 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Pocket Pretraining via Protein Fragment-Surroundings Alignment
Oct 11, 2023



Pocket representations play a vital role in various biomedical applications, such as druggability estimation, ligand affinity prediction, and de novo drug design. While existing geometric features and pretrained representations have demonstrated promising results, they usually treat pockets independent of ligands, neglecting the fundamental interactions between them. However, the limited pocket-ligand complex structures available in the PDB database (less than 100 thousand non-redundant pairs) hampers large-scale pretraining endeavors for interaction modeling. To address this constraint, we propose a novel pocket pretraining approach that leverages knowledge from high-resolution atomic protein structures, assisted by highly effective pretrained small molecule representations. By segmenting protein structures into drug-like fragments and their corresponding pockets, we obtain a reasonable simulation of ligand-receptor interactions, resulting in the generation of over 5 million complexes. Subsequently, the pocket encoder is trained in a contrastive manner to align with the representation of pseudo-ligand furnished by some pretrained small molecule encoders. Our method, named ProFSA, achieves state-of-the-art performance across various tasks, including pocket druggability prediction, pocket matching, and ligand binding affinity prediction. Notably, ProFSA surpasses other pretraining methods by a substantial margin. Moreover, our work opens up a new avenue for mitigating the scarcity of protein-ligand complex data through the utilization of high-quality and diverse protein structure databases.
DrugCLIP: Contrastive Protein-Molecule Representation Learning for Virtual Screening
Oct 10, 2023Virtual screening, which identifies potential drugs from vast compound databases to bind with a particular protein pocket, is a critical step in AI-assisted drug discovery. Traditional docking methods are highly time-consuming, and can only work with a restricted search library in real-life applications. Recent supervised learning approaches using scoring functions for binding-affinity prediction, although promising, have not yet surpassed docking methods due to their strong dependency on limited data with reliable binding-affinity labels. In this paper, we propose a novel contrastive learning framework, DrugCLIP, by reformulating virtual screening as a dense retrieval task and employing contrastive learning to align representations of binding protein pockets and molecules from a large quantity of pairwise data without explicit binding-affinity scores. We also introduce a biological-knowledge inspired data augmentation strategy to learn better protein-molecule representations. Extensive experiments show that DrugCLIP significantly outperforms traditional docking and supervised learning methods on diverse virtual screening benchmarks with highly reduced computation time, especially in zero-shot setting.
Information Retrieval Meets Large Language Models: A Strategic Report from Chinese IR Community
Jul 27, 2023
The research field of Information Retrieval (IR) has evolved significantly, expanding beyond traditional search to meet diverse user information needs. Recently, Large Language Models (LLMs) have demonstrated exceptional capabilities in text understanding, generation, and knowledge inference, opening up exciting avenues for IR research. LLMs not only facilitate generative retrieval but also offer improved solutions for user understanding, model evaluation, and user-system interactions. More importantly, the synergistic relationship among IR models, LLMs, and humans forms a new technical paradigm that is more powerful for information seeking. IR models provide real-time and relevant information, LLMs contribute internal knowledge, and humans play a central role of demanders and evaluators to the reliability of information services. Nevertheless, significant challenges exist, including computational costs, credibility concerns, domain-specific limitations, and ethical considerations. To thoroughly discuss the transformative impact of LLMs on IR research, the Chinese IR community conducted a strategic workshop in April 2023, yielding valuable insights. This paper provides a summary of the workshop's outcomes, including the rethinking of IR's core values, the mutual enhancement of LLMs and IR, the proposal of a novel IR technical paradigm, and open challenges.
Fractional Denoising for 3D Molecular Pre-training
Jul 20, 2023



Coordinate denoising is a promising 3D molecular pre-training method, which has achieved remarkable performance in various downstream drug discovery tasks. Theoretically, the objective is equivalent to learning the force field, which is revealed helpful for downstream tasks. Nevertheless, there are two challenges for coordinate denoising to learn an effective force field, i.e. low coverage samples and isotropic force field. The underlying reason is that molecular distributions assumed by existing denoising methods fail to capture the anisotropic characteristic of molecules. To tackle these challenges, we propose a novel hybrid noise strategy, including noises on both dihedral angel and coordinate. However, denoising such hybrid noise in a traditional way is no more equivalent to learning the force field. Through theoretical deductions, we find that the problem is caused by the dependency of the input conformation for covariance. To this end, we propose to decouple the two types of noise and design a novel fractional denoising method (Frad), which only denoises the latter coordinate part. In this way, Frad enjoys both the merits of sampling more low-energy structures and the force field equivalence. Extensive experiments show the effectiveness of Frad in molecular representation, with a new state-of-the-art on 9 out of 12 tasks of QM9 and on 7 out of 8 targets of MD17.
Unified Molecular Modeling via Modality Blending
Jul 12, 2023



