 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Reference Documents for Zero-Shot Ranking via Large Language Models
Jun 13, 2025Large Language Models (LLMs) have demonstrated exceptional performance in the task of text ranking for information retrieval. While Pointwise ranking approaches offer computational efficiency by scoring documents independently, they often yield biased relevance estimates due to the lack of inter-document comparisons. In contrast, Pairwise methods improve ranking accuracy by explicitly comparing document pairs, but suffer from substantial computational overhead with quadratic complexity ($O(n^2)$). To address this tradeoff, we propose \textbf{RefRank}, a simple and effective comparative ranking method based on a fixed reference document. Instead of comparing all document pairs, RefRank prompts the LLM to evaluate each candidate relative to a shared reference anchor. By selecting the reference anchor that encapsulates the core query intent, RefRank implicitly captures relevance cues, enabling indirect comparison between documents via this common anchor. This reduces computational cost to linear time ($O(n)$) while importantly, preserving the advantages of comparative evaluation. To further enhance robustness, we aggregate multiple RefRank outputs using a weighted averaging scheme across different reference choices. Experiments on several benchmark datasets and with various LLMs show that RefRank significantly outperforms Pointwise baselines and could achieve performance at least on par with Pairwise approaches with a significantly lower computational cost.
Autoregressive Adversarial Post-Training for Real-Time Interactive Video Generation
Jun 11, 2025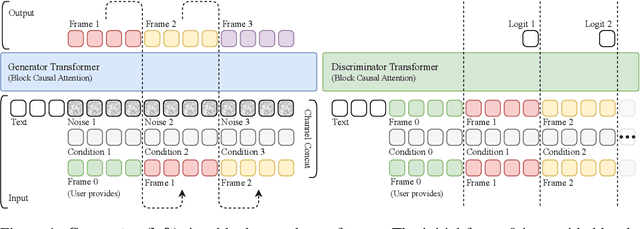
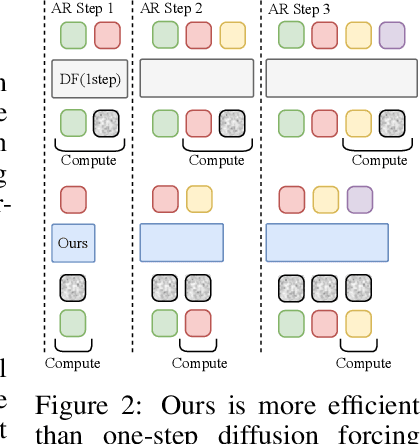
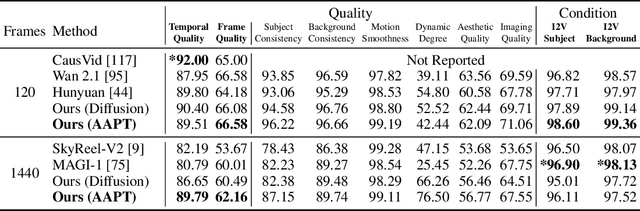

Existing large-scale video generation models are computationally intensive, preventing adoption in real-time and interactive applications. In this work, we propose autoregressive adversarial post-training (AAPT) to transform a pre-trained latent video diffusion model into a real-time, interactive video generator. Our model autoregressively generates a latent frame at a time using a single neural function evaluation (1NFE). The model can stream the result to the user in real time and receive interactive responses as controls to generate the next latent frame. Unlike existing approaches, our method explores adversarial training as an effective paradigm for autoregressive generation. This not only allows us to design an architecture that is more efficient for one-step generation while fully utilizing the KV cache, but also enables training the model in a student-forcing manner that proves to be effective in reducing error accumulation during long video generation. Our experiments demonstrate that our 8B model achieves real-time, 24fps, streaming video generation at 736x416 resolution on a single H100, or 1280x720 on 8xH100 up to a minute long (1440 frames). Visit our research website at https://seaweed-apt.com/2
SSS: Semi-Supervised SAM-2 with Efficient Prompting for Medical Imaging Segmentation
Jun 10, 2025In the era of information explosion, efficiently leveraging large-scale unlabeled data while minimizing the reliance on high-quality pixel-level annotations remains a critical challenge in the field of medical imaging. Semi-supervised learning (SSL) enhances the utilization of unlabeled data by facilitating knowledge transfer, significantly improving the performance of fully supervised models and emerging as a highly promising research direction in medical image analysis. Inspired by the ability of Vision Foundation Models (e.g., SAM-2) to provide rich prior knowledge, we propose SSS (Semi-Supervised SAM-2), a novel approach that leverages SAM-2's robust feature extraction capabilities to uncover latent knowledge in unlabeled medical images, thus effectively enhancing feature support for fully supervised medical image segmentation. Specifically, building upon the single-stream "weak-to-strong" consistency regularization framework, this paper introduces a Discriminative Feature Enhancement (DFE) mechanism to further explore the feature discrepancies introduced by various data augmentation strategies across multiple views. By leveraging feature similarity and dissimilarity across multi-scale augmentation techniques, the method reconstructs and models the features, thereby effectively optimizing the salient regions. Furthermore, a prompt generator is developed that integrates Physical Constraints with a Sliding Window (PCSW) mechanism to generate input prompts for unlabeled data, fulfilling SAM-2's requirement for additional prompts. Extensive experiments demonstrate the superiority of the proposed method for semi-supervised medical image segmentation on two multi-label datasets, i.e., ACDC and BHSD. Notably, SSS achieves an average Dice score of 53.15 on BHSD, surpassing the previous state-of-the-art method by +3.65 Dice. Code will be available at https://github.com/AIGeeksGroup/SSS.
