 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmerging Extrinsic Dexterity in Cluttered Scenes via Dynamics-aware Policy Learning
Mar 10, 2026Extrinsic dexterity leverages environmental contact to overcome the limitations of prehensile manipulation. However, achieving such dexterity in cluttered scenes remains challenging and underexplored, as it requires selectively exploiting contact among multiple interacting objects with inherently coupled dynamics. Existing approaches lack explicit modeling of such complex dynamics and therefore fall short in non-prehensile manipulation in cluttered environments, which in turn limits their practical applicability in real-world environments. In this paper, we introduce a Dynamics-Aware Policy Learning (DAPL) framework that can facilitate policy learning with a learned representation of contact-induced object dynamics in cluttered environments. This representation is learned through explicit world modeling and used to condition reinforcement learning, enabling extrinsic dexterity to emerge without hand-crafted contact heuristics or complex reward shaping. We evaluate our approach in both simulation and the real world. Our method outperforms prehensile manipulation, human teleoperation, and prior representation-based policies by over 25% in success rate on unseen simulated cluttered scenes with varying densities. The real-world success rate reaches around 50% across 10 cluttered scenes, while a practical grocery deployment further demonstrates robust sim-to-real transfer and applicability.
LDA-1B: Scaling Latent Dynamics Action Model via Universal Embodied Data Ingestion
Feb 12, 2026Recent robot foundation models largely rely on large-scale behavior cloning, which imitates expert actions but discards transferable dynamics knowledge embedded in heterogeneous embodied data. While the Unified World Model (UWM) formulation has the potential to leverage such diverse data, existing instantiations struggle to scale to foundation-level due to coarse data usage and fragmented datasets. We introduce LDA-1B, a robot foundation model that scales through universal embodied data ingestion by jointly learning dynamics, policy, and visual forecasting, assigning distinct roles to data of varying quality. To support this regime at scale, we assemble and standardize EI-30k, an embodied interaction dataset comprising over 30k hours of human and robot trajectories in a unified format. Scalable dynamics learning over such heterogeneous data is enabled by prediction in a structured DINO latent space, which avoids redundant pixel-space appearance modeling. Complementing this representation, LDA-1B employs a multi-modal diffusion transformer to handle asynchronous vision and action streams, enabling stable training at the 1B-parameter scale. Experiments in simulation and the real world show LDA-1B outperforms prior methods (e.g., $π_{0.5}$) by up to 21\%, 48\%, and 23\% on contact-rich, dexterous, and long-horizon tasks, respectively. Notably, LDA-1B enables data-efficient fine-tuning, gaining 10\% by leveraging 30\% low-quality trajectories typically harmful and discarded.
Collision-Free Humanoid Traversal in Cluttered Indoor Scenes
Jan 23, 2026We study the problem of collision-free humanoid traversal in cluttered indoor scenes, such as hurdling over objects scattered on the floor, crouching under low-hanging obstacles, or squeezing through narrow passages. To achieve this goal, the humanoid needs to map its perception of surrounding obstacles with diverse spatial layouts and geometries to the corresponding traversal skills. However, the lack of an effective representation that captures humanoid-obstacle relationships during collision avoidance makes directly learning such mappings difficult. We therefore propose Humanoid Potential Field (HumanoidPF), which encodes these relationships as collision-free motion directions, significantly facilitating RL-based traversal skill learning. We also find that HumanoidPF exhibits a surprisingly negligible sim-to-real gap as a perceptual representation. To further enable generalizable traversal skills through diverse and challenging cluttered indoor scenes, we further propose a hybrid scene generation method, incorporating crops of realistic 3D indoor scenes and procedurally synthesized obstacles. We successfully transfer our policy to the real world and develop a teleoperation system where users could command the humanoid to traverse in cluttered indoor scenes with just a single click. Extensive experiments are conducted in both simulation and the real world to validate the effectiveness of our method. Demos and code can be found in our website: https://axian12138.github.io/CAT/.