Self-supervised molecular representation learning is critical for molecule-based tasks such as AI-assisted drug discovery. Recent studies consider leveraging both 2D and 3D information for representation learning, with straightforward alignment strategies that treat each modality separately. In this work, we introduce a novel "blend-then-predict" self-supervised learning method (MoleBLEND), which blends atom relations from different modalities into one unified relation matrix for encoding, then recovers modality-specific information for both 2D and 3D structures. By treating atom relationships as anchors, seemingly dissimilar 2D and 3D manifolds are aligned and integrated at fine-grained relation-level organically. Extensive experiments show that MoleBLEND achieves state-of-the-art performance across major 2D/3D benchmarks. We further provide theoretical insights from the perspective of mutual-information maximization, demonstrating that our method unifies contrastive, generative (inter-modal prediction) and mask-then-predict (intra-modal prediction) objectives into a single cohesive blend-then-predict framework.
Visual Transformation Telling
May 03, 2023



In this paper, we propose a new visual reasoning task, called Visual Transformation Telling (VTT). This task requires a machine to describe the transformation that occurred between every two adjacent states (i.e. images) in a series. Unlike most existing visual reasoning tasks that focus on state reasoning, VTT emphasizes transformation reasoning. We collected 13,547 samples from two instructional video datasets, CrossTask and COIN, and extracted desired states and transformation descriptions to create a suitable VTT benchmark dataset. Humans can naturally reason from superficial states differences (e.g. ground wetness) to transformations descriptions (e.g. raining) according to their life experience but how to model this process to bridge this semantic gap is challenging. We designed TTNet on top of existing visual storytelling models by enhancing the model's state-difference sensitivity and transformation-context awareness. TTNet significantly outperforms other baseline models adapted from similar tasks, such as visual storytelling and dense video captioning, demonstrating the effectiveness of our modeling on transformations. Through comprehensive diagnostic analyses, we found TTNet has strong context utilization abilities, but even with some state-of-the-art techniques such as CLIP, there remain challenges in generalization that need to be further explored.
Visual Reasoning: from State to Transformation
May 02, 2023



Most existing visual reasoning tasks, such as CLEVR in VQA, ignore an important factor, i.e.~transformation. They are solely defined to test how well machines understand concepts and relations within static settings, like one image. Such \textbf{state driven} visual reasoning has limitations in reflecting the ability to infer the dynamics between different states, which has shown to be equally important for human cognition in Piaget's theory. To tackle this problem, we propose a novel \textbf{transformation driven} visual reasoning (TVR) task. Given both the initial and final states, the target becomes to infer the corresponding intermediate transformation. Following this definition, a new synthetic dataset namely TRANCE is first constructed on the basis of CLEVR, including three levels of settings, i.e.~Basic (single-step transformation), Event (multi-step transformation), and View (multi-step transformation with variant views). Next, we build another real dataset called TRANCO based on COIN, to cover the loss of transformation diversity on TRANCE. Inspired by human reasoning, we propose a three-staged reasoning framework called TranNet, including observing, analyzing, and concluding, to test how recent advanced techniques perform on TVR. Experimental results show that the state-of-the-art visual reasoning models perform well on Basic, but are still far from human-level intelligence on Event, View, and TRANCO. We believe the proposed new paradigm will boost the development of machine visual reasoning. More advanced methods and new problems need to be investigated in this direction. The resource of TVR is available at \url{https://hongxin2019.github.io/TVR/}.
Multi-video Moment Ranking with Multimodal Clue
Jan 29, 2023Video corpus moment retrieval~(VCMR) is the task of retrieving a relevant video moment from a large corpus of untrimmed videos via a natural language query. State-of-the-art work for VCMR is based on two-stage method. In this paper, we focus on improving two problems of two-stage method: (1) Moment prediction bias: The predicted moments for most queries come from the top retrieved videos, ignoring the possibility that the target moment is in the bottom retrieved videos, which is caused by the inconsistency of Shared Normalization during training and inference. (2) Latent key content: Different modalities of video have different key information for moment localization. To this end, we propose a two-stage model \textbf{M}ult\textbf{I}-video ra\textbf{N}king with m\textbf{U}l\textbf{T}imodal clu\textbf{E}~(MINUTE). MINUTE uses Shared Normalization during both training and inference to rank candidate moments from multiple videos to solve moment predict bias, making it more efficient to predict target moment. In addition, Mutilmdaol Clue Mining~(MCM) of MINUTE can discover key content of different modalities in video to localize moment more accurately. MINUTE outperforms the baselines on TVR and DiDeMo datasets, achieving a new state-of-the-art of VCMR. Our code will be available at GitHub.
Cross-Model Comparative Loss for Enhancing Neuronal Utility in Language Understanding
Jan 10, 2023



