 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Reliable and Interpretable Traffic Crash Pattern Prediction and Safety Interventions Using Customized Large Language Models
May 18, 2025Predicting crash events is crucial for understanding crash distributions and their contributing factors, thereby enabling the design of proactive traffic safety policy interventions. However, existing methods struggle to interpret the complex interplay among various sources of traffic crash data, including numeric characteristics, textual reports, crash imagery, environmental conditions, and driver behavior records. As a result, they often fail to capture the rich semantic information and intricate interrelationships embedded in these diverse data sources, limiting their ability to identify critical crash risk factors. In this research, we propose TrafficSafe, a framework that adapts LLMs to reframe crash prediction and feature attribution as text-based reasoning. A multi-modal crash dataset including 58,903 real-world reports together with belonged infrastructure, environmental, driver, and vehicle information is collected and textualized into TrafficSafe Event Dataset. By customizing and fine-tuning LLMs on this dataset, the TrafficSafe LLM achieves a 42% average improvement in F1-score over baselines. To interpret these predictions and uncover contributing factors, we introduce TrafficSafe Attribution, a sentence-level feature attribution framework enabling conditional risk analysis. Findings show that alcohol-impaired driving is the leading factor in severe crashes, with aggressive and impairment-related behaviors having nearly twice the contribution for severe crashes compared to other driver behaviors. Furthermore, TrafficSafe Attribution highlights pivotal features during model training, guiding strategic crash data collection for iterative performance improvements. The proposed TrafficSafe offers a transformative leap in traffic safety research, providing a blueprint for translating advanced AI technologies into responsible, actionable, and life-saving outcomes.
MediAug: Exploring Visual Augmentation in Medical Imaging
Apr 26, 2025Data augmentation is essential in medical imaging for improving classification accuracy, lesion detection, and organ segmentation under limited data conditions. However, two significant challenges remain. First, a pronounced domain gap between natural photographs and medical images can distort critical disease features. Second, augmentation studies in medical imaging are fragmented and limited to single tasks or architectures, leaving the benefits of advanced mix-based strategies unclear. To address these challenges, we propose a unified evaluation framework with six mix-based augmentation methods integrated with both convolutional and transformer backbones on brain tumour MRI and eye disease fundus datasets. Our contributions are threefold. (1) We introduce MediAug, a comprehensive and reproducible benchmark for advanced data augmentation in medical imaging. (2) We systematically evaluate MixUp, YOCO, CropMix, CutMix, AugMix, and SnapMix with ResNet-50 and ViT-B backbones. (3) We demonstrate through extensive experiments that MixUp yields the greatest improvement on the brain tumor classification task for ResNet-50 with 79.19% accuracy and SnapMix yields the greatest improvement for ViT-B with 99.44% accuracy, and that YOCO yields the greatest improvement on the eye disease classification task for ResNet-50 with 91.60% accuracy and CutMix yields the greatest improvement for ViT-B with 97.94% accuracy. Code will be available at https://github.com/AIGeeksGroup/MediAug.
Bias Analysis and Mitigation through Protected Attribute Detection and Regard Classification
Apr 19, 2025



Large language models (LLMs) acquire general linguistic knowledge from massive-scale pretraining. However, pretraining data mainly comprised of web-crawled texts contain undesirable social biases which can be perpetuated or even amplified by LLMs. In this study, we propose an efficient yet effective annotation pipeline to investigate social biases in the pretraining corpora. Our pipeline consists of protected attribute detection to identify diverse demographics, followed by regard classification to analyze the language polarity towards each attribute. Through our experiments, we demonstrate the effect of our bias analysis and mitigation measures, focusing on Common Crawl as the most representative pretraining corpus.
SEGA: Drivable 3D Gaussian Head Avatar from a Single Image
Apr 19, 2025Creating photorealistic 3D head avatars from limited input has become increasingly important for applications in virtual reality, telepresence, and digital entertainment. While recent advances like neural rendering and 3D Gaussian splatting have enabled high-quality digital human avatar creation and animation, most methods rely on multiple images or multi-view inputs, limiting their practicality for real-world use. In this paper, we propose SEGA, a novel approach for Single-imagE-based 3D drivable Gaussian head Avatar creation that combines generalized prior models with a new hierarchical UV-space Gaussian Splatting framework. SEGA seamlessly combines priors derived from large-scale 2D datasets with 3D priors learned from multi-view, multi-expression, and multi-ID data, achieving robust generalization to unseen identities while ensuring 3D consistency across novel viewpoints and expressions. We further present a hierarchical UV-space Gaussian Splatting framework that leverages FLAME-based structural priors and employs a dual-branch architecture to disentangle dynamic and static facial components effectively. The dynamic branch encodes expression-driven fine details, while the static branch focuses on expression-invariant regions, enabling efficient parameter inference and precomputation. This design maximizes the utility of limited 3D data and achieves real-time performance for animation and rendering. Additionally, SEGA performs person-specific fine-tuning to further enhance the fidelity and realism of the generated avatars. Experiments show our method outperforms state-of-the-art approaches in generalization ability, identity preservation, and expression realism, advancing one-shot avatar creation for practical applications.
