 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuerit-Reranker: Training Compact Multilingual Rerankers via Efficient Label-Free Distribution Adaptation
Jun 17, 2026Deployable multilingual rerankers must generalize across languages, domains, and target ranking tasks while remaining efficient enough for second-stage reranking. However, adapting them to new target distributions typically requires extensive task-specific relevance annotations, which are costly to obtain. We present Querit-Reranker, a family of multilingual cross-encoder rerankers trained with a data-centric pipeline for label-efficient adaptation. We instantiate it as Querit-Reranker-A0.4B, initialized from an in-house MoE backbone with 0.4B activated parameters, and Querit-Reranker-4B, initialized from Qwen3-Embedding-4B. Our pipeline first learns general relevance modeling from large-scale ranking-oriented data, then adapts to target distributions through synthetic-query mining with teacher scores as continuous soft labels. To consolidate complementary task-adapted strengths, we further merge checkpoints via spherical linear interpolation, obtaining a single deployable model without runtime ensembling overhead. Using Qwen3-Embedding-0.6B as the shared first-stage retriever, Querit-Reranker-A0.4B improves average nDCG@10 from 54.11 to 59.28 on BEIR and from 59.87 to 67.70 on MIRACL. On MTEB Multilingual v2 Reranking, it also substantially outperforms larger embedding-based baselines, while Querit-Reranker-4B further achieves state-of-the-art performance among publicly available models. We release both models on Hugging Face.
AdversarialCoT: Single-Document Retrieval Poisoning for LLM Reasoning
Apr 14, 2026Retrieval-augmented generation (RAG) enhances large language model (LLM) reasoning by retrieving external documents, but also opens up new attack surfaces. We study knowledge-base poisoning attacks in RAG, where an attacker injects malicious content into the retrieval corpus, which is then naturally surfaced by the retriever and consumed by the LLM during reasoning. Unlike prior work that floods the corpus with poisoned documents, we propose AdversarialCoT, a query-specific attack that poisons only a single document in the corpus. AdversarialCoT first extracts the target LLM's reasoning framework to guide the construction of an initial adversarial chain-of-thought (CoT). The adversarial document is iteratively refined through interactions with the LLM, progressively exposing and exploiting critical reasoning vulnerabilities. Experiments on benchmark LLMs show that a single adversarial document can significantly degrade reasoning accuracy, revealing subtle yet impactful weaknesses. This study exposes security risks in RAG systems and provides actionable insights for designing more robust LLM reasoning pipelines.
Thinking Forward and Backward: Multi-Objective Reinforcement Learning for Retrieval-Augmented Reasoning
Nov 13, 2025Retrieval-augmented generation (RAG) has proven to be effective in mitigating hallucinations in large language models, yet its effectiveness remains limited in complex, multi-step reasoning scenarios. Recent efforts have incorporated search-based interactions into RAG, enabling iterative reasoning with real-time retrieval. Most approaches rely on outcome-based supervision, offering no explicit guidance for intermediate steps. This often leads to reward hacking and degraded response quality. We propose Bi-RAR, a novel retrieval-augmented reasoning framework that evaluates each intermediate step jointly in both forward and backward directions. To assess the information completeness of each step, we introduce a bidirectional information distance grounded in Kolmogorov complexity, approximated via language model generation probabilities. This quantification measures both how far the current reasoning is from the answer and how well it addresses the question. To optimize reasoning under these bidirectional signals, we adopt a multi-objective reinforcement learning framework with a cascading reward structure that emphasizes early trajectory alignment. Empirical results on seven question answering benchmarks demonstrate that Bi-RAR surpasses previous methods and enables efficient interaction and reasoning with the search engine during training and inference.