DyWA: Dynamics-adaptive World Action Model for Generalizable Non-prehensile Manipulation
Mar 21, 2025



Nonprehensile manipulation is crucial for handling objects that are too thin, large, or otherwise ungraspable in unstructured environments. While conventional planning-based approaches struggle with complex contact modeling, learning-based methods have recently emerged as a promising alternative. However, existing learning-based approaches face two major limitations: they heavily rely on multi-view cameras and precise pose tracking, and they fail to generalize across varying physical conditions, such as changes in object mass and table friction. To address these challenges, we propose the Dynamics-Adaptive World Action Model (DyWA), a novel framework that enhances action learning by jointly predicting future states while adapting to dynamics variations based on historical trajectories. By unifying the modeling of geometry, state, physics, and robot actions, DyWA enables more robust policy learning under partial observability. Compared to baselines, our method improves the success rate by 31.5% using only single-view point cloud observations in the simulation. Furthermore, DyWA achieves an average success rate of 68% in real-world experiments, demonstrating its ability to generalize across diverse object geometries, adapt to varying table friction, and robustness in challenging scenarios such as half-filled water bottles and slippery surfaces.
FetchBot: Object Fetching in Cluttered Shelves via Zero-Shot Sim2Real
Feb 25, 2025



Object fetching from cluttered shelves is an important capability for robots to assist humans in real-world scenarios. Achieving this task demands robotic behaviors that prioritize safety by minimizing disturbances to surrounding objects, an essential but highly challenging requirement due to restricted motion space, limited fields of view, and complex object dynamics. In this paper, we introduce FetchBot, a sim-to-real framework designed to enable zero-shot generalizable and safety-aware object fetching from cluttered shelves in real-world settings. To address data scarcity, we propose an efficient voxel-based method for generating diverse simulated cluttered shelf scenes at scale and train a dynamics-aware reinforcement learning (RL) policy to generate object fetching trajectories within these scenes. This RL policy, which leverages oracle information, is subsequently distilled into a vision-based policy for real-world deployment. Considering that sim-to-real discrepancies stem from texture variations mostly while from geometric dimensions rarely, we propose to adopt depth information estimated by full-fledged depth foundation models as the input for the vision-based policy to mitigate sim-to-real gap. To tackle the challenge of limited views, we design a novel architecture for learning multi-view representations, allowing for comprehensive encoding of cluttered shelf scenes. This enables FetchBot to effectively minimize collisions while fetching objects from varying positions and depths, ensuring robust and safety-aware operation. Both simulation and real-robot experiments demonstrate FetchBot's superior generalization ability, particularly in handling a broad range of real-world scenarios, includ
A General Framework for Lifelong Localization and Mapping in Changing Environment
Nov 22, 2021
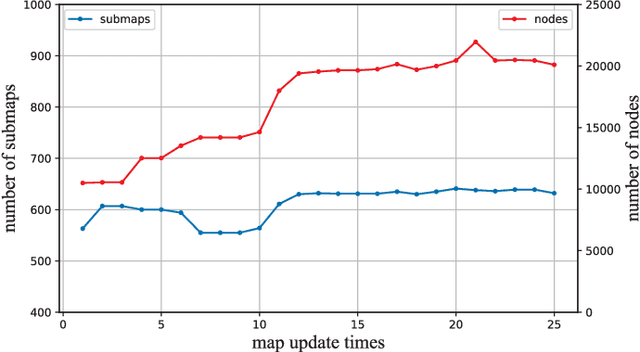
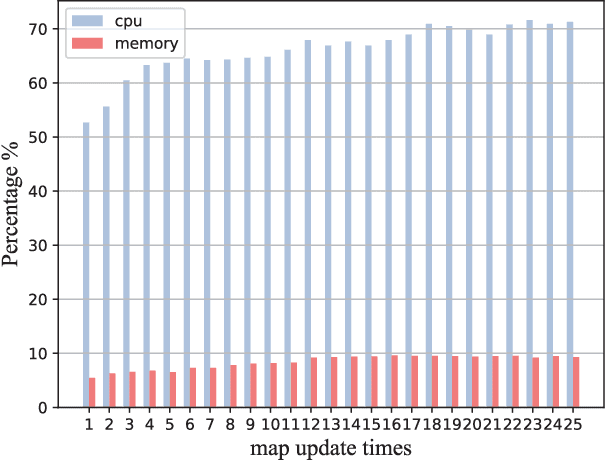
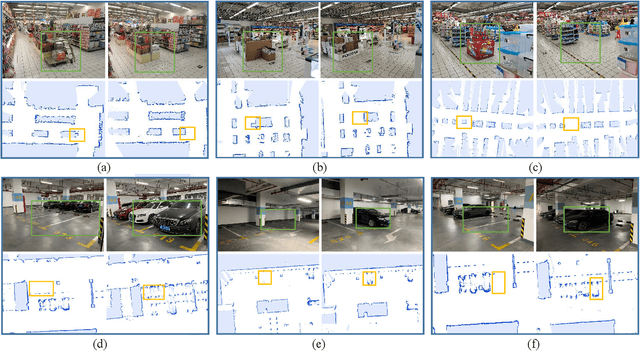
The environment of most real-world scenarios such as malls and supermarkets changes at all times. A pre-built map that does not account for these changes becomes out-of-date easily. Therefore, it is necessary to have an up-to-date model of the environment to facilitate long-term operation of a robot. To this end, this paper presents a general lifelong simultaneous localization and mapping (SLAM) framework. Our framework uses a multiple session map representation, and exploits an efficient map updating strategy that includes map building, pose graph refinement and sparsification. To mitigate the unbounded increase of memory usage, we propose a map-trimming method based on the Chow-Liu maximum-mutual-information spanning tree. The proposed SLAM framework has been comprehensively validated by over a month of robot deployment in real supermarket environment. Furthermore, we release the dataset collected from the indoor and outdoor changing environment with the hope to accelerate lifelong SLAM research in the community. Our dataset is available at https://github.com/sanduan168/lifelong-SLAM-dataset.
