 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Reliable and Interpretable Traffic Crash Pattern Prediction and Safety Interventions Using Customized Large Language Models
May 18, 2025Predicting crash events is crucial for understanding crash distributions and their contributing factors, thereby enabling the design of proactive traffic safety policy interventions. However, existing methods struggle to interpret the complex interplay among various sources of traffic crash data, including numeric characteristics, textual reports, crash imagery, environmental conditions, and driver behavior records. As a result, they often fail to capture the rich semantic information and intricate interrelationships embedded in these diverse data sources, limiting their ability to identify critical crash risk factors. In this research, we propose TrafficSafe, a framework that adapts LLMs to reframe crash prediction and feature attribution as text-based reasoning. A multi-modal crash dataset including 58,903 real-world reports together with belonged infrastructure, environmental, driver, and vehicle information is collected and textualized into TrafficSafe Event Dataset. By customizing and fine-tuning LLMs on this dataset, the TrafficSafe LLM achieves a 42% average improvement in F1-score over baselines. To interpret these predictions and uncover contributing factors, we introduce TrafficSafe Attribution, a sentence-level feature attribution framework enabling conditional risk analysis. Findings show that alcohol-impaired driving is the leading factor in severe crashes, with aggressive and impairment-related behaviors having nearly twice the contribution for severe crashes compared to other driver behaviors. Furthermore, TrafficSafe Attribution highlights pivotal features during model training, guiding strategic crash data collection for iterative performance improvements. The proposed TrafficSafe offers a transformative leap in traffic safety research, providing a blueprint for translating advanced AI technologies into responsible, actionable, and life-saving outcomes.
Exploring Code Language Models for Automated HLS-based Hardware Generation: Benchmark, Infrastructure and Analysis
Feb 19, 2025Recent advances in code generation have illuminated the potential of employing large language models (LLMs) for general-purpose programming languages such as Python and C++, opening new opportunities for automating software development and enhancing programmer productivity. The potential of LLMs in software programming has sparked significant interest in exploring automated hardware generation and automation. Although preliminary endeavors have been made to adopt LLMs in generating hardware description languages (HDLs), several challenges persist in this direction. First, the volume of available HDL training data is substantially smaller compared to that for software programming languages. Second, the pre-trained LLMs, mainly tailored for software code, tend to produce HDL designs that are more error-prone. Third, the generation of HDL requires a significantly higher number of tokens compared to software programming, leading to inefficiencies in cost and energy consumption. To tackle these challenges, this paper explores leveraging LLMs to generate High-Level Synthesis (HLS)-based hardware design. Although code generation for domain-specific programming languages is not new in the literature, we aim to provide experimental results, insights, benchmarks, and evaluation infrastructure to investigate the suitability of HLS over low-level HDLs for LLM-assisted hardware design generation. To achieve this, we first finetune pre-trained models for HLS-based hardware generation, using a collected dataset with text prompts and corresponding reference HLS designs. An LLM-assisted framework is then proposed to automate end-to-end hardware code generation, which also investigates the impact of chain-of-thought and feedback loops promoting techniques on HLS-design generation. Limited by the timeframe of this research, we plan to evaluate more advanced reasoning models in the future.
Ultra Memory-Efficient On-FPGA Training of Transformers via Tensor-Compressed Optimization
Jan 11, 2025Transformer models have achieved state-of-the-art performance across a wide range of machine learning tasks. There is growing interest in training transformers on resource-constrained edge devices due to considerations such as privacy, domain adaptation, and on-device scientific machine learning. However, the significant computational and memory demands required for transformer training often exceed the capabilities of an edge device. Leveraging low-rank tensor compression, this paper presents the first on-FPGA accelerator for end-to-end transformer training. On the algorithm side, we present a bi-directional contraction flow for tensorized transformer training, significantly reducing the computational FLOPS and intra-layer memory costs compared to existing tensor operations. On the hardware side, we store all highly compressed model parameters and gradient information on chip, creating an on-chip-memory-only framework for each stage in training. This reduces off-chip communication and minimizes latency and energy costs. Additionally, we implement custom computing kernels for each training stage and employ intra-layer parallelism and pipe-lining to further enhance run-time and memory efficiency. Through experiments on transformer models within $36.7$ to $93.5$ MB using FP-32 data formats on the ATIS dataset, our tensorized FPGA accelerator could conduct single-batch end-to-end training on the AMD Alevo U50 FPGA, with a memory budget of less than $6$-MB BRAM and $22.5$-MB URAM. Compared to uncompressed training on the NVIDIA RTX 3090 GPU, our on-FPGA training achieves a memory reduction of $30\times$ to $51\times$. Our FPGA accelerator also achieves up to $3.6\times$ less energy cost per epoch compared with tensor Transformer training on an NVIDIA RTX 3090 GPU.
