 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided AbsoluteGrad: Magnitude of Gradients Matters to Explanation's Localization and Saliency
Apr 23, 2024This paper proposes a new gradient-based XAI method called Guided AbsoluteGrad for saliency map explanations. We utilize both positive and negative gradient magnitudes and employ gradient variance to distinguish the important areas for noise deduction. We also introduce a novel evaluation metric named ReCover And Predict (RCAP), which considers the Localization and Visual Noise Level objectives of the explanations. We propose two propositions for these two objectives and prove the necessity of evaluating them. We evaluate Guided AbsoluteGrad with seven gradient-based XAI methods using the RCAP metric and other SOTA metrics in three case studies: (1) ImageNet dataset with ResNet50 model; (2) International Skin Imaging Collaboration (ISIC) dataset with EfficientNet model; (3) the Places365 dataset with DenseNet161 model. Our method surpasses other gradient-based approaches, showcasing the quality of enhanced saliency map explanations through gradient magnitude.
XAIport: A Service Framework for the Early Adoption of XAI in AI Model Development
Mar 25, 2024


In this study, we propose the early adoption of Explainable AI (XAI) with a focus on three properties: Quality of explanation, the explanation summaries should be consistent across multiple XAI methods; Architectural Compatibility, for effective integration in XAI, the architecture styles of both the XAI methods and the models to be explained must be compatible with the framework; Configurable operations, XAI explanations are operable, akin to machine learning operations. Thus, an explanation for AI models should be reproducible and tractable to be trustworthy. We present XAIport, a framework of XAI microservices encapsulated into Open APIs to deliver early explanations as observation for learning model quality assurance. XAIport enables configurable XAI operations along with machine learning development. We quantify the operational costs of incorporating XAI with three cloud computer vision services on Microsoft Azure Cognitive Services, Google Cloud Vertex AI, and Amazon Rekognition. Our findings show comparable operational costs between XAI and traditional machine learning, with XAIport significantly improving both cloud AI model performance and explanation stability.
FineMath: A Fine-Grained Mathematical Evaluation Benchmark for Chinese Large Language Models
Mar 12, 2024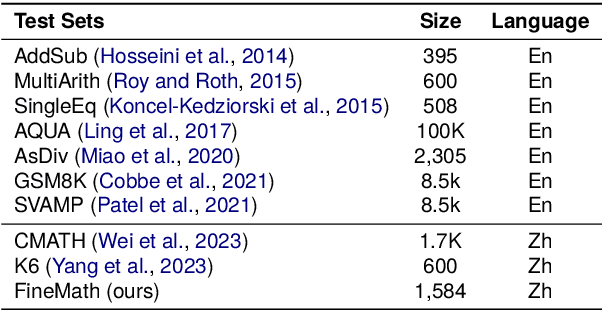
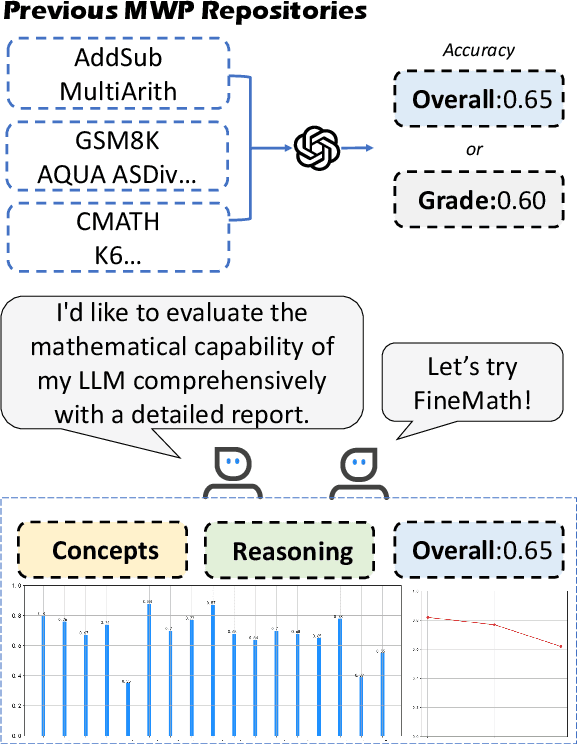
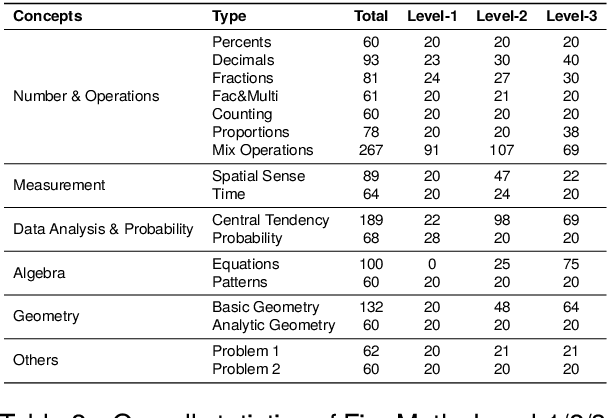
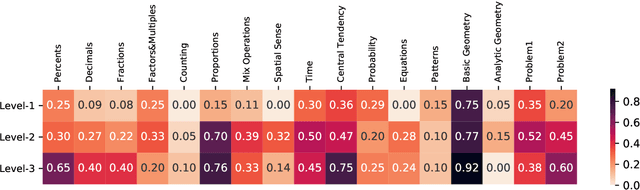
To thoroughly assess the mathematical reasoning abilities of Large Language Models (LLMs), we need to carefully curate evaluation datasets covering diverse mathematical concepts and mathematical problems at different difficulty levels. In pursuit of this objective, we propose FineMath in this paper, a fine-grained mathematical evaluation benchmark dataset for assessing Chinese LLMs. FineMath is created to cover the major key mathematical concepts taught in elementary school math, which are further divided into 17 categories of math word problems, enabling in-depth analysis of mathematical reasoning abilities of LLMs. All the 17 categories of math word problems are manually annotated with their difficulty levels according to the number of reasoning steps required to solve these problems. We conduct extensive experiments on a wide range of LLMs on FineMath and find that there is still considerable room for improvements in terms of mathematical reasoning capability of Chinese LLMs. We also carry out an in-depth analysis on the evaluation process and methods that have been overlooked previously. These two factors significantly influence the model results and our understanding of their mathematical reasoning capabilities. The dataset will be publicly available soon.
WeakSAM: Segment Anything Meets Weakly-supervised Instance-level Recognition
Feb 22, 2024Weakly supervised visual recognition using inexact supervision is a critical yet challenging learning problem. It significantly reduces human labeling costs and traditionally relies on multi-instance learning and pseudo-labeling. This paper introduces WeakSAM and solves the weakly-supervised object detection (WSOD) and segmentation by utilizing the pre-learned world knowledge contained in a vision foundation model, i.e., the Segment Anything Model (SAM). WeakSAM addresses two critical limitations in traditional WSOD retraining, i.e., pseudo ground truth (PGT) incompleteness and noisy PGT instances, through adaptive PGT generation and Region of Interest (RoI) drop regularization. It also addresses the SAM's problems of requiring prompts and category unawareness for automatic object detection and segmentation. Our results indicate that WeakSAM significantly surpasses previous state-of-the-art methods in WSOD and WSIS benchmarks with large margins, i.e. average improvements of 7.4% and 8.5%, respectively. The code is available at \url{https://github.com/hustvl/WeakSAM}.
MuChin: A Chinese Colloquial Description Benchmark for Evaluating Language Models in the Field of Music
Feb 15, 2024



