuracy. These results demonstrate TROY-VIS's potential for real-time applications in dynamic environments such as mobile robotics and augmented reality. Code and model will be released at https://github.com/google-research/troyvis.
RaNeuS: Ray-adaptive Neural Surface Reconstruction
Jun 14, 2024Our objective is to leverage a differentiable radiance field \eg NeRF to reconstruct detailed 3D surfaces in addition to producing the standard novel view renderings. There have been related methods that perform such tasks, usually by utilizing a signed distance field (SDF). However, the state-of-the-art approaches still fail to correctly reconstruct the small-scale details, such as the leaves, ropes, and textile surfaces. Considering that different methods formulate and optimize the projection from SDF to radiance field with a globally constant Eikonal regularization, we improve with a ray-wise weighting factor to prioritize the rendering and zero-crossing surface fitting on top of establishing a perfect SDF. We propose to adaptively adjust the regularization on the signed distance field so that unsatisfying rendering rays won't enforce strong Eikonal regularization which is ineffective, and allow the gradients from regions with well-learned radiance to effectively back-propagated to the SDF. Consequently, balancing the two objectives in order to generate accurate and detailed surfaces. Additionally, concerning whether there is a geometric bias between the zero-crossing surface in SDF and rendering points in the radiance field, the projection becomes adjustable as well depending on different 3D locations during optimization. Our proposed \textit{RaNeuS} are extensively evaluated on both synthetic and real datasets, achieving state-of-the-art results on both novel view synthesis and geometric reconstruction.
SemiVL: Semi-Supervised Semantic Segmentation with Vision-Language Guidance
Nov 27, 2023In semi-supervised semantic segmentation, a model is trained with a limited number of labeled images along with a large corpus of unlabeled images to reduce the high annotation effort. While previous methods are able to learn good segmentation boundaries, they are prone to confuse classes with similar visual appearance due to the limited supervision. On the other hand, vision-language models (VLMs) are able to learn diverse semantic knowledge from image-caption datasets but produce noisy segmentation due to the image-level training. In SemiVL, we propose to integrate rich priors from VLM pre-training into semi-supervised semantic segmentation to learn better semantic decision boundaries. To adapt the VLM from global to local reasoning, we introduce a spatial fine-tuning strategy for label-efficient learning. Further, we design a language-guided decoder to jointly reason over vision and language. Finally, we propose to handle inherent ambiguities in class labels by providing the model with language guidance in the form of class definitions. We evaluate SemiVL on 4 semantic segmentation datasets, where it significantly outperforms previous semi-supervised methods. For instance, SemiVL improves the state-of-the-art by +13.5 mIoU on COCO with 232 annotated images and by +6.1 mIoU on Pascal VOC with 92 labels. Project page: https://github.com/google-research/semivl
Shape, Pose, and Appearance from a Single Image via Bootstrapped Radiance Field Inversion
Nov 21, 2022



Neural Radiance Fields (NeRF) coupled with GANs represent a promising direction in the area of 3D reconstruction from a single view, owing to their ability to efficiently model arbitrary topologies. Recent work in this area, however, has mostly focused on synthetic datasets where exact ground-truth poses are known, and has overlooked pose estimation, which is important for certain downstream applications such as augmented reality (AR) and robotics. We introduce a principled end-to-end reconstruction framework for natural images, where accurate ground-truth poses are not available. Our approach recovers an SDF-parameterized 3D shape, pose, and appearance from a single image of an object, without exploiting multiple views during training. More specifically, we leverage an unconditional 3D-aware generator, to which we apply a hybrid inversion scheme where a model produces a first guess of the solution which is then refined via optimization. Our framework can de-render an image in as few as 10 steps, enabling its use in practical scenarios. We demonstrate state-of-the-art results on a variety of real and synthetic benchmarks.
