 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Open API Architecture to Discover the Trustworthy Explanation of Cloud AI Services
Nov 05, 2024



This article presents the design of an open-API-based explainable AI (XAI) service to provide feature contribution explanations for cloud AI services. Cloud AI services are widely used to develop domain-specific applications with precise learning metrics. However, the underlying cloud AI services remain opaque on how the model produces the prediction. We argue that XAI operations are accessible as open APIs to enable the consolidation of the XAI operations into the cloud AI services assessment. We propose a design using a microservice architecture that offers feature contribution explanations for cloud AI services without unfolding the network structure of the cloud models. We can also utilize this architecture to evaluate the model performance and XAI consistency metrics showing cloud AI services trustworthiness. We collect provenance data from operational pipelines to enable reproducibility within the XAI service. Furthermore, we present the discovery scenarios for the experimental tests regarding model performance and XAI consistency metrics for the leading cloud vision AI services. The results confirm that the architecture, based on open APIs, is cloud-agnostic. Additionally, data augmentations result in measurable improvements in XAI consistency metrics for cloud AI services.
* Published in: IEEE Transactions on Cloud Computing ( Volume: 12, Issue: 2, April-June 2024)
STAA: Spatio-Temporal Attention Attribution for Real-Time Interpreting Transformer-based Video Models
Nov 01, 2024Transformer-based models have achieved state-of-the-art performance in various computer vision tasks, including image and video analysis. However, Transformer's complex architecture and black-box nature pose challenges for explainability, a crucial aspect for real-world applications and scientific inquiry. Current Explainable AI (XAI) methods can only provide one-dimensional feature importance, either spatial or temporal explanation, with significant computational complexity. This paper introduces STAA (Spatio-Temporal Attention Attribution), an XAI method for interpreting video Transformer models. Differ from traditional methods that separately apply image XAI techniques for spatial features or segment contribution analysis for temporal aspects, STAA offers both spatial and temporal information simultaneously from attention values in Transformers. The study utilizes the Kinetics-400 dataset, a benchmark collection of 400 human action classes used for action recognition research. We introduce metrics to quantify explanations. We also apply optimization to enhance STAA's raw output. By implementing dynamic thresholding and attention focusing mechanisms, we improve the signal-to-noise ratio in our explanations, resulting in more precise visualizations and better evaluation results. In terms of computational overhead, our method requires less than 3\% of the computational resources of traditional XAI methods, making it suitable for real-time video XAI analysis applications. STAA contributes to the growing field of XAI by offering a method for researchers and practitioners to analyze Transformer models.
PackMamba: Efficient Processing of Variable-Length Sequences in Mamba training
Aug 07, 2024



With the evolution of large language models, traditional Transformer models become computationally demanding for lengthy sequences due to the quadratic growth in computation with respect to the sequence length. Mamba, emerging as a groundbreaking architecture in the field of generative AI, demonstrates remarkable proficiency in handling elongated sequences with reduced computational and memory complexity. Nevertheless, the existing training framework of Mamba presents inefficiency with variable-length sequence inputs. Either single-sequence training results in low GPU utilization, or batched processing of variable-length sequences to a maximum length incurs considerable memory and computational overhead. To address this problem, we analyze the performance of bottleneck operators in Mamba under diverse tensor shapes and proposed PackMamba, a high-throughput Mamba that efficiently handles variable-length sequences. Diving deep into state-space models (SSMs), we modify the parallel operators to avoid passing information between individual sequences while maintaining high performance. Experimental results on an NVIDIA A100 GPU demonstrate throughput exceeding the baseline single-sequence processing scheme: 3.06x speedup on the 1.4B model and 2.62x on the 2.8B model.
XAIport: A Service Framework for the Early Adoption of XAI in AI Model Development
Mar 25, 2024


In this study, we propose the early adoption of Explainable AI (XAI) with a focus on three properties: Quality of explanation, the explanation summaries should be consistent across multiple XAI methods; Architectural Compatibility, for effective integration in XAI, the architecture styles of both the XAI methods and the models to be explained must be compatible with the framework; Configurable operations, XAI explanations are operable, akin to machine learning operations. Thus, an explanation for AI models should be reproducible and tractable to be trustworthy. We present XAIport, a framework of XAI microservices encapsulated into Open APIs to deliver early explanations as observation for learning model quality assurance. XAIport enables configurable XAI operations along with machine learning development. We quantify the operational costs of incorporating XAI with three cloud computer vision services on Microsoft Azure Cognitive Services, Google Cloud Vertex AI, and Amazon Rekognition. Our findings show comparable operational costs between XAI and traditional machine learning, with XAIport significantly improving both cloud AI model performance and explanation stability.
Characterization of Large Language Model Development in the Datacenter
Mar 12, 2024Large Language Models (LLMs) have presented impressive performance across several transformative tasks. However, it is non-trivial to efficiently utilize large-scale cluster resources to develop LLMs, often riddled with numerous challenges such as frequent hardware failures, intricate parallelization strategies, and imbalanced resource utilization. In this paper, we present an in-depth characterization study of a six-month LLM development workload trace collected from our GPU datacenter Acme. Specifically, we investigate discrepancies between LLMs and prior task-specific Deep Learning (DL) workloads, explore resource utilization patterns, and identify the impact of various job failures. Our analysis summarizes hurdles we encountered and uncovers potential opportunities to optimize systems tailored for LLMs. Furthermore, we introduce our system efforts: (1) fault-tolerant pretraining, which enhances fault tolerance through LLM-involved failure diagnosis and automatic recovery. (2) decoupled scheduling for evaluation, which achieves timely performance feedback via trial decomposition and scheduling optimization.
Analyzing the Quality Attributes of AI Vision Models in Open Repositories Under Adversarial Attacks
Jan 22, 2024