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Jun 10, 2025



Notable breakthroughs in diffusion modeling have propelled rapid improvements in video generation, yet current foundational model still face critical challenges in simultaneously balancing prompt following, motion plausibility, and visual quality. In this report, we introduce Seedance 1.0, a high-performance and inference-efficient video foundation generation model that integrates several core technical improvements: (i) multi-source data curation augmented with precision and meaningful video captioning, enabling comprehensive learning across diverse scenarios; (ii) an efficient architecture design with proposed training paradigm, which allows for natively supporting multi-shot generation and jointly learning of both text-to-video and image-to-video tasks. (iii) carefully-optimized post-training approaches leveraging fine-grained supervised fine-tuning, and video-specific RLHF with multi-dimensional reward mechanisms for comprehensive performance improvements; (iv) excellent model acceleration achieving ~10x inference speedup through multi-stage distillation strategies and system-level optimizations. Seedance 1.0 can generate a 5-second video at 1080p resolution only with 41.4 seconds (NVIDIA-L20). Compared to state-of-the-art video generation models, Seedance 1.0 stands out with high-quality and fast video generation having superior spatiotemporal fluidity with structural stability, precise instruction adherence in complex multi-subject contexts, native multi-shot narrative coherence with consistent subject representation.
SeedVR2: One-Step Video Restoration via Diffusion Adversarial Post-Training
Jun 05, 2025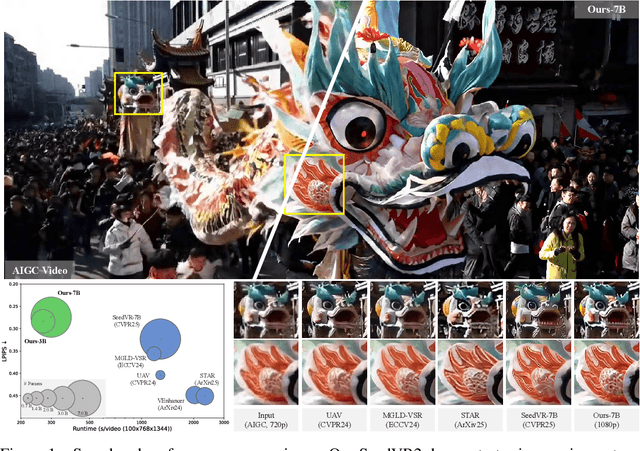
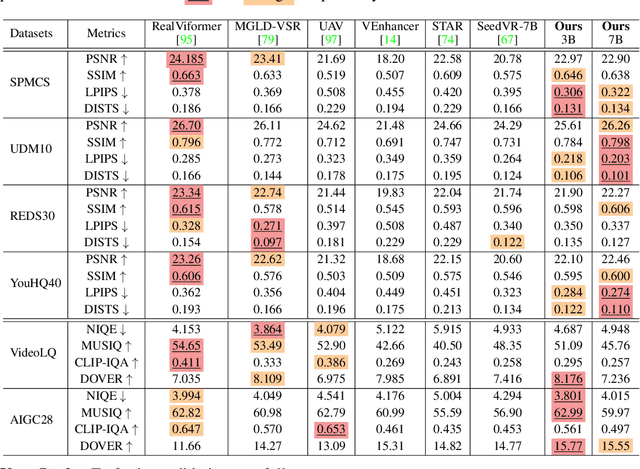
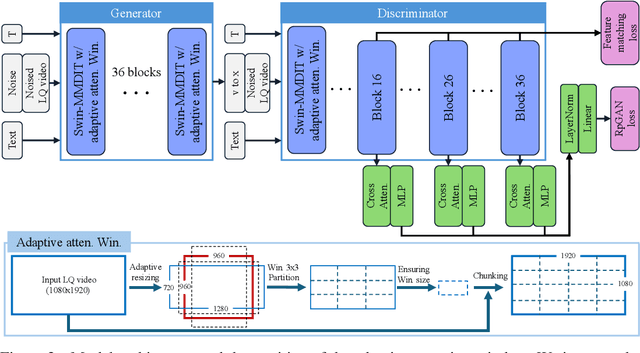
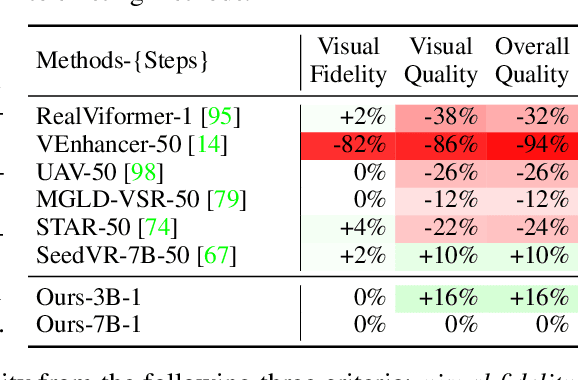
Recent advances in diffusion-based video restoration (VR) demonstrate significant improvement in visual quality, yet yield a prohibitive computational cost during inference. While several distillation-based approaches have exhibited the potential of one-step image restoration, extending existing approaches to VR remains challenging and underexplored, particularly when dealing with high-resolution video in real-world settings. In this work, we propose a one-step diffusion-based VR model, termed as SeedVR2, which performs adversarial VR training against real data. To handle the challenging