SoftPool++: An Encoder-Decoder Network for Point Cloud Completion
May 08, 2022
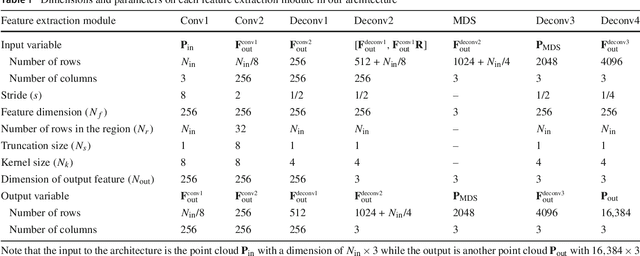
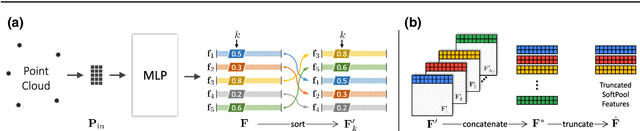
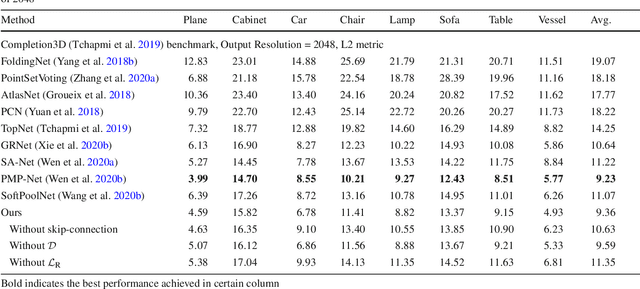
We propose a novel convolutional operator for the task of point cloud completion. One striking characteristic of our approach is that, conversely to related work it does not require any max-pooling or voxelization operation. Instead, the proposed operator used to learn the point cloud embedding in the encoder extracts permutation-invariant features from the point cloud via a soft-pooling of feature activations, which are able to preserve fine-grained geometric details. These features are then passed on to a decoder architecture. Due to the compression in the encoder, a typical limitation of this type of architectures is that they tend to lose parts of the input shape structure. We propose to overcome this limitation by using skip connections specifically devised for point clouds, where links between corresponding layers in the encoder and the decoder are established. As part of these connections, we introduce a transformation matrix that projects the features from the encoder to the decoder and vice-versa. The quantitative and qualitative results on the task of object completion from partial scans on the ShapeNet dataset show that incorporating our approach achieves state-of-the-art performance in shape completion both at low and high resolutions.
* Accepted in International Journal of Computer Vision
Learning Local Displacements for Point Cloud Completion
Mar 30, 2022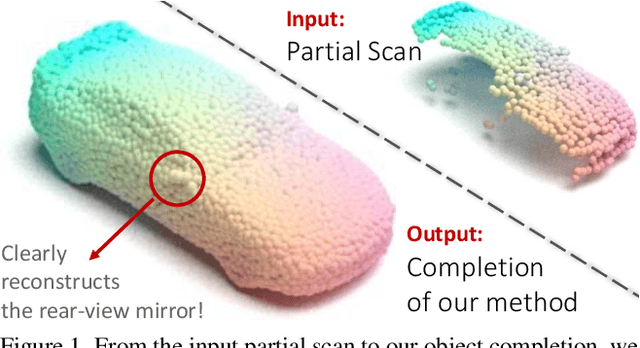
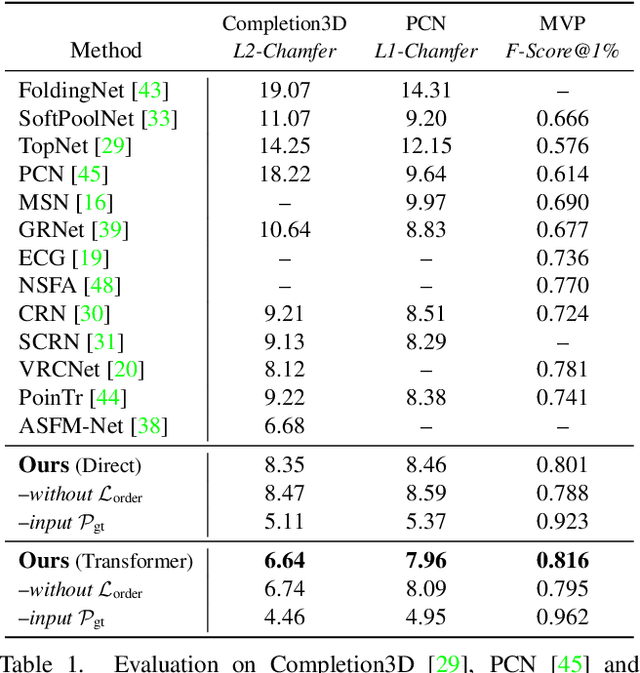
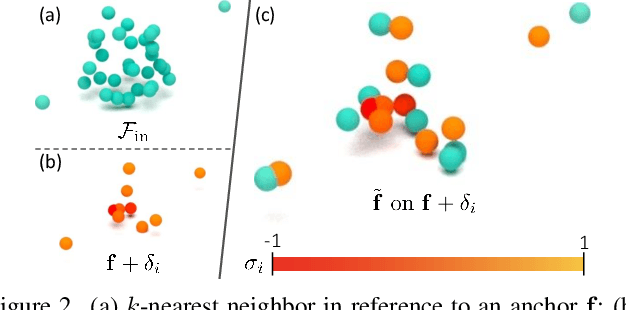
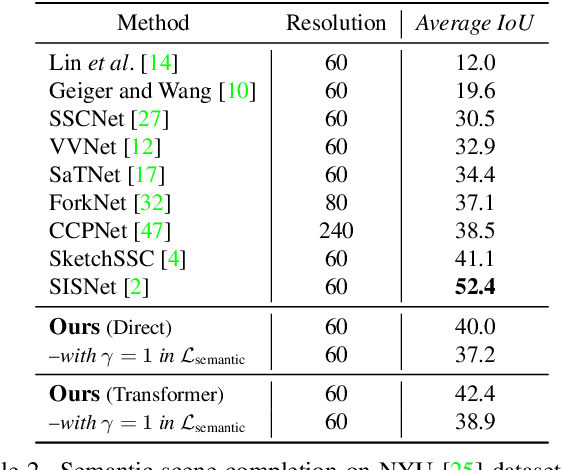
We propose a novel approach aimed at object and semantic scene completion from a partial scan represented as a 3D point cloud. Our architecture relies on three novel layers that are used successively within an encoder-decoder structure and specifically developed for the task at hand. The first one carries out feature extraction by matching the