 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhoneHarness: Harnessing Phone-Use Agents through Mixed GUI, CLI, and Tool Actions
Jun 12, 2026Phone agents are increasingly expected to complete real mobile workflows rather than merely predict the next screen action. However, much of the current mobile-agent literature still evaluates agents primarily as GUI controllers that observe a screen, emit taps and swipes, and are scored by target app state. Real phone-use tasks are broader: they require deciding when to use app GUIs, device-side commands, or structured tools, while leaving evidence that the intended side effect actually occurred. We introduce PhoneHarness, a mixed-action benchmark and execution harness for studying phone-use agents on verifiable mobile workflows. PhoneHarness runs a device-side agent loop over GUI, CLI, and host-side tool actions, combining deterministic action routing with bounded GUI delegation and auditable execution traces. Its benchmark, PhoneHarness Bench, evaluates whether agents complete tasks with observable side effects, not only whether they produce plausible final answers. On the annotated evaluation split, PhoneHarness reaches a 75.0% pass rate, outperforming the strongest non-PhoneHarness settings by 12.9 percentage points. PhoneHarness and PhoneHarness Bench therefore play distinct but mutually dependent roles: the harness makes mixed phone workflows executable, while the benchmark measures whether agents can use that harness reliably and safely. Our findings suggest that reliable phone automation depends on action-surface routing and verifiable execution, not only visual GUI control.
PhoneWorld: Scaling Phone-Use Agent Environments
May 28, 2026A central bottleneck for phone-use agents is that controllable, reproducible environments covering real mobile behavior are hard to build at scale. Existing mobile-agent benchmarks have made important progress on evaluation, but they do not by themselves provide a scalable way to construct many new phone-use environments. We present PhoneWorld, a reusable pipeline that converts real GUI trajectories and screenshots into controllable phone-use environments, executable tasks, automatic verifiers, and training rollouts. Rather than hand-building one mobile benchmark at a time, PhoneWorld uses real trajectories to recover which screens matter, how screens connect, which interactions must change environment state, and which user goals admit automatic verification. From these signals, it builds runnable mock Android apps backed by read-only app content and mutable state, then derives executable tasks, rule-based verifiers, and training rollouts from the same environments. In its current instantiation, PhoneWorld covers 34 apps across 16 domains, spanning common consumer mobile behaviors such as search, browsing, shopping, booking, media, and social interaction. Under a fixed training budget, replacing 10K steps from an auxiliary AndroidWorld corpus in an AndroidWorld-based baseline with broad PhoneWorld supervision improves all four evaluation benchmarks at once, raising HYMobileBench by 17.7 points, AndroidControl by 6.0 points, AndroidWorld by 14.7 points, and PhoneWorld by 52.5 points. We then study two additional scaling questions: increasing the amount of PhoneWorld supervision strongly improves PhoneWorld performance, and under a fixed PhoneWorld budget, expanding app coverage yields even larger gains. Overall, PhoneWorld shifts the focus from building one mobile benchmark at a time to scaling the supply of phone-use environments themselves.
UI-Venus-1.5 Technical Report
Feb 09, 2026GUI agents have emerged as a powerful paradigm for automating interactions in digital environments, yet achieving both broad generality and consistently strong task performance remains challenging.In this report, we present UI-Venus-1.5, a unified, end-to-end GUI Agent designed for robust real-world applications.The proposed model family comprises two dense variants (2B and 8B) and one mixture-of-experts variant (30B-A3B) to meet various downstream application scenarios.Compared to our previous version, UI-Venus-1.5 introduces three key technical advances: (1) a comprehensive Mid-Training stage leveraging 10 billion tokens across 30+ datasets to establish foundational GUI semantics; (2) Online Reinforcement Learning with full-trajectory rollouts, aligning training objectives with long-horizon, dynamic navigation in large-scale environments; and (3) a single unified GUI Agent constructed via Model Merging, which synthesizes domain-specific models (grounding, web, and mobile) into one cohesive checkpoint. Extensive evaluations demonstrate that UI-Venus-1.5 establishes new state-of-the-art performance on benchmarks such as ScreenSpot-Pro (69.6%), VenusBench-GD (75.0%), and AndroidWorld (77.6%), significantly outperforming previous strong baselines. In addition, UI-Venus-1.5 demonstrates robust navigation capabilities across a variety of Chinese mobile apps, effectively executing user instructions in real-world scenarios. Code: https://github.com/inclusionAI/UI-Venus; Model: https://huggingface.co/collections/inclusionAI/ui-venus
Full-Resolution Correspondence Learning for Image Translation
Dec 03, 2020
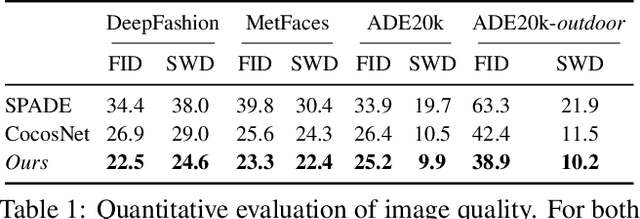
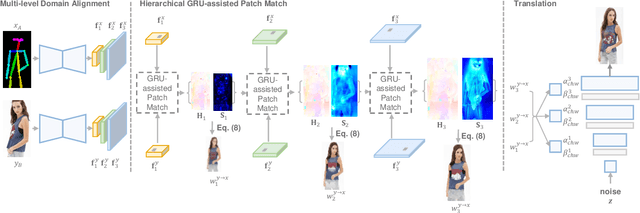
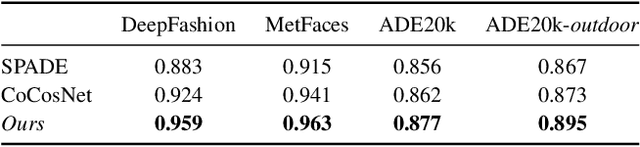
We present the full-resolution correspondence learning for cross-domain images, which aids image translation. We adopt a hierarchical strategy that uses the correspondence from coarse level to guide the finer levels. In each hierarchy, the correspondence can be efficiently computed via PatchMatch that iteratively leverages the matchings from the neighborhood. Within each PatchMatch iteration, the ConvGRU module is employed to refine the current correspondence considering not only the matchings of larger context but also the historic estimates. The proposed GRU-assisted PatchMatch is fully differentiable and highly efficient. When jointly trained with image translation, full-resolution semantic correspondence can be established in an unsupervised manner, which in turn facilitates the exemplar-based image translation. Experiments on diverse translation tasks show our approach performs considerably better than state-of-the-arts on producing high-resolution images.
