 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFG 2025 TrustFAA: the First Workshop on Towards Trustworthy Facial Affect Analysis: Advancing Insights of Fairness, Explainability, and Safety (TrustFAA)
Jun 05, 2025With the increasing prevalence and deployment of Emotion AI-powered facial affect analysis (FAA) tools, concerns about the trustworthiness of these systems have become more prominent. This first workshop on "Towards Trustworthy Facial Affect Analysis: Advancing Insights of Fairness, Explainability, and Safety (TrustFAA)" aims to bring together researchers who are investigating different challenges in relation to trustworthiness-such as interpretability, uncertainty, biases, and privacy-across various facial affect analysis tasks, including macro/ micro-expression recognition, facial action unit detection, other corresponding applications such as pain and depression detection, as well as human-robot interaction and collaboration. In alignment with FG2025's emphasis on ethics, as demonstrated by the inclusion of an Ethical Impact Statement requirement for this year's submissions, this workshop supports FG2025's efforts by encouraging research, discussion and dialogue on trustworthy FAA.
HtFLlib: A Comprehensive Heterogeneous Federated Learning Library and Benchmark
Jun 04, 2025As AI evolves, collaboration among heterogeneous models helps overcome data scarcity by enabling knowledge transfer across institutions and devices. Traditional Federated Learning (FL) only supports homogeneous models, limiting collaboration among clients with heterogeneous model architectures. To address this, Heterogeneous Federated Learning (HtFL) methods are developed to enable collaboration across diverse heterogeneous models while tackling the data heterogeneity issue at the same time. However, a comprehensive benchmark for standardized evaluation and analysis of the rapidly growing HtFL methods is lacking. Firstly, the highly varied datasets, model heterogeneity scenarios, and different method implementations become hurdles to making easy and fair comparisons among HtFL methods. Secondly, the effectiveness and robustness of HtFL methods are under-explored in various scenarios, such as the medical domain and sensor signal modality. To fill this gap, we introduce the first Heterogeneous Federated Learning Library (HtFLlib), an easy-to-use and extensible framework that integrates multiple datasets and model heterogeneity scenarios, offering a robust benchmark for research and practical applications. Specifically, HtFLlib integrates (1) 12 datasets spanning various domains, modalities, and data heterogeneity scenarios; (2) 40 model architectures, ranging from small to large, across three modalities; (3) a modularized and easy-to-extend HtFL codebase with implementations of 10 representative HtFL methods; and (4) systematic evaluations in terms of accuracy, convergence, computation costs, and communication costs. We emphasize the advantages and potential of state-of-the-art HtFL methods and hope that HtFLlib will catalyze advancing HtFL research and enable its broader applications. The code is released at https://github.com/TsingZ0/HtFLlib.
DisTime: Distribution-based Time Representation for Video Large Language Models
May 30, 2025



Despite advances in general video understanding, Video Large Language Models (Video-LLMs) face challenges in precise temporal localization due to discrete time representations and limited temporally aware datasets. Existing methods for temporal expression either conflate time with text-based numerical values, add a series of dedicated temporal tokens, or regress time using specialized temporal grounding heads. To address these issues, we introduce DisTime, a lightweight framework designed to enhance temporal comprehension in Video-LLMs. DisTime employs a learnable token to create a continuous temporal embedding space and incorporates a Distribution-based Time Decoder that generates temporal probability distributions, effectively mitigating boundary ambiguities and maintaining temporal continuity. Additionally, the Distribution-based Time Encoder re-encodes timestamps to provide time markers for Video-LLMs. To overcome temporal granularity limitations in existing datasets, we propose an automated annotation paradigm that combines the captioning capabilities of Video-LLMs with the localization expertise of dedicated temporal models. This leads to the creation of InternVid-TG, a substantial dataset with 1.25M temporally grounded events across 179k videos, surpassing ActivityNet-Caption by 55 times. Extensive experiments demonstrate that DisTime achieves state-of-the-art performance across benchmarks in three time-sensitive tasks while maintaining competitive performance in Video QA tasks. Code and data are released at https://github.com/josephzpng/DisTime.
Skywork Open Reasoner 1 Technical Report
May 29, 2025The success of DeepSeek-R1 underscores the significant role of reinforcement learning (RL) in enhancing the reasoning capabilities of large language models (LLMs). In this work, we present Skywork-OR1, an effective and scalable RL implementation for long Chain-of-Thought (CoT) models. Building on the DeepSeek-R1-Distill model series, our RL approach achieves notable performance gains, increasing average accuracy across AIME24, AIME25, and LiveCodeBench from 57.8% to 72.8% (+15.0%) for the 32B model and from 43.6% to 57.5% (+13.9%) for the 7B model. Our Skywork-OR1-32B model surpasses both DeepSeek-R1 and Qwen3-32B on the AIME24 and AIME25 benchmarks, while achieving comparable results on LiveCodeBench. The Skywork-OR1-7B and Skywork-OR1-Math-7B models demonstrate competitive reasoning capabilities among models of similar size. We perform comprehensive ablation studies on the core components of our training pipeline to validate their effectiveness. Additionally, we thoroughly investigate the phenomenon of entropy collapse, identify key factors affecting entropy dynamics, and demonstrate that mitigating premature entropy collapse is critical for improved test performance. To support community research, we fully open-source our model weights, training code, and training datasets.