point features to a set of pre-trained local descriptors. Then, to avoid losing individual descriptors as part of standard operations such as max-pooling, we propose an alternative neighbor-pooling operation that relies on adopting the feature vectors with the highest activations. Finally, up-sampling in the decoder modifies our feature extraction in order to increase the output dimension. While this model is already able to achieve competitive results with the state of the art, we further propose a way to increase the versatility of our approach to process point clouds. To this aim, we introduce a second model that assembles our layers within a transformer architecture. We evaluate both architectures on object and indoor scene completion tasks, achieving state-of-the-art performance.
Transformers in Action: Weakly Supervised Action Segmentation
Jan 20, 2022



The video action segmentation task is regularly explored under weaker forms of supervision, such as transcript supervision, where a list of actions is easier to obtain than dense frame-wise labels. In this formulation, the task presents various challenges for sequence modeling approaches due to the emphasis on action transition points, long sequence lengths, and frame contextualization, making the task well-posed for transformers. Given developments enabling transformers to scale linearly, we demonstrate through our architecture how they can be applied to improve action alignment accuracy over the equivalent RNN-based models with the attention mechanism focusing around salient action transition regions. Additionally, given the recent focus on inference-time transcript selection, we propose a supplemental transcript embedding approach to select transcripts more quickly at inference-time. Furthermore, we subsequently demonstrate how this approach can also improve the overall segmentation performance. Finally, we evaluate our proposed methods across the benchmark datasets to better understand the applicability of transformers and the importance of transcript selection on this video-driven weakly-supervised task.