Generating Person Images with Appearance-aware Pose Stylizer
Jul 17, 2020

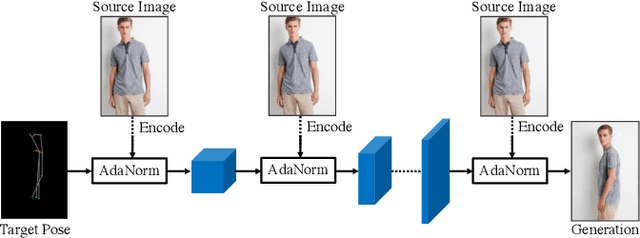
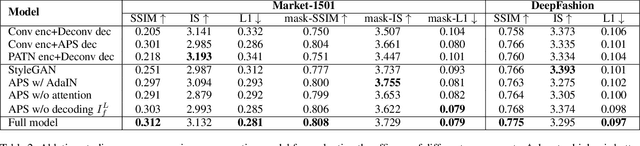
Generation of high-quality person images is challenging, due to the sophisticated entanglements among image factors, e.g., appearance, pose, foreground, background, local details, global structures, etc. In this paper, we present a novel end-to-end framework to generate realistic person images based on given person poses and appearances. The core of our framework is a novel generator called Appearance-aware Pose Stylizer (APS) which generates human images by coupling the target pose with the conditioned person appearance progressively. The framework is highly flexible and controllable by effectively decoupling various complex person image factors in the encoding phase, followed by re-coupling them in the decoding phase. In addition, we present a new normalization method named adaptive patch normalization, which enables region-specific normalization and shows a good performance when adopted in person image generation model. Experiments on two benchmark datasets show that our method is capable of generating visually appealing and realistic-looking results using arbitrary image and pose inputs.
Text Guided Person Image Synthesis
Apr 10, 2019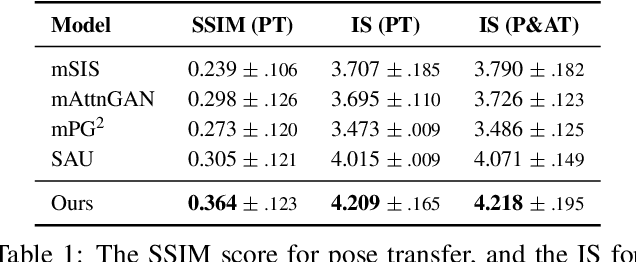
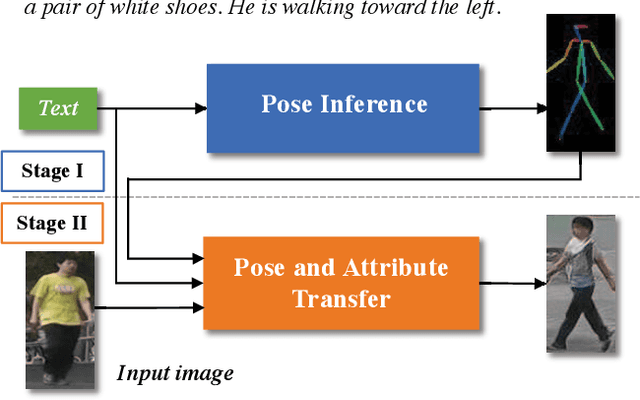
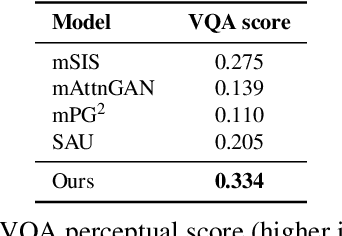
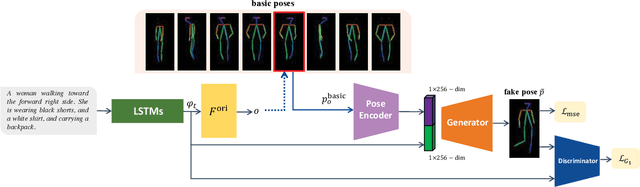
This paper presents a novel method to manipulate the visual appearance (pose and attribute) of a person image according to natural language descriptions. Our method can be boiled down to two stages: 1) text guided pose generation and 2) visual appearance transferred image synthesis. In the first stage, our method infers a reasonable target human pose based on the text. In the second stage, our method synthesizes a realistic and appearance transferred person image according to the text in conjunction with the target pose. Our method extracts sufficient information from the text and establishes a mapping between the image space and the language space, making generating and editing images corresponding to the description possible. We conduct extensive experiments to reveal the effectiveness of our method, as well as using the VQA Perceptual Score as a metric for evaluating the method. It shows for the first time that we can automatically edit the person image from the natural language descriptions.