Graph Positional Autoencoders as Self-supervised Learners
May 29, 2025Graph self-supervised learning seeks to learn effective graph representations without relying on labeled data. Among various approaches, graph autoencoders (GAEs) have gained significant attention for their efficiency and scalability. Typically, GAEs take incomplete graphs as input and predict missing elements, such as masked nodes or edges. While effective, our experimental investigation reveals that traditional node or edge masking paradigms primarily capture low-frequency signals in the graph and fail to learn the expressive structural information. To address these issues, we propose Graph Positional Autoencoders (GraphPAE), which employs a dual-path architecture to reconstruct both node features and positions. Specifically, the feature path uses positional encoding to enhance the message-passing processing, improving GAE's ability to predict the corrupted information. The position path, on the other hand, leverages node representations to refine positions and approximate eigenvectors, thereby enabling the encoder to learn diverse frequency information. We conduct extensive experiments to verify the effectiveness of GraphPAE, including heterophilic node classification, graph property prediction, and transfer learning. The results demonstrate that GraphPAE achieves state-of-the-art performance and consistently outperforms baselines by a large margin.
Towards Minimizing Feature Drift in Model Merging: Layer-wise Task Vector Fusion for Adaptive Knowledge Integration
May 29, 2025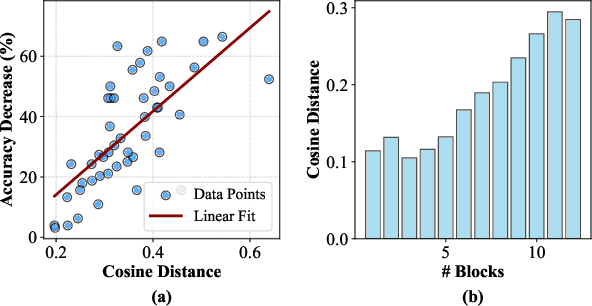
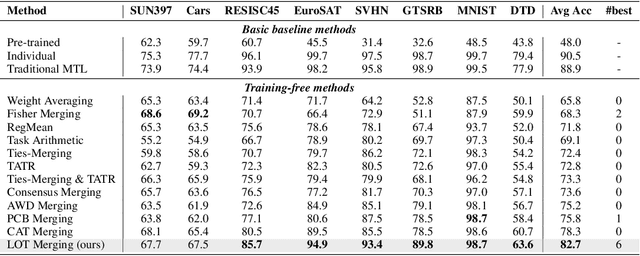
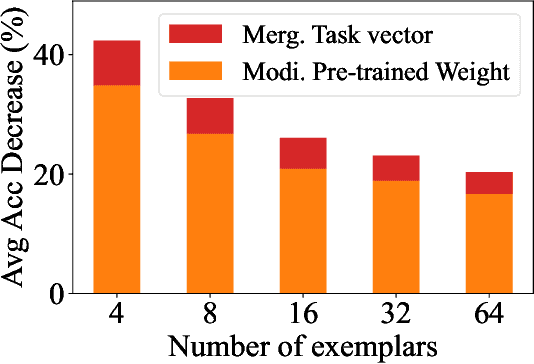
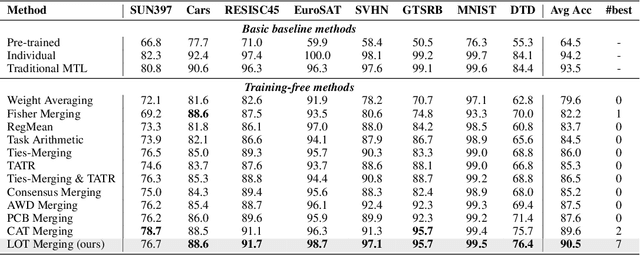
Multi-task model merging aims to consolidate knowledge from multiple fine-tuned task-specific experts into a unified model while minimizing performance degradation. Existing methods primarily approach this by minimizing differences between task-specific experts and the unified model, either from a parameter-level or a task-loss perspective. However, parameter-level methods exhibit a significant performance gap compared to the upper bound, while task-loss approaches entail costly secondary training procedures. In contrast, we observe that performance degradation closely correlates with feature drift, i.e., differences in feature representations of the same sample caused by model merging. Motivated by this observation, we propose Layer-wise Optimal Task Vector Merging (LOT Merging), a technique that explicitly minimizes feature drift between task-specific experts and the unified model in a layer-by-layer manner. LOT Merging can be formulated as a convex quadratic optimization problem, enabling us to analytically derive closed-form solutions for the parameters of linear and normalization layers. Consequently, LOT Merging achieves efficient model consolidation through basic matrix operations. Extensive experiments across vision and vision-language benchmarks demonstrate that LOT Merging significantly outperforms baseline methods, achieving improvements of up to 4.4% (ViT-B/32) over state-of-the-art approaches.