Hierarchical Segment-based Optimization for SLAM
Nov 07, 2021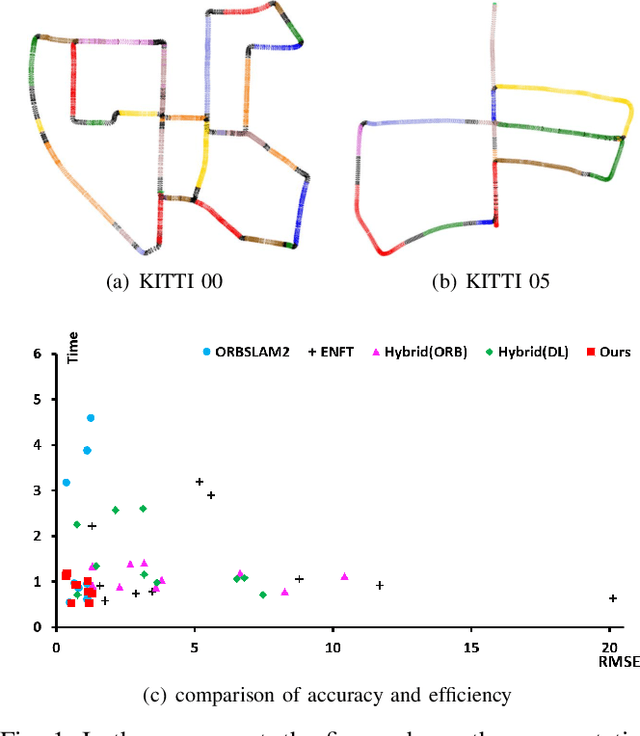
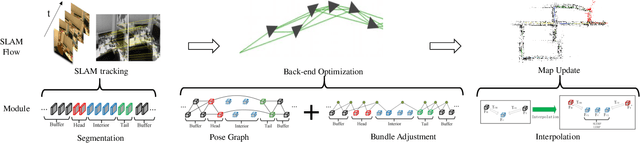
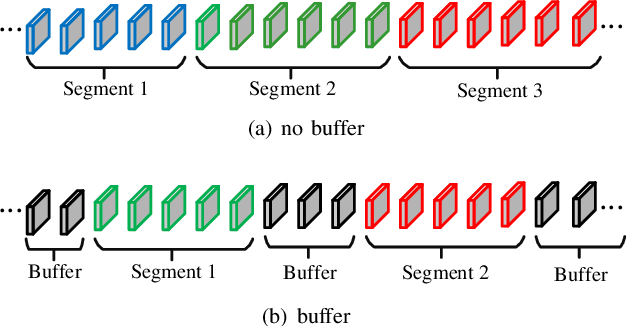
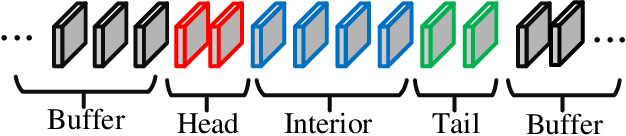
This paper presents a hierarchical segment-based optimization method for Simultaneous Localization and Mapping (SLAM) system. First we propose a reliable trajectory segmentation method that can be used to increase efficiency in the back-end optimization. Then we propose a buffer mechanism for the first time to improve the robustness of the segmentation. During the optimization, we use global information to optimize the frames with large error, and interpolation instead of optimization to update well-estimated frames to hierarchically allocate the amount of computation according to error of each frame. Comparative experiments on the benchmark show that our method greatly improves the efficiency of optimization with almost no drop in accuracy, and outperforms existing high-efficiency optimization method by a large margin.