A Divide et Impera Approach for 3D Shape Reconstruction from Multiple Views
Nov 18, 2020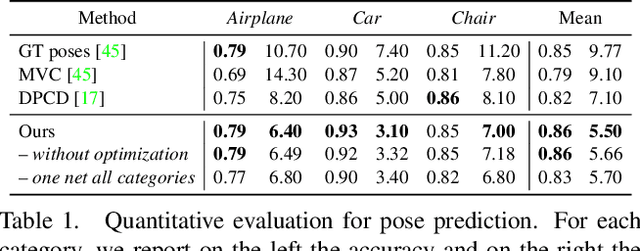
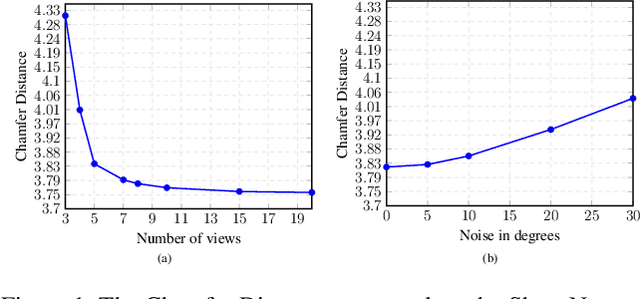
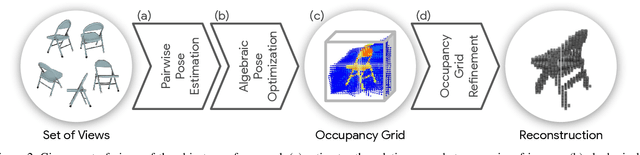

Estimating the 3D shape of an object from a single or multiple images has gained popularity thanks to the recent breakthroughs powered by deep learning. Most approaches regress the full object shape in a canonical pose, possibly extrapolating the occluded parts based on the learned priors. However, their viewpoint invariant technique often discards the unique structures visible from the input images. In contrast, this paper proposes to rely on viewpoint variant reconstructions by merging the visible information from the given views. Our approach is divided into three steps. Starting from the sparse views of the object, we first align them into a common coordinate system by estimating the relative pose between all the pairs. Then, inspired by the traditional voxel carving, we generate an occupancy grid of the object taken from the silhouette on the images and their relative poses. Finally, we refine the initial reconstruction to build a clean 3D model which preserves the details from each viewpoint. To validate the proposed method, we perform a comprehensive evaluation on the ShapeNet reference benchmark in terms of relative pose estimation and 3D shape reconstruction.
SoftPoolNet: Shape Descriptor for Point Cloud Completion and Classification
Aug 17, 2020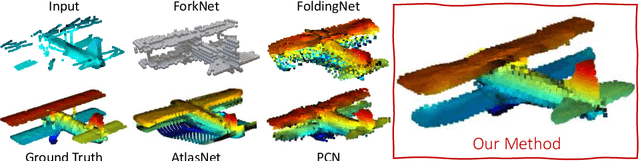
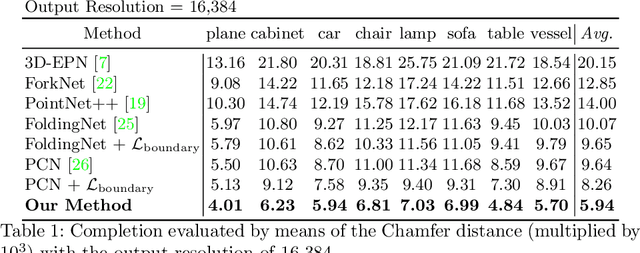
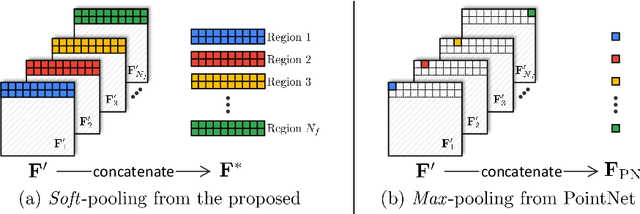

Point clouds are often the default choice for many applications as they exhibit more flexibility and efficiency than volumetric data. Nevertheless, their unorganized nature -- points are stored in an unordered way -- makes them less suited to be processed by deep learning pipelines. In this paper, we propose a method for 3D object completion and classification based on point clouds. We introduce a new way of organizing the extracted features based on their activations, which we name soft pooling. For the decoder stage, we propose regional convolutions, a novel operator aimed at maximizing the global activation entropy. Furthermore, inspired by the local refining procedure in Point Completion Network (PCN), we also propose a patch-deforming operation to simulate deconvolutional operations for point clouds. This paper proves that our regional activation can be incorporated in many point cloud architectures like AtlasNet and PCN, leading to better performance for geometric completion. We evaluate our approach on different 3D tasks such as object completion and classification, achieving state-of-the-art accuracy.