Understanding the Performance and Estimating the Cost of LLM Fine-Tuning
Aug 08, 2024



Due to the cost-prohibitive nature of training Large Language Models (LLMs), fine-tuning has emerged as an attractive alternative for specializing LLMs for specific tasks using limited compute resources in a cost-effective manner. In this paper, we characterize sparse Mixture of Experts (MoE) based LLM fine-tuning to understand their accuracy and runtime performance on a single GPU. Our evaluation provides unique insights into the training efficacy of sparse and dense versions of MoE models, as well as their runtime characteristics, including maximum batch size, execution time breakdown, end-to-end throughput, GPU hardware utilization, and load distribution. Our study identifies the optimization of the MoE layer as crucial for further improving the performance of LLM fine-tuning. Using our profiling results, we also develop and validate an analytical model to estimate the cost of LLM fine-tuning on the cloud. This model, based on parameters of the model and GPU architecture, estimates LLM throughput and the cost of training, aiding practitioners in industry and academia to budget the cost of fine-tuning a specific model.
MetaFollower: Adaptable Personalized Autonomous Car Following
Jun 23, 2024



Car-following (CF) modeling, a fundamental component in microscopic traffic simulation, has attracted increasing interest of researchers in the past decades. In this study, we propose an adaptable personalized car-following framework -MetaFollower, by leveraging the power of meta-learning. Specifically, we first utilize Model-Agnostic Meta-Learning (MAML) to extract common driving knowledge from various CF events. Afterward, the pre-trained model can be fine-tuned on new drivers with only a few CF trajectories to achieve personalized CF adaptation. We additionally combine Long Short-Term Memory (LSTM) and Intelligent Driver Model (IDM) to reflect temporal heterogeneity with high interpretability. Unlike conventional adaptive cruise control (ACC) systems that rely on predefined settings and constant parameters without considering heterogeneous driving characteristics, MetaFollower can accurately capture and simulate the intricate dynamics of car-following behavior while considering the unique driving styles of individual drivers. We demonstrate the versatility and adaptability of MetaFollower by showcasing its ability to adapt to new drivers with limited training data quickly. To evaluate the performance of MetaFollower, we conduct rigorous experiments comparing it with both data-driven and physics-based models. The results reveal that our proposed framework outperforms baseline models in predicting car-following behavior with higher accuracy and safety. To the best of our knowledge, this is the first car-following model aiming to achieve fast adaptation by considering both driver and temporal heterogeneity based on meta-learning.
Hardware-Aware Parallel Prompt Decoding for Memory-Efficient Acceleration of LLM Inference
May 28, 2024



The auto-regressive decoding of Large Language Models (LLMs) results in significant overheads in their hardware performance. While recent research has investigated various speculative decoding techniques for multi-token generation, these efforts have primarily focused on improving processing speed such as throughput. Crucially, they often neglect other metrics essential for real-life deployments, such as memory consumption and training cost. To overcome these limitations, we propose a novel parallel prompt decoding that requires only $0.0002$% trainable parameters, enabling efficient training on a single A100-40GB GPU in just 16 hours. Inspired by the human natural language generation process, $PPD$ approximates outputs generated at future timesteps in parallel by using multiple prompt tokens. This approach partially recovers the missing conditional dependency information necessary for multi-token generation, resulting in up to a 28% higher acceptance rate for long-range predictions. Furthermore, we present a hardware-aware dynamic sparse tree technique that adaptively optimizes this decoding scheme to fully leverage the computational capacities on different GPUs. Through extensive experiments across LLMs ranging from MobileLlama to Vicuna-13B on a wide range of benchmarks, our approach demonstrates up to 2.49$\times$ speedup and maintains a minimal runtime memory overhead of just $0.0004$%. More importantly, our parallel prompt decoding can serve as an orthogonal optimization for synergistic integration with existing speculative decoding, showing up to $1.22\times$ further speed improvement. Our code is available at https://github.com/hmarkc/parallel-prompt-decoding.