Robust SLAM Systems: Are We There Yet?
Sep 27, 2021
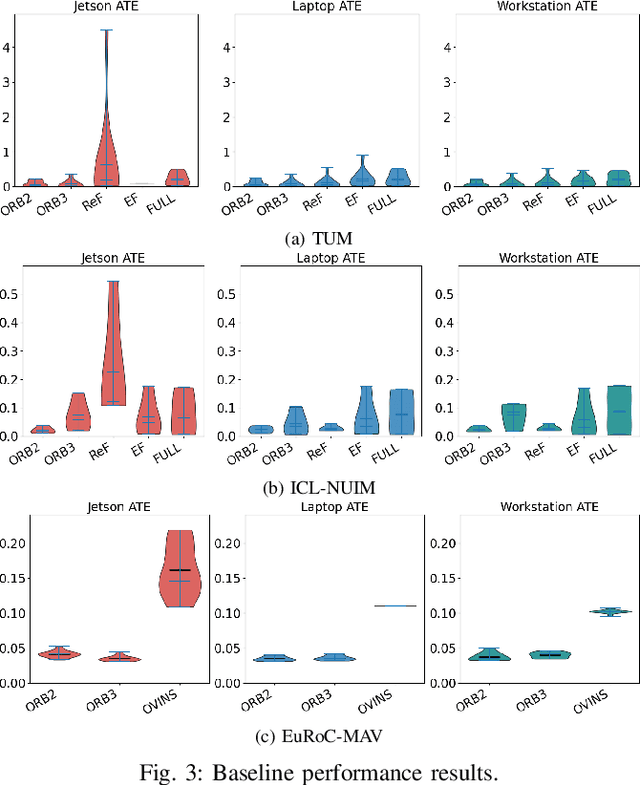
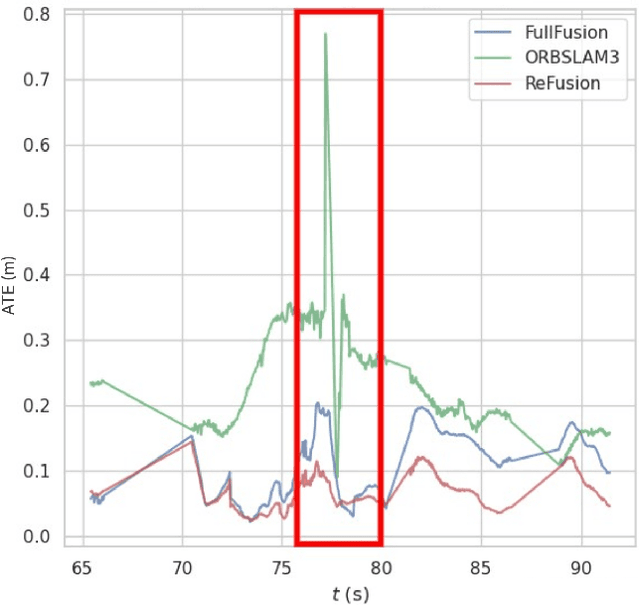
Progress in the last decade has brought about significant improvements in the accuracy and speed of SLAM systems, broadening their mapping capabilities. Despite these advancements, long-term operation remains a major challenge, primarily due to the wide spectrum of perturbations robotic systems may encounter. Increasing the robustness of SLAM algorithms is an ongoing effort, however it usually addresses a specific perturbation. Generalisation of robustness across a large variety of challenging scenarios is not well-studied nor understood. This paper presents a systematic evaluation of the robustness of open-source state-of-the-art SLAM algorithms with respect to challenging conditions such as fast motion, non-uniform illumination, and dynamic scenes. The experiments are performed with perturbations present both independently of each other, as well as in combination in long-term deployment settings in unconstrained environments (lifelong operation).
