 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Truncated Loss Minimization for Robust and Threshold-Resilient Geometric Estimation
Mar 16, 2026To achieve outlier-robust geometric estimation, robust objective functions are generally employed to mitigate the influence of outliers. The widely used consensus maximization(CM) is highly robust when paired with global branch-and-bound(BnB) search. However, CM relies solely on inlier counts and is sensitive to the inlier threshold. Besides, the discrete nature of CM leads to loose bounds, necessitating extensive BnB iterations and computation cost. Truncated losses(TL), another continuous alternative, leverage residual information more effectively and could potentially overcome these issues. But to our knowledge, no prior work has systematically explored globally minimizing TL with BnB and its potential for enhanced threshold resilience or search efficiency. In this work, we propose GTM, the first unified BnB-based framework for globally-optimal TL loss minimization across diverse geometric problems. GTM involves a hybrid solving design: given an n-dimensional problem, it performs BnB search over an (n-1)-dimensional subspace while the remaining 1D variable is solved by bounding the objective function. Our hybrid design not only reduces the search space, but also enables us to derive Lipschitz-continuous bounding functions that are general, tight, and can be efficiently solved by a classic global Lipschitz solver named DIRECT, which brings further acceleration. We conduct a systematic evaluation on various BnB-based methods for CM and TL on the robust linear regression problem, showing that GTM enjoys remarkable threshold resilience and the highest efficiency compared to baseline methods. Furthermore, we apply GTM on different geometric estimation problems with diverse residual forms. Extensive experiments demonstrate that GTM achieves state-of-the-art outlier-robustness and threshold-resilience while maintaining high efficiency across these estimation tasks.
A Linear N-Point Solver for Structure and Motion from Asynchronous Tracks
Jul 30, 2025Structure and continuous motion estimation from point correspondences is a fundamental problem in computer vision that has been powered by well-known algorithms such as the familiar 5-point or 8-point algorithm. However, despite their acclaim, these algorithms are limited to processing point correspondences originating from a pair of views each one representing an instantaneous capture of the scene. Yet, in the case of rolling shutter cameras, or more recently, event cameras, this synchronization breaks down. In this work, we present a unified approach for structure and linear motion estimation from 2D point correspondences with arbitrary timestamps, from an arbitrary set of views. By formulating the problem in terms of first-order dynamics and leveraging a constant velocity motion model, we derive a novel, linear point incidence relation allowing for the efficient recovery of both linear velocity and 3D points with predictable degeneracies and solution multiplicities. Owing to its general formulation, it can handle correspondences from a wide range of sensing modalities such as global shutter, rolling shutter, and event cameras, and can even combine correspondences from different collocated sensors. We validate the effectiveness of our solver on both simulated and real-world data, where we show consistent improvement across all modalities when compared to recent approaches. We believe our work opens the door to efficient structure and motion estimation from asynchronous data. Code can be found at https://github.com/suhang99/AsyncTrack-Motion-Solver.
DynOPETs: A Versatile Benchmark for Dynamic Object Pose Estimation and Tracking in Moving Camera Scenarios
Mar 25, 2025In the realm of object pose estimation, scenarios involving both dynamic objects and moving cameras are prevalent. However, the scarcity of corresponding real-world datasets significantly hinders the development and evaluation of robust pose estimation models. This is largely attributed to the inherent challenges in accurately annotating object poses in dynamic scenes captured by moving cameras. To bridge this gap, this paper presents a novel dataset DynOPETs and a dedicated data acquisition and annotation pipeline tailored for object pose estimation and tracking in such unconstrained environments. Our efficient annotation method innovatively integrates pose estimation and pose tracking techniques to generate pseudo-labels, which are subsequently refined through pose graph optimization. The resulting dataset offers accurate pose annotations for dynamic objects observed from moving cameras. To validate the effectiveness and value of our dataset, we perform comprehensive evaluations using 18 state-of-the-art methods, demonstrating its potential to accelerate research in this challenging domain. The dataset will be made publicly available to facilitate further exploration and advancement in the field.