Explainable Traffic Flow Prediction with Large Language Models
Apr 13, 2024



Traffic flow prediction is crucial for intelligent transportation systems. It has experienced significant advancements thanks to the power of deep learning in capturing latent patterns of traffic data. However, recent deep-learning architectures require intricate model designs and lack an intuitive understanding of the mapping from input data to predicted results. Achieving both accuracy and interpretability in traffic prediction models remains to be a challenge due to the complexity of traffic data and the inherent opacity of deep learning models. To tackle these challenges, we propose a novel approach, Traffic Flow Prediction LLM (TF-LLM), which leverages large language models (LLMs) to generate interpretable traffic flow predictions. By transferring multi-modal traffic data into natural language descriptions, TF-LLM captures complex spatial-temporal patterns and external factors from comprehensive traffic data. The LLM framework is fine-tuned using language-based instructions to align with spatial-temporal traffic flow data. Empirically, TF-LLM shows competitive accuracy compared with deep learning baselines, while providing intuitive and interpretable predictions. We discuss the spatial-temporal and input dependencies for explainable future flow forecasting, showcasing TF-LLM's potential for diverse city prediction tasks. This paper contributes to advancing explainable traffic prediction models and lays a foundation for future exploration of LLM applications in transportation. To the best of our knowledge, this is the first study to use LLM for interpretable prediction of traffic flow.
LC-LLM: Explainable Lane-Change Intention and Trajectory Predictions with Large Language Models
Mar 27, 2024



To ensure safe driving in dynamic environments, autonomous vehicles should possess the capability to accurately predict the lane change intentions of surrounding vehicles in advance and forecast their future trajectories. Existing motion prediction approaches have ample room for improvement, particularly in terms of long-term prediction accuracy and interpretability. In this paper, we address these challenges by proposing LC-LLM, an explainable lane change prediction model that leverages the strong reasoning capabilities and self-explanation abilities of Large Language Models (LLMs). Essentially, we reformulate the lane change prediction task as a language modeling problem, processing heterogeneous driving scenario information in natural language as prompts for input into the LLM and employing a supervised fine-tuning technique to tailor the LLM specifically for our lane change prediction task. This allows us to utilize the LLM's powerful common sense reasoning abilities to understand complex interactive information, thereby improving the accuracy of long-term predictions. Furthermore, we incorporate explanatory requirements into the prompts in the inference stage. Therefore, our LC-LLM model not only can predict lane change intentions and trajectories but also provides explanations for its predictions, enhancing the interpretability. Extensive experiments on the large-scale highD dataset demonstrate the superior performance and interpretability of our LC-LLM in lane change prediction task. To the best of our knowledge, this is the first attempt to utilize LLMs for predicting lane change behavior. Our study shows that LLMs can encode comprehensive interaction information for driving behavior understanding.