The rapidly evolving multimodal Large Language Models (LLMs) urgently require new benchmarks to uniformly evaluate their performance on understanding and textually describing music. However, due to semantic gaps between Music Information Retrieval (MIR) algorithms and human understanding, discrepancies between professionals and the public, and low precision of annotations, existing music description datasets cannot serve as benchmarks. To this end, we present MuChin, the first open-source music description benchmark in Chinese colloquial language, designed to evaluate the performance of multimodal LLMs in understanding and describing music. We established the Caichong Music Annotation Platform (CaiMAP) that employs an innovative multi-person, multi-stage assurance method, and recruited both amateurs and professionals to ensure the precision of annotations and alignment with popular semantics. Utilizing this method, we built a dataset with multi-dimensional, high-precision music annotations, the Caichong Music Dataset (CaiMD), and carefully selected 1,000 high-quality entries to serve as the test set for MuChin. Based on MuChin, we analyzed the discrepancies between professionals and amateurs in terms of music description, and empirically demonstrated the effectiveness of annotated data for fine-tuning LLMs. Ultimately, we employed MuChin to evaluate existing music understanding models on their ability to provide colloquial descriptions of music. All data related to the benchmark and the code for scoring have been open-sourced.
Guiding Large Language Models with Divide-and-Conquer Program for Discerning Problem Solving
Feb 08, 2024