Continual Neural Mapping: Learning An Implicit Scene Representation from Sequential Observations
Aug 12, 2021
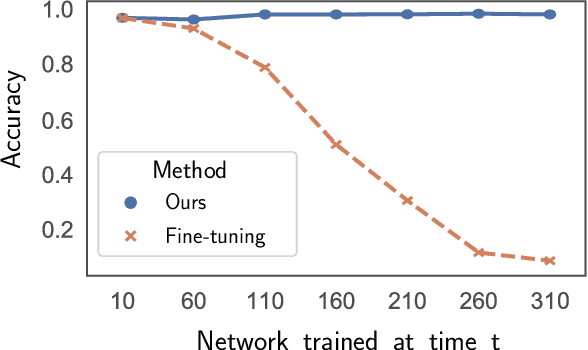
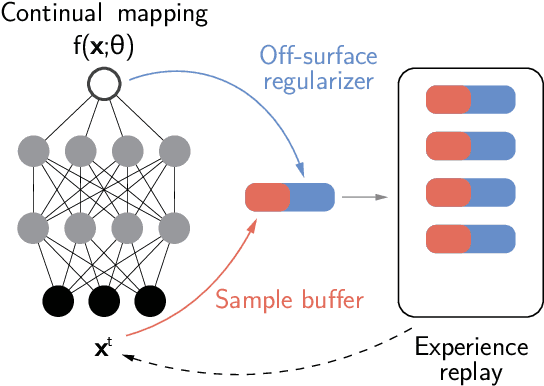
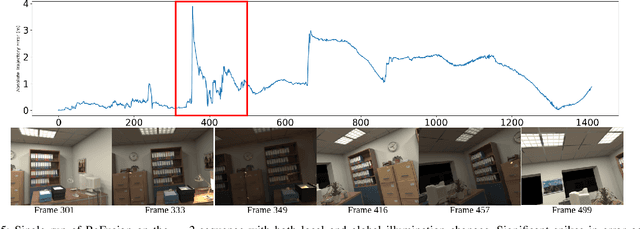
Recent advances have enabled a single neural network to serve as an implicit scene representation, establishing the mapping function between spatial coordinates and scene properties. In this paper, we make a further step towards continual learning of the implicit scene representation directly from sequential observations, namely Continual Neural Mapping. The proposed problem setting bridges the gap between batch-trained implicit neural representations and commonly used streaming data in robotics and vision communities. We introduce an experience replay approach to tackle an exemplary task of continual neural mapping: approximating a continuous signed distance function (SDF) from sequential depth images as a scene geometry representation. We show for the first time that a single network can represent scene geometry over time continually without catastrophic forgetting, while achieving promising trade-offs between accuracy and efficiency.
A Collaborative Visual SLAM Framework for Service Robots
Feb 05, 2021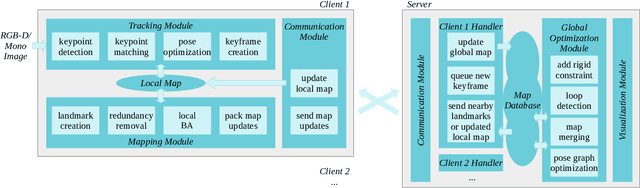
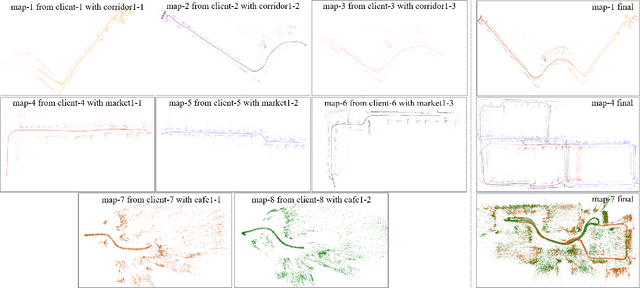
With the rapid deployment of service robots, a method should be established to allow multiple robots to work in the same place to collaborate and share the spatial information. To this end, we present a collaborative visual simultaneous localization and mapping (SLAM) framework particularly designed for service robot scenarios. With an edge server maintaining a map database and performing global optimization, each robot can register to an existing map, update the map, or build new maps, all with a unified interface and low computation and memory cost. To enable real-time information sharing, an efficient landmark retrieval method is proposed to allow each robot to get nearby landmarks observed by others. The framework is general enough to support both RGB-D and monocular cameras, as well as robots with multiple cameras, taking the rigid constraints between cameras into consideration. The proposed framework has been fully implemented and verified with public datasets and live experiments.