 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMExD: An Expert-Infused Diffusion Model for Whole-Slide Image Classification
Mar 16, 2025



Whole Slide Image (WSI) classification poses unique challenges due to the vast image size and numerous non-informative regions, which introduce noise and cause data imbalance during feature aggregation. To address these issues, we propose MExD, an Expert-Infused Diffusion Model that combines the strengths of a Mixture-of-Experts (MoE) mechanism with a diffusion model for enhanced classification. MExD balances patch feature distribution through a novel MoE-based aggregator that selectively emphasizes relevant information, effectively filtering noise, addressing data imbalance, and extracting essential features. These features are then integrated via a diffusion-based generative process to directly yield the class distribution for the WSI. Moving beyond conventional discriminative approaches, MExD represents the first generative strategy in WSI classification, capturing fine-grained details for robust and precise results. Our MExD is validated on three widely-used benchmarks-Camelyon16, TCGA-NSCLC, and BRACS consistently achieving state-of-the-art performance in both binary and multi-class tasks.
FocusDiffuser: Perceiving Local Disparities for Camouflaged Object Detection
Jul 18, 2024



Detecting objects seamlessly blended into their surroundings represents a complex task for both human cognitive capabilities and advanced artificial intelligence algorithms. Currently, the majority of methodologies for detecting camouflaged objects mainly focus on utilizing discriminative models with various unique designs. However, it has been observed that generative models, such as Stable Diffusion, possess stronger capabilities for understanding various objects in complex environments; Yet their potential for the cognition and detection of camouflaged objects has not been extensively explored. In this study, we present a novel denoising diffusion model, namely FocusDiffuser, to investigate how generative models can enhance the detection and interpretation of camouflaged objects. We believe that the secret to spotting camouflaged objects lies in catching the subtle nuances in details. Consequently, our FocusDiffuser innovatively integrates specialized enhancements, notably the Boundary-Driven LookUp (BDLU) module and Cyclic Positioning (CP) module, to elevate standard diffusion models, significantly boosting the detail-oriented analytical capabilities. Our experiments demonstrate that FocusDiffuser, from a generative perspective, effectively addresses the challenge of camouflaged object detection, surpassing leading models on benchmarks like CAMO, COD10K and NC4K.
Integrated Sensing and Communications in Clutter Environment
Nov 03, 2023



In this paper, we propose a practical integrated sensing and communications (ISAC) framework to sense dynamic targets from clutter environment while ensuring users communications quality. To implement communications function and sensing function simultaneously, we design multiple communications beams that can communicate with the users as well as one sensing beam that can rotate and scan the entire space. To minimize the interference of sensing beam on existing communications systems, we divide the service area into sensing beam for sensing (S4S) sector and communications beam for sensing (C4S) sector, and provide beamforming design and power allocation optimization strategies for each type sector. Unlike most existing ISAC studies that ignore the interference of static environmental clutter on target sensing, we construct a mixed sensing channel model that includes both static environment and dynamic targets. When base station receives the echo signals, the mean phasor cancellation (MPC) method is employed to filter out the interference from static environmental clutter and to extract the effective dynamic target echoes. Then a complete and practical dynamic target sensing scheme is designed to detect the presence of dynamic targets and to estimate their angles, distances, and velocities. In particular, dynamic target detection and angle estimation are realized through angle-Doppler spectrum estimation (ADSE) and joint detection over multiple subcarriers (MSJD), while distance and velocity estimation are realized through the extended subspace algorithm. Simulation results demonstrate the effectiveness of the proposed scheme and its superiority over the existing methods that ignore environmental clutter.
Mutual Generative Transformer Learning for Cross-view Geo-localization
Mar 17, 2022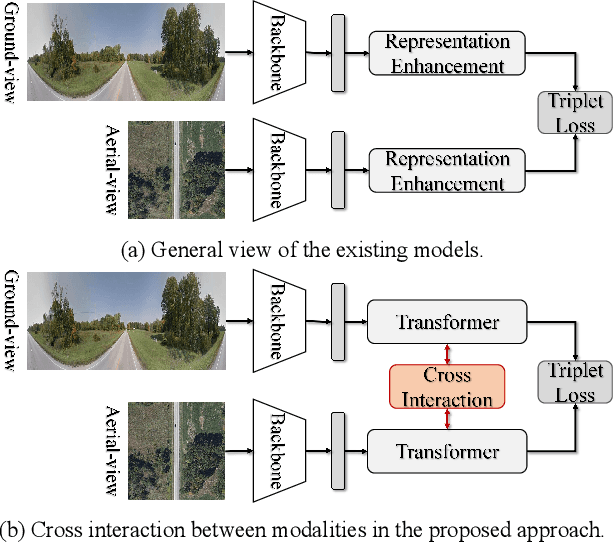
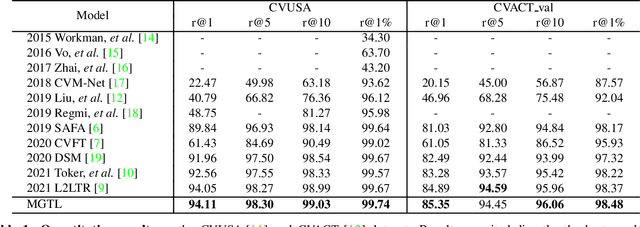
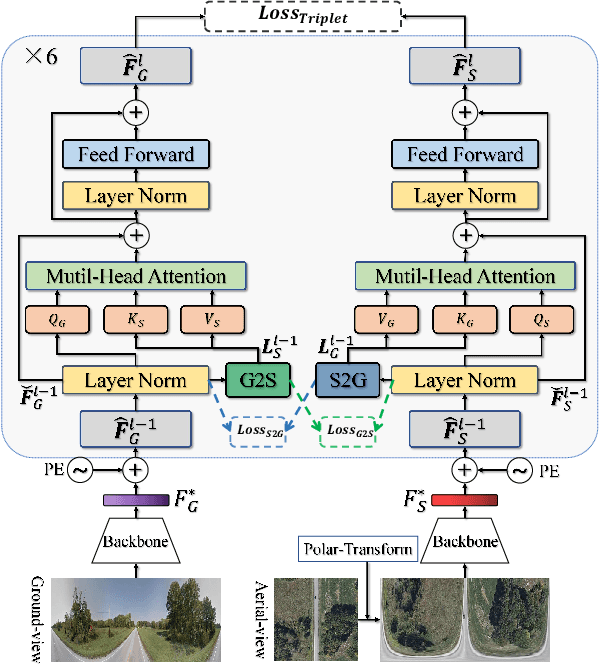

Cross-view geo-localization (CVGL), which aims to estimate the geographical location of the ground-level camera by matching against enormous geo-tagged aerial (e.g., satellite) images, remains extremely challenging due to the drastic appearance differences across views. Existing methods mainly employ Siamese-like CNNs to extract global descriptors without examining the mutual benefits between the two modes. In this paper, we present a novel approach using cross-modal knowledge generative tactics in combination with transformer, namely mutual generative transformer learning (MGTL), for CVGL. Specifically, MGTL develops two separate generative modules--one for aerial-like knowledge generation from ground-level semantic information and vice versa--and fully exploits their mutual benefits through the attention mechanism. Experiments on challenging public benchmarks, CVACT and CVUSA, demonstrate the effectiveness of the proposed method compared to the existing state-of-the-art models.