As AI models rapidly evolve, they are frequently released to open repositories, such as HuggingFace. It is essential to perform quality assurance validation on these models before integrating them into the production development lifecycle. In addition to evaluating efficiency in terms of balanced accuracy and computing costs, adversarial attacks are potential threats to the robustness and explainability of AI models. Meanwhile, XAI applies algorithms that approximate inputs to outputs post-hoc to identify the contributing features. Adversarial perturbations may also degrade the utility of XAI explanations that require further investigation. In this paper, we present an integrated process designed for downstream evaluation tasks, including validating AI model accuracy, evaluating robustness with benchmark perturbations, comparing explanation utility, and assessing overhead. We demonstrate an evaluation scenario involving six computer vision models, which include CNN-based, Transformer-based, and hybrid architectures, three types of perturbations, and five XAI methods, resulting in ninety unique combinations. The process reveals the explanation utility among the XAI methods in terms of the identified key areas responding to the adversarial perturbation. The process produces aggregated results that illustrate multiple attributes of each AI model.
Visual-Kinematics Graph Learning for Procedure-agnostic Instrument Tip Segmentation in Robotic Surgeries
Sep 02, 2023



Accurate segmentation of surgical instrument tip is an important task for enabling downstream applications in robotic surgery, such as surgical skill assessment, tool-tissue interaction and deformation modeling, as well as surgical autonomy. However, this task is very challenging due to the small sizes of surgical instrument tips, and significant variance of surgical scenes across different procedures. Although much effort has been made on visual-based methods, existing segmentation models still suffer from low robustness thus not usable in practice. Fortunately, kinematics data from the robotic system can provide reliable prior for instrument location, which is consistent regardless of different surgery types. To make use of such multi-modal information, we propose a novel visual-kinematics graph learning framework to accurately segment the instrument tip given various surgical procedures. Specifically, a graph