NF-SLAM: Effective, Normalizing Flow-supported Neural Field representations for object-level visual SLAM in automotive applications
Mar 14, 2025We propose a novel, vision-only object-level SLAM framework for automotive applications representing 3D shapes by implicit signed distance functions. Our key innovation consists of augmenting the standard neural representation by a normalizing flow network. As a result, achieving strong representation power on the specific class of road vehicles is made possible by compact networks with only 16-dimensional latent codes. Furthermore, the newly proposed architecture exhibits a significant performance improvement in the presence of only sparse and noisy data, which is demonstrated through comparative experiments on synthetic data. The module is embedded into the back-end of a stereo-vision based framework for joint, incremental shape optimization. The loss function is given by a combination of a sparse 3D point-based SDF loss, a sparse rendering loss, and a semantic mask-based silhouette-consistency term. We furthermore leverage semantic information to determine keypoint extraction density in the front-end. Finally, experimental results on real-world data reveal accurate and reliable performance comparable to alternative frameworks that make use of direct depth readings. The proposed method performs well with only sparse 3D points obtained from bundle adjustment, and eventually continues to deliver stable results even under exclusive use of the mask-consistency term.
Full-DoF Egomotion Estimation for Event Cameras Using Geometric Solvers
Mar 05, 2025For event cameras, current sparse geometric solvers for egomotion estimation assume that the rotational displacements are known, such as those provided by an IMU. Thus, they can only recover the translational motion parameters. Recovering full-DoF motion parameters using a sparse geometric solver is a more challenging task, and has not yet been investigated. In this paper, we propose several solvers to estimate both rotational and translational velocities within a unified framework. Our method leverages event manifolds induced by line segments. The problem formulations are based on either an incidence relation for lines or a novel coplanarity relation for normal vectors. We demonstrate the possibility of recovering full-DoF egomotion parameters for both angular and linear velocities without requiring extra sensor measurements or motion priors. To achieve efficient optimization, we exploit the Adam framework with a first-order approximation of rotations for quick initialization. Experiments on both synthetic and real-world data demonstrate the effectiveness of our method. The code is available at https://github.com/jizhaox/relpose-event.
OpenGV 2.0: Motion prior-assisted calibration and SLAM with vehicle-mounted surround-view systems
Mar 05, 2025

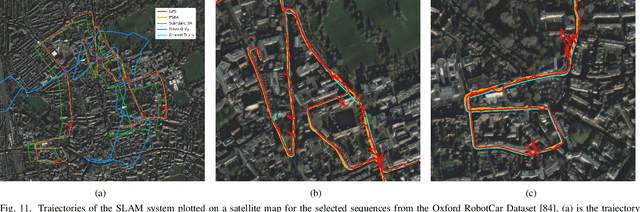
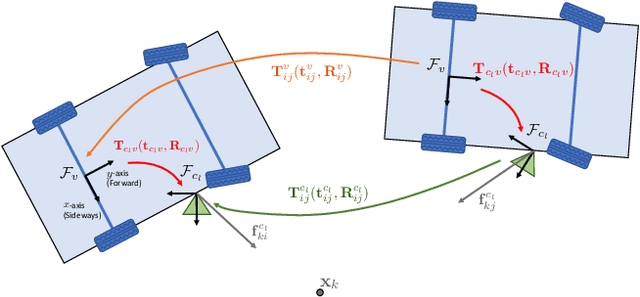
The present paper proposes optimization-based solutions to visual SLAM with a vehicle-mounted surround-view camera system. Owing to their original use-case, such systems often only contain a single camera facing into either direction and very limited overlap between fields of view. Our novelty consist of three optimization modules targeting at practical online calibration of exterior orientations from simple two-view geometry, reliable front-end initialization of relative displacements, and accurate back-end optimization using a continuous-time trajectory model. The commonality between the proposed modules is given by the fact that all three of them exploit motion priors that are related to the inherent non-holonomic characteristics of passenger vehicle motion. In contrast to prior related art, the proposed modules furthermore excel in terms of bypassing partial unobservabilities in the transformation variables that commonly occur for Ackermann-motion. As a further contribution, the modules are built into a novel surround-view camera SLAM system that specifically targets deployment on Ackermann vehicles operating in urban environments. All modules are studied in the context of in-depth ablation studies, and the practical validity of the entire framework is supported by a successful application to challenging, large-scale publicly available online datasets. Note that upon acceptance, the entire framework is scheduled for open-source release as part of an extension of the OpenGV library.