TransFollower: Long-Sequence Car-Following Trajectory Prediction through Transformer
Feb 04, 2022Car-following refers to a control process in which the following vehicle (FV) tries to keep a safe distance between itself and the lead vehicle (LV) by adjusting its acceleration in response to the actions of the vehicle ahead. The corresponding car-following models, which describe how one vehicle follows another vehicle in the traffic flow, form the cornerstone for microscopic traffic simulation and intelligent vehicle development. One major motivation of car-following models is to replicate human drivers' longitudinal driving trajectories. To model the long-term dependency of future actions on historical driving situations, we developed a long-sequence car-following trajectory prediction model based on the attention-based Transformer model. The model follows a general format of encoder-decoder architecture. The encoder takes historical speed and spacing data as inputs and forms a mixed representation of historical driving context using multi-head self-attention. The decoder takes the future LV speed profile as input and outputs the predicted future FV speed profile in a generative way (instead of an auto-regressive way, avoiding compounding errors). Through cross-attention between encoder and decoder, the decoder learns to build a connection between historical driving and future LV speed, based on which a prediction of future FV speed can be obtained. We train and test our model with 112,597 real-world car-following events extracted from the Shanghai Naturalistic Driving Study (SH-NDS). Results show that the model outperforms the traditional intelligent driver model (IDM), a fully connected neural network model, and a long short-term memory (LSTM) based model in terms of long-sequence trajectory prediction accuracy. We also visualized the self-attention and cross-attention heatmaps to explain how the model derives its predictions.
Personalized Context-Aware Multi-Modal Transportation Recommendation
Oct 13, 2019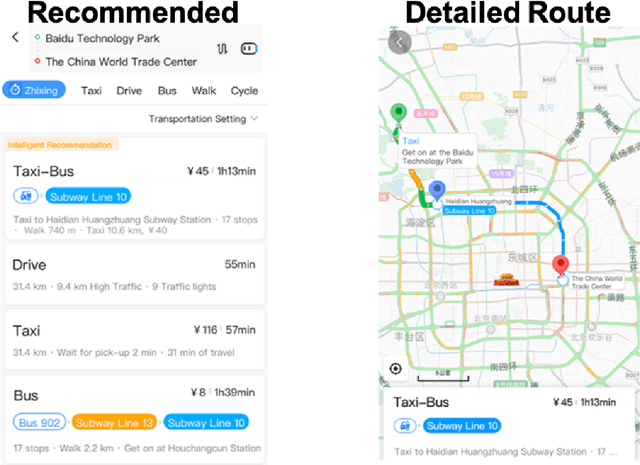

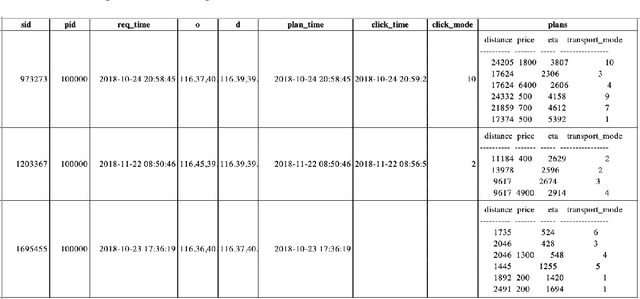
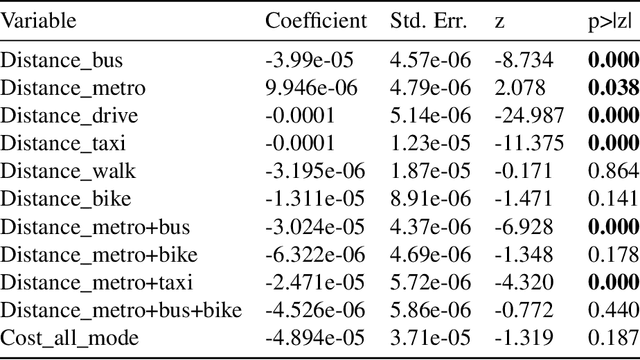
This study proposes to find the most appropriate transport modes with awareness of user preferences (e.g., costs, times) and trip characteristics (e.g., purpose, distance). The work was based on real-life trips obtained from a map application. Several methods including gradient boosting tree, learning to rank, multinomial logit model, automated machine learning, random forest, and shallow neural network have been tried. For some methods, feature selection and over-sampling techniques were also tried. The results show that the best performing method is a gradient boosting tree model with synthetic minority over-sampling technique (SMOTE). Also, results of the multinomial logit model show that (1) an increase in travel cost would decrease the utility of all the transportation modes; (2) people are less sensitive to the travel distance for the metro mode or a multi-modal option that containing metro, i.e., compared to other modes, people would be more willing to tolerate long-distance metro trips. This indicates that metro lines might be a good candidate for large cities.