Foundation models, such as Large language Models (LLMs), have attracted significant amount of interest due to their large number of applications. Existing works show that appropriate prompt design, such as Chain-of-Thoughts, can unlock LLM's powerful capacity in diverse areas. However, when handling tasks involving repetitive sub-tasks and/or deceptive contents, such as arithmetic calculation and article-level fake news detection, existing prompting strategies either suffers from insufficient expressive power or intermediate errors triggered by hallucination. To make LLM more discerning to such intermediate errors, we propose to guide LLM with a Divide-and-Conquer program that simultaneously ensures superior expressive power and disentangles task decomposition, sub-task resolution, and resolution assembly process. Theoretic analysis reveals that our strategy can guide LLM to extend the expressive power of fixed-depth Transformer. Experiments indicate that our proposed method can achieve better performance than typical prompting strategies in tasks bothered by intermediate errors and deceptive contents, such as large integer multiplication, hallucination detection and misinformation detection.
A Survey of Privacy Threats and Defense in Vertical Federated Learning: From Model Life Cycle Perspective
Feb 06, 2024Vertical Federated Learning (VFL) is a federated learning paradigm where multiple participants, who share the same set of samples but hold different features, jointly train machine learning models. Although VFL enables collaborative machine learning without sharing raw data, it is still susceptible to various privacy threats. In this paper, we conduct the first comprehensive survey of the state-of-the-art in privacy attacks and defenses in VFL. We provide taxonomies for both attacks and defenses, based on their characterizations, and discuss open challenges and future research directions. Specifically, our discussion is structured around the model's life cycle, by delving into the privacy threats encountered during different stages of machine learning and their corresponding countermeasures. This survey not only serves as a resource for the research community but also offers clear guidance and actionable insights for practitioners to safeguard data privacy throughout the model's life cycle.
StepCoder: Improve Code Generation with Reinforcement Learning from Compiler Feedback
Feb 05, 2024



The advancement of large language models (LLMs) has significantly propelled the field of code generation. Previous work integrated reinforcement learning (RL) with compiler feedback for exploring the output space of LLMs to enhance code generation quality. However, the lengthy code generated by LLMs in response to complex human requirements makes RL exploration a challenge. Also, since the unit tests may not cover the complicated code, optimizing LLMs by using these unexecuted code snippets is ineffective. To tackle these challenges, we introduce StepCoder, a novel RL framework for code generation, consisting of two main components: CCCS addresses the exploration challenge by breaking the long sequences code generation task into a Curriculum of Code Completion Subtasks, while FGO only optimizes the model by masking the unexecuted code segments to provide Fine-Grained Optimization. In addition, we furthermore construct the APPS+ dataset for RL training, which is manually verified to ensure the correctness of unit tests. Experimental results show that our method improves the ability to explore the output space and outperforms state-of-the-art approaches in corresponding benchmarks. Our dataset APPS+ and StepCoder are available online.
TrustLLM: Trustworthiness in Large Language Models
Jan 25, 2024



Large language models (LLMs), exemplified by ChatGPT, have gained considerable attention for their excellent natural language processing capabilities. Nonetheless, these LLMs present many challenges, particularly in the realm of trustworthiness. Therefore, ensuring the trustworthiness of LLMs emerges as an important topic. This paper introduces TrustLLM, a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. Our findings firstly show that in general trustworthiness and utility (i.e., functional effectiveness) are positively related. Secondly, our observations reveal that proprietary LLMs generally outperform most open-source counterparts in terms of trustworthiness, raising concerns about the potential risks of widely accessible open-source LLMs. However, a few open-source LLMs come very close to proprietary ones. Thirdly, it is important to note that some LLMs may be overly calibrated towards exhibiting trustworthiness, to the extent that they compromise their utility by mistakenly treating benign prompts as harmful and consequently not responding. Finally, we emphasize the importance of ensuring transparency not only in the models themselves but also in the technologies that underpin trustworthiness. Knowing the specific trustworthy technologies that have been employed is crucial for analyzing their effectiveness.
Analyzing the Quality Attributes of AI Vision Models in Open Repositories Under Adversarial Attacks
Jan 22, 2024



As AI models rapidly evolve, they are frequently released to open repositories, such as HuggingFace. It is essential to perform quality assurance validation on these models before integrating them into the production development lifecycle. In addition to evaluating efficiency in terms of balanced accuracy and computing costs, adversarial attacks are potential threats to the robustness and explainability of AI models. Meanwhile, XAI applies algorithms that approximate inputs to outputs post-hoc to identify the contributing features. Adversarial perturbations may also degrade the utility of XAI explanations that require further investigation. In this paper, we present an integrated process designed for downstream evaluation tasks, including validating AI model accuracy, evaluating robustness with benchmark perturbations, comparing explanation utility, and assessing overhead. We demonstrate an evaluation scenario involving six computer vision models, which include CNN-based, Transformer-based, and hybrid architectures, three types of perturbations, and five XAI methods, resulting in ninety unique combinations. The process reveals the explanation utility among the XAI methods in terms of the identified key areas responding to the adversarial perturbation. The process produces aggregated results that illustrate multiple attributes of each AI model.