high-resolution VR within a single step, we introduce several enhancements to both model architecture and training procedures. Specifically, an adaptive window attention mechanism is proposed, where the window size is dynamically adjusted to fit the output resolutions, avoiding window inconsistency observed under high-resolution VR using window attention with a predefined window size. To stabilize and improve the adversarial post-training towards VR, we further verify the effectiveness of a series of losses, including a proposed feature matching loss without significantly sacrificing training efficiency. Extensive experiments show that SeedVR2 can achieve comparable or even better performance compared with existing VR approaches in a single step.
CodeV-R1: Reasoning-Enhanced Verilog Generation
May 30, 2025Large language models (LLMs) trained via reinforcement learning with verifiable reward (RLVR) have achieved breakthroughs on tasks with explicit, automatable verification, such as software programming and mathematical problems. Extending RLVR to electronic design automation (EDA), especially automatically generating hardware description languages (HDLs) like Verilog from natural-language (NL) specifications, however, poses three key challenges: the lack of automated and accurate verification environments, the scarcity of high-quality NL-code pairs, and the prohibitive computation cost of RLVR. To this end, we introduce CodeV-R1, an RLVR framework for training Verilog generation LLMs. First, we develop a rule-based testbench generator that performs robust equivalence checking against golden references. Second, we propose a round-trip data synthesis method that pairs open-source Verilog snippets with LLM-generated NL descriptions, verifies code-NL-code consistency via the generated testbench, and filters out inequivalent examples to yield a high-quality dataset. Third, we employ a two-stage "distill-then-RL" training pipeline: distillation for the cold start of reasoning abilities, followed by adaptive DAPO, our novel RLVR algorithm that can reduce training cost by adaptively adjusting sampling rate. The resulting model, CodeV-R1-7B, achieves 68.6% and 72.9% pass@1 on VerilogEval v2 and RTLLM v1.1, respectively, surpassing prior state-of-the-art by 12~20%, while matching or even exceeding the performance of 671B DeepSeek-R1. We will release our model, training pipeline, and dataset to facilitate research in EDA and LLM communities.
