 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinkPrune: Pruning Long Chain-of-Thought of LLMs via Reinforcement Learning
Apr 02, 2025



We present ThinkPrune, a simple yet effective method for pruning the thinking length for long-thinking LLMs, which has been found to often produce inefficient and redundant thinking processes. Existing preliminary explorations of reducing thinking length primarily focus on forcing the thinking process to early exit, rather than adapting the LLM to optimize and consolidate the thinking process, and therefore the length-performance tradeoff observed so far is sub-optimal. To fill this gap, ThinkPrune offers a simple solution that continuously trains the long-thinking LLMs via reinforcement learning (RL) with an added token limit, beyond which any unfinished thoughts and answers will be discarded, resulting in a zero reward. To further preserve model performance, we introduce an iterative length pruning approach, where multiple rounds of RL are conducted, each with an increasingly more stringent token limit. We observed that ThinkPrune results in a remarkable performance-length tradeoff -- on the AIME24 dataset, the reasoning length of DeepSeek-R1-Distill-Qwen-1.5B can be reduced by half with only 2% drop in performance. We also observed that after pruning, the LLMs can bypass unnecessary steps while keeping the core reasoning process complete. Code is available at https://github.com/UCSB-NLP-Chang/ThinkPrune.
OrchMLLM: Orchestrate Multimodal Data with Batch Post-Balancing to Accelerate Multimodal Large Language Model Training
Mar 31, 2025Multimodal large language models (MLLMs), such as GPT-4o, are garnering significant attention. During the exploration of MLLM training, we identified Modality Composition Incoherence, a phenomenon that the proportion of a certain modality varies dramatically across different examples. It exacerbates the challenges of addressing mini-batch imbalances, which lead to uneven GPU utilization between Data Parallel (DP) instances and severely degrades the efficiency and scalability of MLLM training, ultimately affecting training speed and hindering further research on MLLMs. To address these challenges, we introduce OrchMLLM, a comprehensive framework designed to mitigate the inefficiencies in MLLM training caused by Modality Composition Incoherence. First, we propose Batch Post-Balancing Dispatcher, a technique that efficiently eliminates mini-batch imbalances in sequential data. Additionally, we integrate MLLM Global Orchestrator into the training framework to orchestrate multimodal data and tackle the issues arising from Modality Composition Incoherence. We evaluate OrchMLLM across various MLLM sizes, demonstrating its efficiency and scalability. Experimental results reveal that OrchMLLM achieves a Model FLOPs Utilization (MFU) of $41.6\%$ when training an 84B MLLM with three modalities on $2560$ H100 GPUs, outperforming Megatron-LM by up to $3.1\times$ in throughput.
Hybrid Time-Domain Behavior Model Based on Neural Differential Equations and RNNs
Mar 28, 2025



Nonlinear dynamics system identification is crucial for circuit emulation. Traditional continuous-time domain modeling approaches have limitations in fitting capability and computational efficiency when used for modeling circuit IPs and device behaviors.This paper presents a novel continuous-time domain hybrid modeling paradigm. It integrates neural network differential models with recurrent neural networks (RNNs), creating NODE-RNN and NCDE-RNN models based on neural ordinary differential equations (NODE) and neural controlled differential equations (NCDE), respectively.Theoretical analysis shows that this hybrid model has mathematical advantages in event-driven dynamic mutation response and gradient propagation stability. Validation using real data from PIN diodes in high-power microwave environments shows NCDE-RNN improves fitting accuracy by 33\% over traditional NCDE, and NODE-RNN by 24\% over CTRNN, especially in capturing nonlinear memory effects.The model has been successfully deployed in Verilog-A and validated through circuit emulation, confirming its compatibility with existing platforms and practical value.This hybrid dynamics paradigm, by restructuring the neural differential equation solution path, offers new ideas for high-precision circuit time-domain modeling and is significant for complex nonlinear circuit system modeling.
PLAY2PROMPT: Zero-shot Tool Instruction Optimization for LLM Agents via Tool Play
Mar 18, 2025