Current natural language understanding (NLU) models have been continuously scaling up, both in terms of model size and input context, introducing more hidden and input neurons. While this generally improves performance on average, the extra neurons do not yield a consistent improvement for all instances. This is because some hidden neurons are redundant, and the noise mixed in input neurons tends to distract the model. Previous work mainly focuses on extrinsically reducing low-utility neurons by additional post- or pre-processing, such as network pruning and context selection, to avoid this problem. Beyond that, can we make the model reduce redundant parameters and suppress input noise by intrinsically enhancing the utility of each neuron? If a model can efficiently utilize neurons, no matter which neurons are ablated (disabled), the ablated submodel should perform no better than the original full model. Based on such a comparison principle between models, we propose a cross-model comparative loss for a broad range of tasks. Comparative loss is essentially a ranking loss on top of the task-specific losses of the full and ablated models, with the expectation that the task-specific loss of the full model is minimal. We demonstrate the universal effectiveness of comparative loss through extensive experiments on 14 datasets from 3 distinct NLU tasks based on 4 widely used pretrained language models, and find it particularly superior for models with few parameters or long input.
When Does Group Invariant Learning Survive Spurious Correlations?
Jun 29, 2022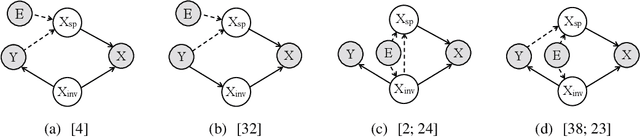
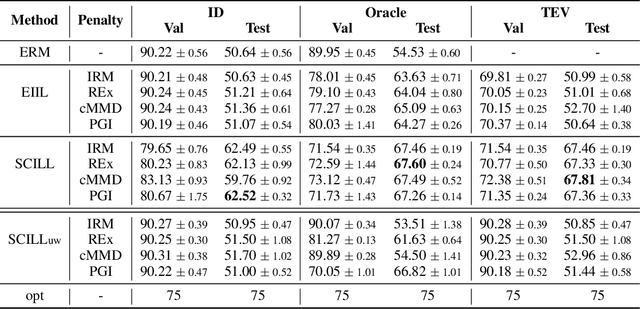
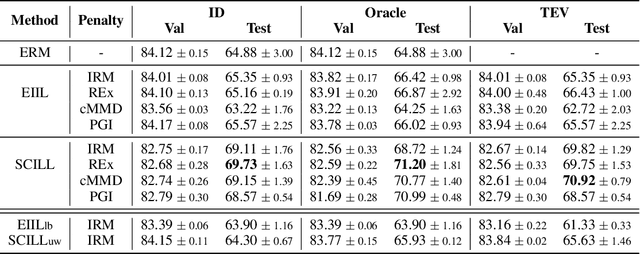
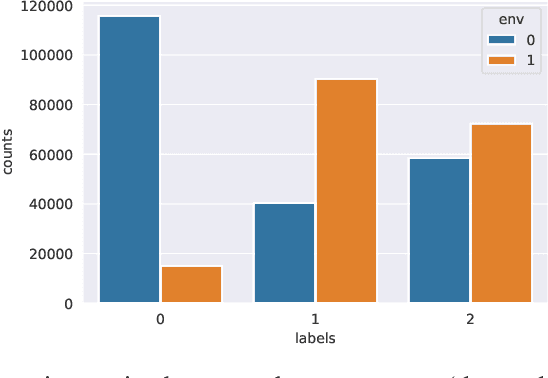
By inferring latent groups in the training data, recent works introduce invariant learning to the case where environment annotations are unavailable. Typically, learning group invariance under a majority/minority split is empirically shown to be effective in improving out-of-distribution generalization on many datasets. However, theoretical guarantee for these methods on learning invariant mechanisms is lacking. In this paper, we reveal the insufficiency of existing group invariant learning methods in preventing classifiers from depending on spurious correlations in the training set. Specifically, we propose two criteria on judging such sufficiency. Theoretically and empirically, we show that existing methods can violate both criteria and thus fail in generalizing to spurious correlation shifts. Motivated by this, we design a new group invariant learning method, which constructs groups with statistical independence tests, and reweights samples by group label proportion to meet the criteria. Experiments on both synthetic and real data demonstrate that the new method significantly outperforms existing group invariant learning methods in generalizing to spurious correlation shifts.