IKMo: Image-Keyframed Motion Generation with Trajectory-Pose Conditioned Motion Diffusion Model
May 27, 2025Existing human motion generation methods with trajectory and pose inputs operate global processing on both modalities, leading to suboptimal outputs. In this paper, we propose IKMo, an image-keyframed motion generation method based on the diffusion model with trajectory and pose being decoupled. The trajectory and pose inputs go through a two-stage conditioning framework. In the first stage, the dedicated optimization module is applied to refine inputs. In the second stage, trajectory and pose are encoded via a Trajectory Encoder and a Pose Encoder in parallel. Then, motion with high spatial and semantic fidelity is guided by a motion ControlNet, which processes the fused trajectory and pose data. Experiment results based on HumanML3D and KIT-ML datasets demonstrate that the proposed method outperforms state-of-the-art on all metrics under trajectory-keyframe constraints. In addition, MLLM-based agents are implemented to pre-process model inputs. Given texts and keyframe images from users, the agents extract motion descriptions, keyframe poses, and trajectories as the optimized inputs into the motion generation model. We conducts a user study with 10 participants. The experiment results prove that the MLLM-based agents pre-processing makes generated motion more in line with users' expectation. We believe that the proposed method improves both the fidelity and controllability of motion generation by the diffusion model.
Benchmarking and Pushing the Multi-Bias Elimination Boundary of LLMs via Causal Effect Estimation-guided Debiasing
May 22, 2025Despite significant progress, recent studies have indicated that current large language models (LLMs) may still utilize bias during inference, leading to the poor generalizability of LLMs. Some benchmarks are proposed to investigate the generalizability of LLMs, with each piece of data typically containing one type of controlled bias. However, a single piece of data may contain multiple types of biases in practical applications. To bridge this gap, we propose a multi-bias benchmark where each piece of data contains five types of biases. The evaluations conducted on this benchmark reveal that the performance of existing LLMs and debiasing methods is unsatisfying, highlighting the challenge of eliminating multiple types of biases simultaneously. To overcome this challenge, we propose a causal effect estimation-guided multi-bias elimination method (CMBE). This method first estimates the causal effect of multiple types of biases simultaneously. Subsequently, we eliminate the causal effect of biases from the total causal effect exerted by both the semantic information and biases during inference. Experimental results show that CMBE can effectively eliminate multiple types of bias simultaneously to enhance the generalizability of LLMs.
DC-Scene: Data-Centric Learning for 3D Scene Understanding
May 21, 20253D scene understanding plays a fundamental role in vision applications such as robotics, autonomous driving, and augmented reality. However, advancing learning-based 3D scene understanding remains challenging due to two key limitations: (1) the large scale and complexity of 3D scenes lead to higher computational costs and slower training compared to 2D counterparts; and (2) high-quality annotated 3D datasets are significantly scarcer than those available for 2D vision. These challenges underscore the need for more efficient learning paradigms. In this work, we propose DC-Scene, a data-centric framework tailored for 3D scene understanding, which emphasizes enhancing data quality and training efficiency. Specifically, we introduce a CLIP-driven dual-indicator quality (DIQ) filter, combining vision-language alignment scores with caption-loss perplexity, along with a curriculum scheduler that progressively expands the training pool from the top 25% to 75% of scene-caption pairs. This strategy filters out noisy samples and significantly reduces dependence on large-scale labeled 3D data. Extensive experiments on ScanRefer and Nr3D demonstrate that DC-Scene achieves state-of-the-art performance (86.1 CIDEr with the top-75% subset vs. 85.4 with the full dataset) while reducing training cost by approximately two-thirds, confirming that a compact set of high-quality samples can outperform exhaustive training. Code will be available at https://github.com/AIGeeksGroup/DC-Scene.
UFO-RL: Uncertainty-Focused Optimization for Efficient Reinforcement Learning Data Selection
May 18, 2025Scaling RL for LLMs is computationally expensive, largely due to multi-sampling for policy optimization and evaluation, making efficient data selection crucial. Inspired by the Zone of Proximal Development (ZPD) theory, we hypothesize LLMs learn best from data within their potential comprehension zone. Addressing the limitation of conventional, computationally intensive multi-sampling methods for data assessment, we introduce UFO-RL. This novel framework uses a computationally efficient single-pass uncertainty estimation to identify informative data instances, achieving up to 185x faster data evaluation. UFO-RL leverages this metric to select data within the estimated ZPD for training. Experiments show that training with just 10% of data selected by UFO-RL yields performance comparable to or surpassing full-data training, reducing overall training time by up to 16x while enhancing stability and generalization. UFO-RL offers a practical and highly efficient strategy for scaling RL fine-tuning of LLMs by focusing learning on valuable data.