C2T-ID: Converting Semantic Codebooks to Textual Document Identifiers for Generative Search
Oct 22, 2025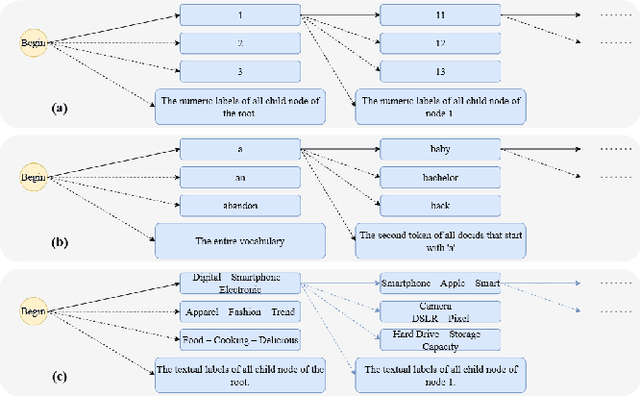
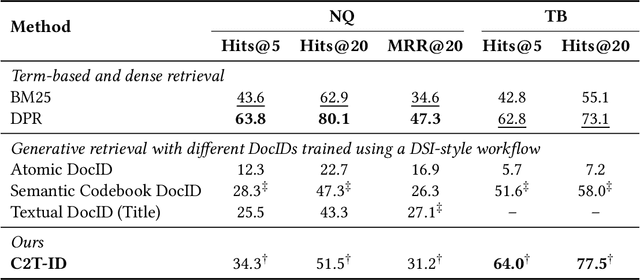
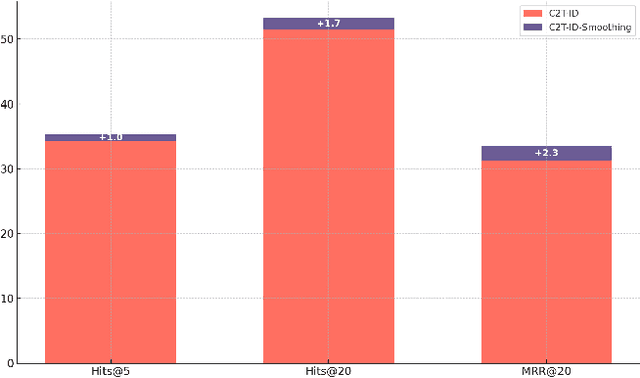
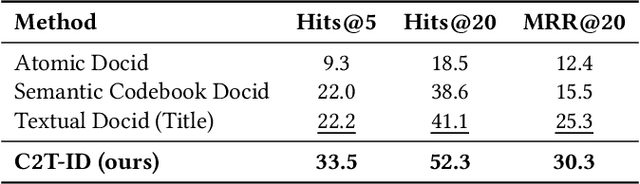
Designing document identifiers (docids) that carry rich semantic information while maintaining tractable search spaces is a important challenge in generative retrieval (GR). Popular codebook methods address this by building a hierarchical semantic tree and constraining generation to its child nodes, yet their numeric identifiers cannot leverage the large language model's pretrained natural language understanding. Conversely, using text as docid provides more semantic expressivity but inflates the decoding space, making the system brittle to early-step errors. To resolve this trade-off, we propose C2T-ID: (i) first construct semantic numerical docid via hierarchical clustering; (ii) then extract high-frequency metadata keywords and iteratively replace each numeric label with its cluster's top-K keywords; and (iii) an optional two-level semantic smoothing step further enhances the fluency of C2T-ID. Experiments on Natural Questions and Taobao's product search demonstrate that C2T-ID significantly outperforms atomic, semantic codebook, and pure-text docid baselines, demonstrating its effectiveness in balancing semantic expressiveness with search space constraints.
Does Generative Retrieval Overcome the Limitations of Dense Retrieval?
Sep 26, 2025Generative retrieval (GR) has emerged as a new paradigm in neural information retrieval, offering an alternative to dense retrieval (DR) by directly generating identifiers of relevant documents. In this paper, we theoretically and empirically investigate how GR fundamentally diverges from DR in both learning objectives and representational capacity. GR performs globally normalized maximum-likelihood optimization and encodes corpus and relevance information directly in the model parameters, whereas DR adopts locally normalized objectives and represents the corpus with external embeddings before computing similarity via a bilinear interaction. Our analysis suggests that, under scaling, GR can overcome the inherent limitations of DR, yielding two major benefits. First, with larger corpora, GR avoids the sharp performance degradation caused by the optimization drift induced by DR's local normalization. Second, with larger models, GR's representational capacity scales with parameter size, unconstrained by the global low-rank structure that limits DR. We validate these theoretical insights through controlled experiments on the Natural Questions and MS MARCO datasets, across varying negative sampling strategies, embedding dimensions, and model scales. But despite its theoretical advantages, GR does not universally outperform DR in practice. We outline directions to bridge the gap between GR's theoretical potential and practical performance, providing guidance for future research in scalable and robust generative retrieval.
On the Scaling of Robustness and Effectiveness in Dense Retrieval
May 30, 2025Robustness and Effectiveness are critical aspects of developing dense retrieval models for real-world applications. It is known that there is a trade-off between the two. Recent work has addressed scaling laws of effectiveness in dense retrieval, revealing a power-law relationship between effectiveness and the size of models and data. Does robustness follow scaling laws too? If so, can scaling improve both robustness and effectiveness together, or do they remain locked in a trade-off? To answer these questions, we conduct a comprehensive experimental study. We find that:(i) Robustness, including out-of-distribution and adversarial robustness, also follows a scaling law.(ii) Robustness and effectiveness exhibit different scaling patterns, leading to significant resource costs when jointly improving both. Given these findings, we shift to the third factor that affects model performance, namely the optimization strategy, beyond the model size and data size. We find that: (i) By fitting different optimization strategies, the joint performance of robustness and effectiveness traces out a Pareto frontier. (ii) When the optimization strategy strays from Pareto efficiency, the joint performance scales in a sub-optimal direction. (iii) By adjusting the optimization weights to fit the Pareto efficiency, we can achieve Pareto training, where the scaling of joint performance becomes most efficient. Even without requiring additional resources, Pareto training is comparable to the performance of scaling resources several times under optimization strategies that overly prioritize either robustness or effectiveness. Finally, we demonstrate that our findings can help deploy dense retrieval models in real-world applications that scale efficiently and are balanced for robustness and effectiveness.