Motion-Aware Optical Camera Communication with Event Cameras
Dec 01, 2024As the ubiquity of smart mobile devices continues to rise, Optical Camera Communication systems have gained more attention as a solution for efficient and private data streaming. This system utilizes optical cameras to receive data from digital screens via visible light. Despite their promise, most of them are hindered by dynamic factors such as screen refreshing and rapid camera motion. CMOS cameras, often serving as the receivers, suffer from limited frame rates and motion-induced image blur, which degrade overall performance. To address these challenges, this paper unveils a novel system that utilizes event cameras. We introduce a dynamic visual marker and design event-based tracking algorithms to achieve fast localization and data streaming. Remarkably, the event camera's unique capabilities mitigate issues related to screen refresh rates and camera motion, enabling a high throughput of up to 114 Kbps in static conditions, and a 1 cm localization accuracy with 1% bit error rate under various camera motions.
Homotopy Continuation Made Easy: Regression-based Online Simulation of Starting Problem-Solution Pairs
Nov 06, 2024While automatically generated polynomial elimination templates have sparked great progress in the field of 3D computer vision, there remain many problems for which the degree of the constraints or the number of unknowns leads to intractability. In recent years, homotopy continuation has been introduced as a plausible alternative. However, the method currently depends on expensive parallel tracking of all possible solutions in the complex domain, or a classification network for starting problem-solution pairs trained over a limited set of real-world examples. Our innovation consists of employing a regression network trained in simulation to directly predict a solution from input correspondences, followed by an online simulator that invents a consistent problem-solution pair. Subsequently, homotopy continuation is applied to track that single solution back to the original problem. We apply this elegant combination to generalized camera resectioning, and also introduce a new solution to the challenging generalized relative pose and scale problem. As demonstrated, the proposed method successfully compensates the raw error committed by the regressor alone, and leads to state-of-the-art efficiency and success rates while running on CPU resources, only.
fCOP: Focal Length Estimation from Category-level Object Priors
Sep 29, 2024



In the realm of computer vision, the perception and reconstruction of the 3D world through vision signals heavily rely on camera intrinsic parameters, which have long been a subject of intense research within the community. In practical applications, without a strong scene geometry prior like the Manhattan World assumption or special artificial calibration patterns, monocular focal length estimation becomes a challenging task. In this paper, we propose a method for monocular focal length estimation using category-level object priors. Based on two well-studied existing tasks: monocular depth estimation and category-level object canonical representation learning, our focal solver takes depth priors and object shape priors from images containing objects and estimates the focal length from triplets of correspondences in closed form. Our experiments on simulated and real world data demonstrate that the proposed method outperforms the current state-of-the-art, offering a promising solution to the long-standing monocular focal length estimation problem.
GS-EVT: Cross-Modal Event Camera Tracking based on Gaussian Splatting
Sep 28, 2024Reliable self-localization is a foundational skill for many intelligent mobile platforms. This paper explores the use of event cameras for motion tracking thereby providing a solution with inherent robustness under difficult dynamics and illumination. In order to circumvent the challenge of event camera-based mapping, the solution is framed in a cross-modal way. It tracks a map representation that comes directly from frame-based cameras. Specifically, the proposed method operates on top of gaussian splatting, a state-of-the-art representation that permits highly efficient and realistic novel view synthesis. The key of our approach consists of a novel pose parametrization that uses a reference pose plus first order dynamics for local differential image rendering. The latter is then compared against images of integrated events in a staggered coarse-to-fine optimization scheme. As demonstrated by our results, the realistic view rendering ability of gaussian splatting leads to stable and accurate tracking across a variety of both publicly available and newly recorded data sequences.