Large language models (LLMs) are increasingly integrated with specialized external tools, yet many tasks demand zero-shot tool usage with minimal or noisy documentation. Existing solutions rely on manual rewriting or labeled data for validation, making them inapplicable in true zero-shot settings. To address these challenges, we propose PLAY2PROMPT, an automated framework that systematically "plays" with each tool to explore its input-output behaviors. Through this iterative trial-and-error process, PLAY2PROMPT refines tool documentation and generates usage examples without any labeled data. These examples not only guide LLM inference but also serve as validation to further enhance tool utilization. Extensive experiments on real-world tasks demonstrate that PLAY2PROMPT significantly improves zero-shot tool performance across both open and closed models, offering a scalable and effective solution for domain-specific tool integration.
Multimodal Language Modeling for High-Accuracy Single Cell Transcriptomics Analysis and Generation
Mar 12, 2025Pre-trained language models (PLMs) have revolutionized scientific research, yet their application to single-cell analysis remains limited. Text PLMs cannot process single-cell RNA sequencing data, while cell PLMs lack the ability to handle free text, restricting their use in multimodal tasks. Existing efforts to bridge these modalities often suffer from information loss or inadequate single-modal pre-training, leading to suboptimal performances. To address these challenges, we propose Single-Cell MultiModal Generative Pre-trained Transformer (scMMGPT), a unified PLM for joint cell and text modeling. scMMGPT effectively integrates the state-of-the-art cell and text PLMs, facilitating cross-modal knowledge sharing for improved performance. To bridge the text-cell modality gap, scMMGPT leverages dedicated cross-modal projectors, and undergoes extensive pre-training on 27 million cells -- the largest dataset for multimodal cell-text PLMs to date. This large-scale pre-training enables scMMGPT to excel in joint cell-text tasks, achieving an 84\% relative improvement of textual discrepancy for cell description generation, 20.5\% higher accuracy for cell type annotation, and 4\% improvement in $k$-NN accuracy for text-conditioned pseudo-cell generation, outperforming baselines.
The Challenge of Identifying the Origin of Black-Box Large Language Models
Mar 06, 2025



The tremendous commercial potential of large language models (LLMs) has heightened concerns about their unauthorized use. Third parties can customize LLMs through fine-tuning and offer only black-box API access, effectively concealing unauthorized usage and complicating external auditing processes. This practice not only exacerbates unfair competition, but also violates licensing agreements. In response, identifying the origin of black-box LLMs is an intrinsic solution to this issue. In this paper, we first reveal the limitations of state-of-the-art passive and proactive identification methods with experiments on 30 LLMs and two real-world black-box APIs. Then, we propose the proactive technique, PlugAE, which optimizes adversarial token embeddings in a continuous space and proactively plugs them into the LLM for tracing and identification. The experiments show that PlugAE can achieve substantial improvement in identifying fine-tuned derivatives. We further advocate for legal frameworks and regulations to better address the challenges posed by the unauthorized use of LLMs.
Measuring What Makes You Unique: Difference-Aware User Modeling for Enhancing LLM Personalization
Mar 04, 2025Personalizing Large Language Models (LLMs) has become a critical step in facilitating their widespread application to enhance individual life experiences. In pursuit of personalization, distilling key preference information from an individual's historical data as instructional preference context to customize LLM generation has emerged as a promising direction. However, these methods face a fundamental limitation by overlooking the inter-user comparative analysis, which is essential for identifying the inter-user differences that truly shape preferences. To address this limitation, we propose Difference-aware Personalization Learning (DPL), a novel approach that emphasizes extracting inter-user differences to enhance LLM personalization. DPL strategically selects representative users for comparison and establishes a structured standard to extract meaningful, task-relevant differences for customizing LLM generation. Extensive experiments on real-world datasets demonstrate that DPL significantly enhances LLM personalization. We release our code at https://github.com/SnowCharmQ/DPL.
Code-as-Symbolic-Planner: Foundation Model-Based Robot Planning via Symbolic Code Generation
Mar 03, 2025