learning framework is proposed to encode relational features of instrument parts from both image and kinematics. Next, a cross-modal contrastive loss is designed to incorporate robust geometric prior from kinematics to image for tip segmentation. We have conducted experiments on a private paired visual-kinematics dataset including multiple procedures, i.e., prostatectomy, total mesorectal excision, fundoplication and distal gastrectomy on cadaver, and distal gastrectomy on porcine. The leave-one-procedure-out cross validation demonstrated that our proposed multi-modal segmentation method significantly outperformed current image-based state-of-the-art approaches, exceeding averagely 11.2% on Dice.
A Versatile Data-Driven Framework for Model-Independent Control of Continuum Manipulators Interacting With Obstructed Environments With Unknown Geometry and Stiffness
May 05, 2020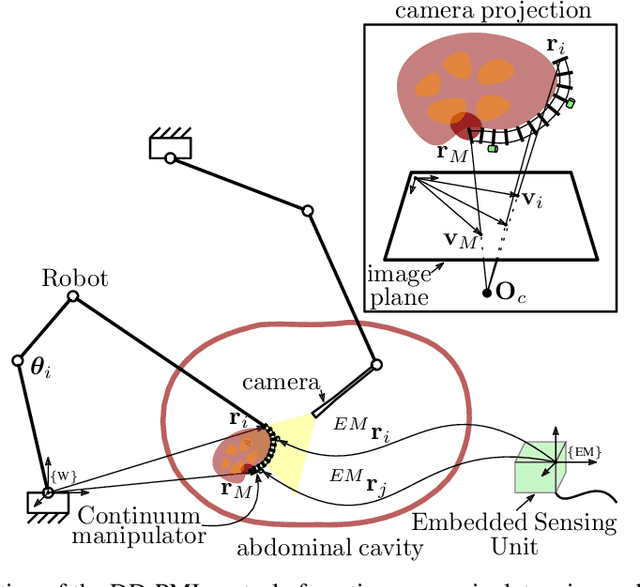
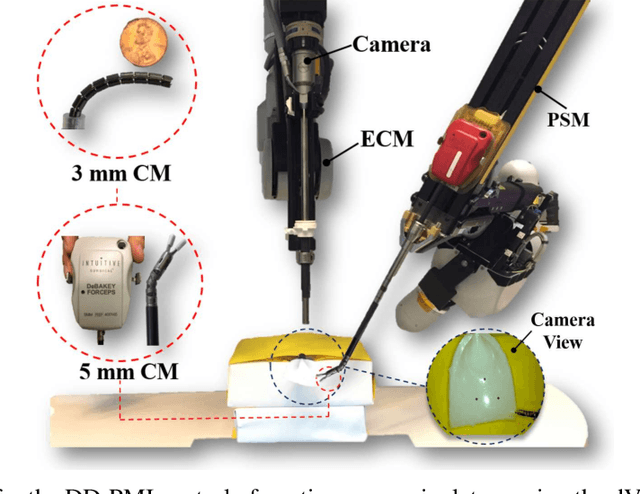
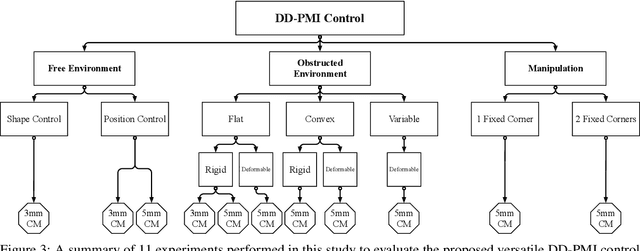
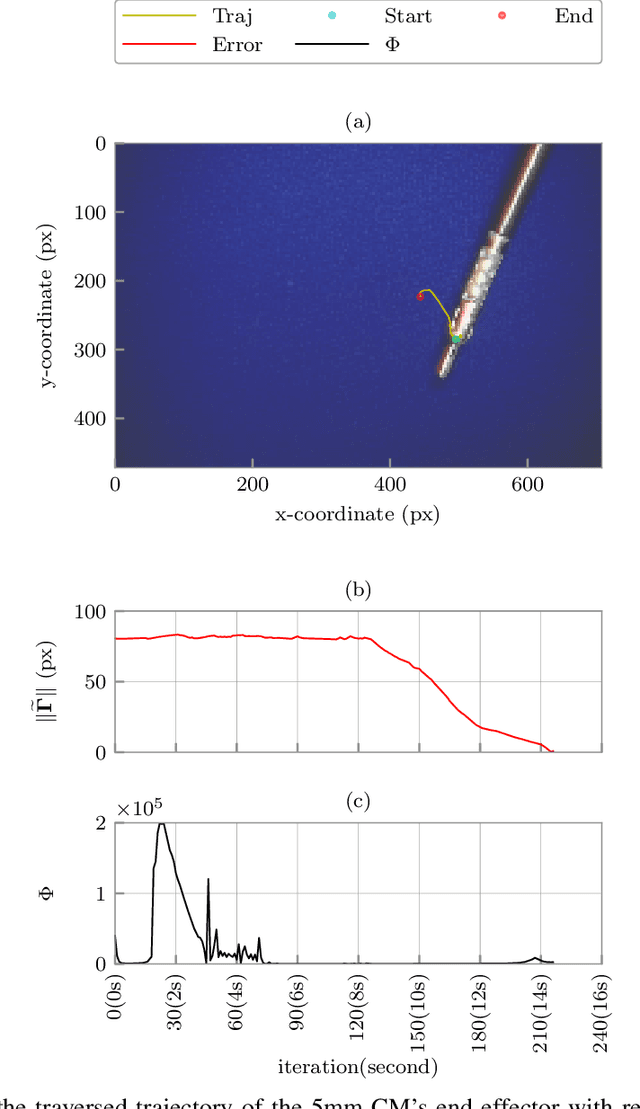
This paper addresses the problem of controlling a continuum manipulator (CM) in free or obstructed environments with no prior knowledge about the deformation behavior of the CM and the stiffness and geometry of the interacting obstructed environment. We propose a versatile data-driven priori-model-independent (PMI) control framework, in which various control paradigms (e.g. CM's position or shape control) can be defined based on the provided feedback. This optimal iterative algorithm learns the deformation behavior of the CM in interaction with an unknown environment, in real time, and then accomplishes the defined control objective. To evaluate the scalability of the proposed framework, we integrated two different CMs, designed for medical applications, with the da Vinci Research Kit (dVRK). The performance and learning capability of the framework was investigated in 11 sets of experiments including PMI position and shape control in free and unknown obstructed environments as well as during manipulation of an unknown deformable object. We also evaluated the performance of our algorithm in an ex-vivo experiment with a lamb heart.The theoretical and experimental results demonstrate the adaptivity, versatility, and accuracy of the proposed framework and, therefore, its suitability for a variety of applications involving continuum manipulators.