The Silent Saboteur: Imperceptible Adversarial Attacks against Black-Box Retrieval-Augmented Generation Systems
May 24, 2025



We explore adversarial attacks against retrieval-augmented generation (RAG) systems to identify their vulnerabilities. We focus on generating human-imperceptible adversarial examples and introduce a novel imperceptible retrieve-to-generate attack against RAG. This task aims to find imperceptible perturbations that retrieve a target document, originally excluded from the initial top-$k$ candidate set, in order to influence the final answer generation. To address this task, we propose ReGENT, a reinforcement learning-based framework that tracks interactions between the attacker and the target RAG and continuously refines attack strategies based on relevance-generation-naturalness rewards. Experiments on newly constructed factual and non-factual question-answering benchmarks demonstrate that ReGENT significantly outperforms existing attack methods in misleading RAG systems with small imperceptible text perturbations.
Chain-of-Thought Poisoning Attacks against R1-based Retrieval-Augmented Generation Systems
May 22, 2025


Retrieval-augmented generation (RAG) systems can effectively mitigate the hallucination problem of large language models (LLMs),but they also possess inherent vulnerabilities. Identifying these weaknesses before the large-scale real-world deployment of RAG systems is of great importance, as it lays the foundation for building more secure and robust RAG systems in the future. Existing adversarial attack methods typically exploit knowledge base poisoning to probe the vulnerabilities of RAG systems, which can effectively deceive standard RAG models. However, with the rapid advancement of deep reasoning capabilities in modern LLMs, previous approaches that merely inject incorrect knowledge are inadequate when attacking RAG systems equipped with deep reasoning abilities. Inspired by the deep thinking capabilities of LLMs, this paper extracts reasoning process templates from R1-based RAG systems, uses these templates to wrap erroneous knowledge into adversarial documents, and injects them into the knowledge base to attack RAG systems. The key idea of our approach is that adversarial documents, by simulating the chain-of-thought patterns aligned with the model's training signals, may be misinterpreted by the model as authentic historical reasoning processes, thus increasing their likelihood of being referenced. Experiments conducted on the MS MARCO passage ranking dataset demonstrate the effectiveness of our proposed method.
An Empirical Study of Evaluating Long-form Question Answering
Apr 25, 2025\Ac{LFQA} aims to generate lengthy answers to complex questions. This scenario presents great flexibility as well as significant challenges for evaluation. Most evaluations rely on deterministic metrics that depend on string or n-gram matching, while the reliability of large language model-based evaluations for long-form answers remains relatively unexplored. We address this gap by conducting an in-depth study of long-form answer evaluation with the following research questions: (i) To what extent do existing automatic evaluation metrics serve as a substitute for human evaluations? (ii) What are the limitations of existing evaluation metrics compared to human evaluations? (iii) How can the effectiveness and robustness of existing evaluation methods be improved? We collect 5,236 factoid and non-factoid long-form answers generated by different large language models and conduct a human evaluation on 2,079 of them, focusing on correctness and informativeness. Subsequently, we investigated the performance of automatic evaluation metrics by evaluating these answers, analyzing the consistency between these metrics and human evaluations. We find that the style, length of the answers, and the category of questions can bias the automatic evaluation metrics. However, fine-grained evaluation helps mitigate this issue on some metrics. Our findings have important implications for the use of large language models for evaluating long-form question answering. All code and datasets are available at https://github.com/bugtig6351/lfqa_evaluation.
TrustRAG: An Information Assistant with Retrieval Augmented Generation
Feb 19, 2025\Ac{RAG} has emerged as a crucial technique for enhancing large models with real-time and domain-specific knowledge. While numerous improvements and open-source tools have been proposed to refine the \ac{RAG} framework for accuracy, relatively little attention has been given to improving the trustworthiness of generated results. To address this gap, we introduce TrustRAG, a novel framework that enhances \ac{RAG} from three perspectives: indexing, retrieval, and generation. Specifically, in the indexing stage, we propose a semantic-enhanced chunking strategy that incorporates hierarchical indexing to supplement each chunk with contextual information, ensuring semantic completeness. In the retrieval stage, we introduce a utility-based filtering mechanism to identify high-quality information, supporting answer generation while reducing input length. In the generation stage, we propose fine-grained citation enhancement, which detects opinion-bearing sentences in responses and infers citation relationships at the sentence-level, thereby improving citation accuracy. We open-source the TrustRAG framework and provide a demonstration studio designed for excerpt-based question answering tasks \footnote{https://huggingface.co/spaces/golaxy/TrustRAG}. Based on these, we aim to help researchers: 1) systematically enhancing the trustworthiness of \ac{RAG} systems and (2) developing their own \ac{RAG} systems with more reliable outputs.