Information Gain-Guided Causal Intervention for Autonomous Debiasing Large Language Models
Apr 17, 2025Despite significant progress, recent studies indicate that current large language models (LLMs) may still capture dataset biases and utilize them during inference, leading to the poor generalizability of LLMs. However, due to the diversity of dataset biases and the insufficient nature of bias suppression based on in-context learning, the effectiveness of previous prior knowledge-based debiasing methods and in-context learning based automatic debiasing methods is limited. To address these challenges, we explore the combination of causal mechanisms with information theory and propose an information gain-guided causal intervention debiasing (IGCIDB) framework. This framework first utilizes an information gain-guided causal intervention method to automatically and autonomously balance the distribution of instruction-tuning dataset. Subsequently, it employs a standard supervised fine-tuning process to train LLMs on the debiased dataset. Experimental results show that IGCIDB can effectively debias LLM to improve its generalizability across different tasks.
Seaweed-7B: Cost-Effective Training of Video Generation Foundation Model
Apr 11, 2025



This technical report presents a cost-efficient strategy for training a video generation foundation model. We present a mid-sized research model with approximately 7 billion parameters (7B) called Seaweed-7B trained from scratch using 665,000 H100 GPU hours. Despite being trained with moderate computational resources, Seaweed-7B demonstrates highly competitive performance compared to contemporary video generation models of much larger size. Design choices are especially crucial in a resource-constrained setting. This technical report highlights the key design decisions that enhance the performance of the medium-sized diffusion model. Empirically, we make two observations: (1) Seaweed-7B achieves performance comparable to, or even surpasses, larger models trained on substantially greater GPU resources, and (2) our model, which exhibits strong generalization ability, can be effectively adapted across a wide range of downstream applications either by lightweight fine-tuning or continue training. See the project page at https://seaweed.video/
MLKV: Efficiently Scaling up Large Embedding Model Training with Disk-based Key-Value Storage
Apr 02, 2025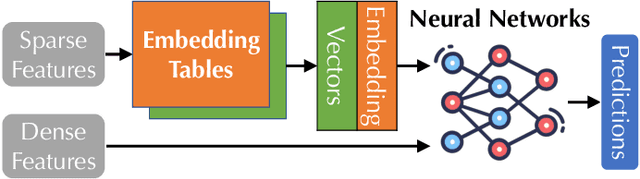
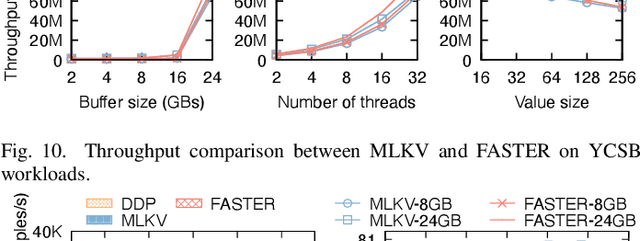
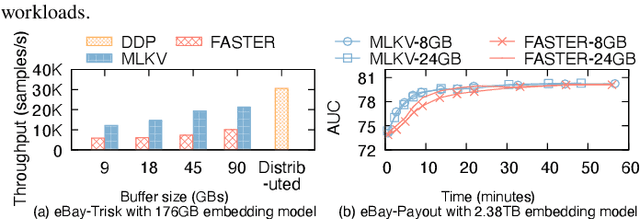
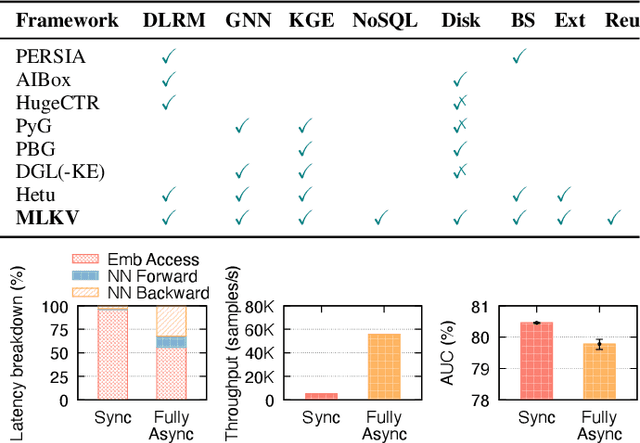
Many modern machine learning (ML) methods rely on embedding models to learn vector representations (embeddings) for a set of entities (embedding tables). As increasingly diverse ML applications utilize embedding models and embedding tables continue to grow in size and number, there has been a surge in the ad-hoc development of specialized frameworks targeted to train large embedding models for specific tasks. Although the scalability issues that arise in different embedding model training tasks are similar, each of these frameworks independently reinvents and customizes storage components for specific tasks, leading to substantial duplicated engineering efforts in both development and deployment. This paper presents MLKV, an efficient, extensible, and reusable data storage framework designed to address the scalability challenges in embedding model training, specifically data stall and staleness. MLKV augments disk-based key-value storage by democratizing optimizations that were previously exclusive to individual specialized frameworks and provides easy-to-use interfaces for embedding model training tasks. Extensive experiments on open-source workloads, as well as applications in eBay's payment transaction risk detection and seller payment risk detection, show that MLKV outperforms offloading strategies built on top of industrial-strength key-value stores by 1.6-12.6x. MLKV is open-source at https://github.com/llm-db/MLKV.