Recent works have shown great potentials of Large Language Models (LLMs) in robot task and motion planning (TAMP). Current LLM approaches generate text- or code-based reasoning chains with sub-goals and action plans. However, they do not fully leverage LLMs' symbolic computing and code generation capabilities. Many robot TAMP tasks involve complex optimization under multiple constraints, where pure textual reasoning is insufficient. While augmenting LLMs with predefined solvers and planners improves performance, it lacks generalization across tasks. Given LLMs' growing coding proficiency, we enhance their TAMP capabilities by steering them to generate code as symbolic planners for optimization and constraint verification. Unlike prior work that uses code to interface with robot action modules, we steer LLMs to generate code as solvers, planners, and checkers for TAMP tasks requiring symbolic computing, while still leveraging textual reasoning to incorporate common sense. With a multi-round guidance and answer evolution framework, the proposed Code-as-Symbolic-Planner improves success rates by average 24.1\% over best baseline methods across seven typical TAMP tasks and three popular LLMs. Code-as-Symbolic-Planner shows strong effectiveness and generalizability across discrete and continuous environments, 2D/3D simulations and real-world settings, as well as single- and multi-robot tasks with diverse requirements. See our project website https://yongchao98.github.io/Code-Symbol-Planner/ for prompts, videos, and code.
Fairness and/or Privacy on Social Graphs
Mar 03, 2025Graph Neural Networks (GNNs) have shown remarkable success in various graph-based learning tasks. However, recent studies have raised concerns about fairness and privacy issues in GNNs, highlighting the potential for biased or discriminatory outcomes and the vulnerability of sensitive information. This paper presents a comprehensive investigation of fairness and privacy in GNNs, exploring the impact of various fairness-preserving measures on model performance. We conduct experiments across diverse datasets and evaluate the effectiveness of different fairness interventions. Our analysis considers the trade-offs between fairness, privacy, and accuracy, providing insights into the challenges and opportunities in achieving both fair and private graph learning. The results highlight the importance of carefully selecting and combining fairness-preserving measures based on the specific characteristics of the data and the desired fairness objectives. This study contributes to a deeper understanding of the complex interplay between fairness, privacy, and accuracy in GNNs, paving the way for the development of more robust and ethical graph learning models.
Label-free Prediction of Vascular Connectivity in Perfused Microvascular Networks in vitro
Feb 25, 2025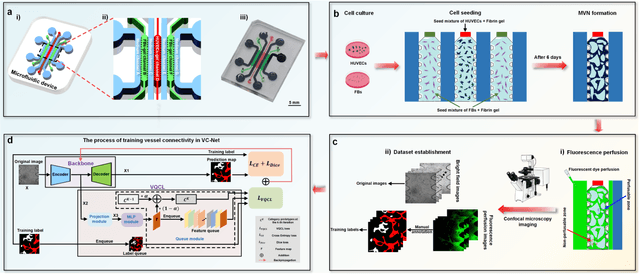
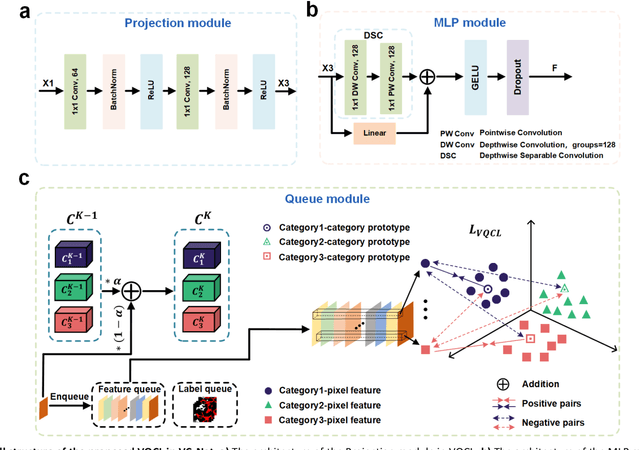
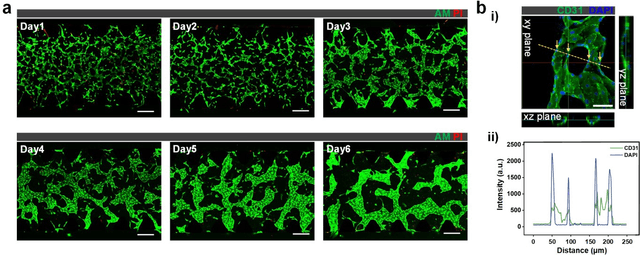
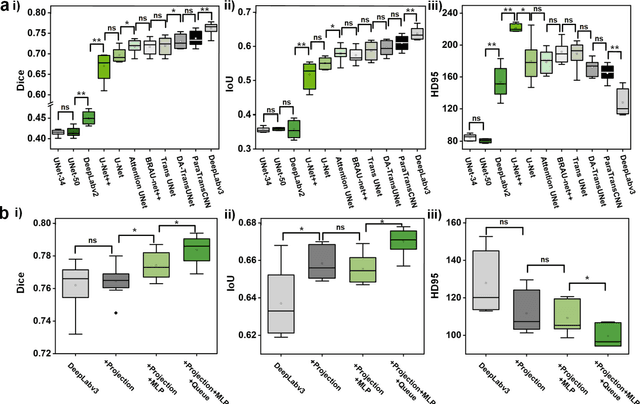
Continuous monitoring and in-situ assessment of microvascular connectivity have significant implications for culturing vascularized organoids and optimizing the therapeutic strategies. However, commonly used methods for vascular connectivity assessment heavily rely on fluorescent labels that may either raise biocompatibility concerns or interrupt the normal cell growth process. To address this issue, a Vessel Connectivity Network (VC-Net) was developed for label-free assessment of vascular connectivity. To validate the VC-Net, microvascular networks (MVNs) were cultured in vitro and their microscopic images were acquired at different culturing conditions as a training dataset. The VC-Net employs a Vessel Queue Contrastive Learning (VQCL) method and a class imbalance algorithm to address the issues of limited sample size, indistinctive class features and imbalanced class distribution in the dataset. The VC-Net successfully evaluated the vascular connectivity with no significant deviation from that by fluorescence imaging. In addition, the proposed VC-Net successfully differentiated the connectivity characteristics between normal and tumor-related MVNs. In comparison with those cultured in the regular microenvironment, the averaged connectivity of MVNs cultured in the tumor-related microenvironment decreased by 30.8%, whereas the non-connected area increased by 37.3%. This study provides a new avenue for label-free and continuous assessment of organoid or tumor vascularization in vitro.