 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Multimodal Physiological Foundation Models: Handling Arbitrary Missing Modalities
Apr 28, 2025



Multimodal physiological signals, such as EEG, ECG, EOG, and EMG, are crucial for healthcare and brain-computer interfaces. While existing methods rely on specialized architectures and dataset-specific fusion strategies, they struggle to learn universal representations that generalize across datasets and handle missing modalities at inference time. To address these issues, we propose PhysioOmni, a foundation model for multimodal physiological signal analysis that models both homogeneous and heterogeneous features to decouple multimodal signals and extract generic representations while maintaining compatibility with arbitrary missing modalities. PhysioOmni trains a decoupled multimodal tokenizer, enabling masked signal pre-training via modality-invariant and modality-specific objectives. To ensure adaptability to diverse and incomplete modality combinations, the pre-trained encoders undergo resilient fine-tuning with prototype alignment on downstream datasets. Extensive experiments on four downstream tasks, emotion recognition, sleep stage classification, motor prediction, and mental workload detection, demonstrate that PhysioOmni achieves state-of-the-art performance while maintaining strong robustness to missing modalities. Our code and model weights will be released.
Multi-modal Self-supervised Pre-training for Regulatory Genome Across Cell Types
Nov 03, 2021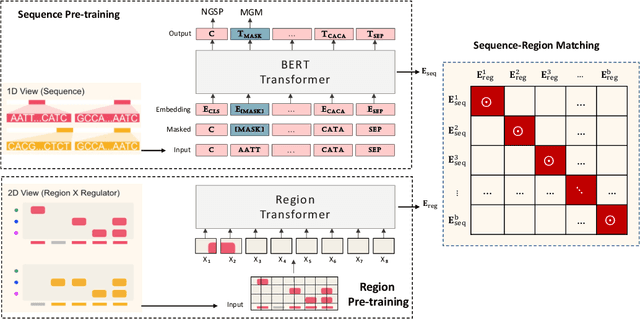

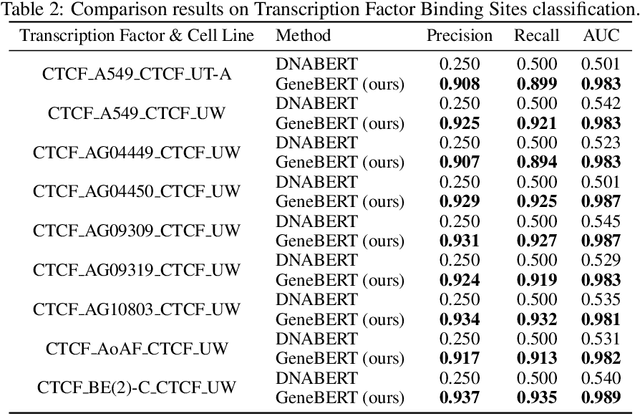
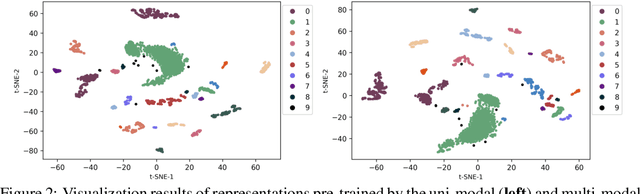
In the genome biology research, regulatory genome modeling is an important topic for many regulatory downstream tasks, such as promoter classification, transaction factor binding sites prediction. The core problem is to model how regulatory elements interact with each other and its variability across different cell types. However, current deep learning methods often focus on modeling genome sequences of a fixed set of cell types and do not account for the interaction between multiple regulatory elements, making them only perform well on the cell types in the training set and lack the generalizability required in biological applications. In this work, we propose a simple yet effective approach for pre-training genome data in a multi-modal and self-supervised manner, which we call GeneBERT. Specifically, we simultaneously take the 1d sequence of genome data and a 2d matrix of (transcription factors x regions) as the input, where three pre-training tasks are proposed to improve the robustness and generalizability of our model. We pre-train our model on the ATAC-seq dataset with 17 million genome sequences. We evaluate our GeneBERT on regulatory downstream tasks across different cell types, including promoter classification, transaction factor binding sites prediction, disease risk estimation, and splicing sites prediction. Extensive experiments demonstrate the effectiveness of multi-modal and self-supervised pre-training for large-scale regulatory genomics data.