TransDiffSBDD: Causality-Aware Multi-Modal Structure-Based Drug Design
Mar 26, 2025Structure-based drug design (SBDD) is a critical task in drug discovery, requiring the generation of molecular information across two distinct modalities: discrete molecular graphs and continuous 3D coordinates. However, existing SBDD methods often overlook two key challenges: (1) the multi-modal nature of this task and (2) the causal relationship between these modalities, limiting their plausibility and performance. To address both challenges, we propose TransDiffSBDD, an integrated framework combining autoregressive transformers and diffusion models for SBDD. Specifically, the autoregressive transformer models discrete molecular information, while the diffusion model samples continuous distributions, effectively resolving the first challenge. To address the second challenge, we design a hybrid-modal sequence for protein-ligand complexes that explicitly respects the causality between modalities. Experiments on the CrossDocked2020 benchmark demonstrate that TransDiffSBDD outperforms existing baselines.
MExD: An Expert-Infused Diffusion Model for Whole-Slide Image Classification
Mar 16, 2025



Whole Slide Image (WSI) classification poses unique challenges due to the vast image size and numerous non-informative regions, which introduce noise and cause data imbalance during feature aggregation. To address these issues, we propose MExD, an Expert-Infused Diffusion Model that combines the strengths of a Mixture-of-Experts (MoE) mechanism with a diffusion model for enhanced classification. MExD balances patch feature distribution through a novel MoE-based aggregator that selectively emphasizes relevant information, effectively filtering noise, addressing data imbalance, and extracting essential features. These features are then integrated via a diffusion-based generative process to directly yield the class distribution for the WSI. Moving beyond conventional discriminative approaches, MExD represents the first generative strategy in WSI classification, capturing fine-grained details for robust and precise results. Our MExD is validated on three widely-used benchmarks-Camelyon16, TCGA-NSCLC, and BRACS consistently achieving state-of-the-art performance in both binary and multi-class tasks.
MVD-HuGaS: Human Gaussians from a Single Image via 3D Human Multi-view Diffusion Prior
Mar 11, 2025



3D human reconstruction from a single image is a challenging problem and has been exclusively studied in the literature. Recently, some methods have resorted to diffusion models for guidance, optimizing a 3D representation via Score Distillation Sampling(SDS) or generating one back-view image for facilitating reconstruction. However, these methods tend to produce unsatisfactory artifacts (\textit{e.g.} flattened human structure or over-smoothing results caused by inconsistent priors from multiple views) and struggle with real-world generalization in the wild. In this work, we present \emph{MVD-HuGaS}, enabling free-view 3D human rendering from a single image via a multi-view human diffusion model. We first generate multi-view images from the single reference image with an enhanced multi-view diffusion model, which is well fine-tuned on high-quality 3D human datasets to incorporate 3D geometry priors and human structure priors. To infer accurate camera poses from the sparse generated multi-view images for reconstruction, an alignment module is introduced to facilitate joint optimization of 3D Gaussians and camera poses. Furthermore, we propose a depth-based Facial Distortion Mitigation module to refine the generated facial regions, thereby improving the overall fidelity of the reconstruction.Finally, leveraging the refined multi-view images, along with their accurate camera poses, MVD-HuGaS optimizes the 3D Gaussians of the target human for high-fidelity free-view renderings. Extensive experiments on Thuman2.0 and 2K2K datasets show that the proposed MVD-HuGaS achieves state-of-the-art performance on single-view 3D human rendering.