AI Mathematician: Towards Fully Automated Frontier Mathematical Research
May 28, 2025Large Reasoning Models (LRMs) have made significant progress in mathematical capabilities in recent times. However, these successes have been primarily confined to competition-level problems. In this work, we propose AI Mathematician (AIM) framework, which harnesses the reasoning strength of LRMs to support frontier mathematical research. We have identified two critical challenges of mathematical research compared to competition, {\it the intrinsic complexity of research problems} and {\it the requirement of procedural rigor}. To address these challenges, AIM incorporates two core strategies: an exploration mechanism to foster longer solution paths, and the pessimistic reasonable verification method to ensure reliability. This early version of AIM already exhibits strong capability in tackling research-level tasks. We conducted extensive experiments across several real-world mathematical topics and obtained promising results. AIM is able to autonomously construct substantial portions of proofs and uncover non-trivial insights within each research area. These findings highlight the potential of LRMs in mathematical discovery and suggest that LRM-based agent systems could significantly accelerate mathematical research in the future.
HTMNet: A Hybrid Network with Transformer-Mamba Bottleneck Multimodal Fusion for Transparent and Reflective Objects Depth Completion
May 28, 2025Transparent and reflective objects pose significant challenges for depth sensors, resulting in incomplete depth information that adversely affects downstream robotic perception and manipulation tasks. To address this issue, we propose HTMNet, a novel hybrid model integrating Transformer, CNN, and Mamba architectures. The encoder is based on a dual-branch CNN-Transformer framework, the bottleneck fusion module adopts a Transformer-Mamba architecture, and the decoder is built upon a multi-scale fusion module. We introduce a novel multimodal fusion module grounded in self-attention mechanisms and state space models, marking the first application of the Mamba architecture in the field of transparent object depth completion and revealing its promising potential. Additionally, we design an innovative multi-scale fusion module for the decoder that combines channel attention, spatial attention, and multi-scale feature extraction techniques to effectively integrate multi-scale features through a down-fusion strategy. Extensive evaluations on multiple public datasets demonstrate that our model achieves state-of-the-art(SOTA) performance, validating the effectiveness of our approach.
AdInject: Real-World Black-Box Attacks on Web Agents via Advertising Delivery
May 27, 2025Vision-Language Model (VLM) based Web Agents represent a significant step towards automating complex tasks by simulating human-like interaction with websites. However, their deployment in uncontrolled web environments introduces significant security vulnerabilities. Existing research on adversarial environmental injection attacks often relies on unrealistic assumptions, such as direct HTML manipulation, knowledge of user intent, or access to agent model parameters, limiting their practical applicability. In this paper, we propose AdInject, a novel and real-world black-box attack method that leverages the internet advertising delivery to inject malicious content into the Web Agent's environment. AdInject operates under a significantly more realistic threat model than prior work, assuming a black-box agent, static malicious content constraints, and no specific knowledge of user intent. AdInject includes strategies for designing malicious ad content aimed at misleading agents into clicking, and a VLM-based ad content optimization technique that infers potential user intents from the target website's context and integrates these intents into the ad content to make it appear more relevant or critical to the agent's task, thus enhancing attack effectiveness. Experimental evaluations demonstrate the effectiveness of AdInject, attack success rates exceeding 60% in most scenarios and approaching 100% in certain cases. This strongly demonstrates that prevalent advertising delivery constitutes a potent and real-world vector for environment injection attacks against Web Agents. This work highlights a critical vulnerability in Web Agent security arising from real-world environment manipulation channels, underscoring the urgent need for developing robust defense mechanisms against such threats. Our code is available at https://github.com/NicerWang/AdInject.
Agent-Environment Alignment via Automated Interface Generation
May 27, 2025



Large language model (LLM) agents have shown impressive reasoning capabilities in interactive decision-making tasks. These agents interact with environment through intermediate interfaces, such as predefined action spaces and interaction rules, which mediate the perception and action. However, mismatches often happen between the internal expectations of the agent regarding the influence of its issued actions and the actual state transitions in the environment, a phenomenon referred to as \textbf{agent-environment misalignment}. While prior work has invested substantially in improving agent strategies and environment design, the critical role of the interface still remains underexplored. In this work, we empirically demonstrate that agent-environment misalignment poses a significant bottleneck to agent performance. To mitigate this issue, we propose \textbf{ALIGN}, an \underline{A}uto-A\underline{l}igned \underline{I}nterface \underline{G}e\underline{n}eration framework that alleviates the misalignment by enriching the interface. Specifically, the ALIGN-generated interface enhances both the static information of the environment and the step-wise observations returned to the agent. Implemented as a lightweight wrapper, this interface achieves the alignment without modifying either the agent logic or the environment code. Experiments across multiple domains including embodied tasks, web navigation and tool-use, show consistent performance improvements, with up to a 45.67\% success rate improvement observed in ALFWorld. Meanwhile, ALIGN-generated interface can generalize across different agent architectures and LLM backbones without interface regeneration. Code and experimental results are available at https://github.com/THUNLP-MT/ALIGN.