 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeL-SDPPO: Policy Optimization of Spiking Diffusion Policy for Intra-vehicular Robotic Manipulation
Jun 04, 2026Intra-vehicular robots in spacecraft help reduce astronaut workload and improve mission efficiency. Recent research focuses on using deep learning methods to achieve the acute control required for operations in these complex environments. However, objects exhibit unpredictable, unconstrained drift without gravitational damping. These factors demand robustness against complex multimodal action distributions. Diffusion policies (DP) can model these complex actions, but their iterative sampling process consumes too much energy for the limited power budgets of spacecraft. We therefore propose a low-energy intra-vehicular robotic manipulation framework, L-SDPPO, in which the Spiking Diffusion Policy (SDP) is optimized with a reinforcement learning (RL) algorithm. Furthermore, to address the insufficient perception of dynamic spatiotemporal features in microgravity, we propose the statedependent latency injection (SDLI) mechanism, which mimics biological neural delays to dynamically regulate the timing of input information. Evaluation on five representative intra-vehicular daily tasks (e.g., hatch opening and precision container capping) shows that our method consistently achieves higher success rates and lower energy consumption, compared to the state-of-the-art robotic manipulation methods. These results demonstrate our method is a viable intra-vehicular robotic manipulation method.
NutVLM: A Self-Adaptive Defense Framework against Full-Dimension Attacks for Vision Language Models in Autonomous Driving
Feb 09, 2026Vision Language Models (VLMs) have advanced perception in autonomous driving (AD), but they remain vulnerable to adversarial threats. These risks range from localized physical patches to imperceptible global perturbations. Existing defense methods for VLMs remain limited and often fail to reconcile robustness with clean-sample performance. To bridge these gaps, we propose NutVLM, a comprehensive self-adaptive defense framework designed to secure the entire perception-decision lifecycle. Specifically, we first employ NutNet++ as a sentinel, which is a unified detection-purification mechanism. It identifies benign samples, local patches, and global perturbations through three-way classification. Subsequently, localized threats are purified via efficient grayscale masking, while global perturbations trigger Expert-guided Adversarial Prompt Tuning (EAPT). Instead of the costly parameter updates of full-model fine-tuning, EAPT generates "corrective driving prompts" via gradient-based latent optimization and discrete projection. These prompts refocus the VLM's attention without requiring exhaustive full-model retraining. Evaluated on the Dolphins benchmark, our NutVLM yields a 4.89% improvement in overall metrics (e.g., Accuracy, Language Score, and GPT Score). These results validate NutVLM as a scalable security solution for intelligent transportation. Our code is available at https://github.com/PXX/NutVLM.
Imitation learning-based spacecraft rendezvous and docking method with Expert Demonstration
Jan 19, 2026Existing spacecraft rendezvous and docking control methods largely rely on predefined dynamic models and often exhibit limited robustness in realistic on-orbit environments. To address this issue, this paper proposes an Imitation Learning-based spacecraft rendezvous and docking control framework (IL-SRD) that directly learns control policies from expert demonstrations, thereby reducing dependence on accurate modeling. We propose an anchored decoder target mechanism, which conditions the decoder queries on state-related anchors to explicitly constrain the control generation process. This mechanism enforces physically consistent control evolution and effectively suppresses implausible action deviations in sequential prediction, enabling reliable six-degree-of-freedom (6-DOF) rendezvous and docking control. To further enhance stability, a temporal aggregation mechanism is incorporated to mitigate error accumulation caused by the sequential prediction nature of Transformer-based models, where small inaccuracies at each time step can propagate and amplify over long horizons. Extensive simulation results demonstrate that the proposed IL-SRD framework achieves accurate and energy-efficient model-free rendezvous and docking control. Robustness evaluations further confirm its capability to maintain competitive performance under significant unknown disturbances. The source code is available at https://github.com/Dongzhou-1996/IL-SRD.
Multimodal Spiking Neural Network for Space Robotic Manipulation
Aug 10, 2025



This paper presents a multimodal control framework based on spiking neural networks (SNNs) for robotic arms aboard space stations. It is designed to cope with the constraints of limited onboard resources while enabling autonomous manipulation and material transfer in space operations. By combining geometric states with tactile and semantic information, the framework strengthens environmental awareness and contributes to more robust control strategies. To guide the learning process progressively, a dual-channel, three-stage curriculum reinforcement learning (CRL) scheme is further integrated into the system. The framework was tested across a range of tasks including target approach, object grasping, and stable lifting with wall-mounted robotic arms, demonstrating reliable performance throughout. Experimental evaluations demonstrate that the proposed method consistently outperforms baseline approaches in both task success rate and energy efficiency. These findings highlight its suitability for real-world aerospace applications.
Language-Conditioned Open-Vocabulary Mobile Manipulation with Pretrained Models
Jul 23, 2025Open-vocabulary mobile manipulation (OVMM) that involves the handling of novel and unseen objects across different workspaces remains a significant challenge for real-world robotic applications. In this paper, we propose a novel Language-conditioned Open-Vocabulary Mobile Manipulation framework, named LOVMM, incorporating the large language model (LLM) and vision-language model (VLM) to tackle various mobile manipulation tasks in household environments. Our approach is capable of solving various OVMM tasks with free-form natural language instructions (e.g. "toss the food boxes on the office room desk to the trash bin in the corner", and "pack the bottles from the bed to the box in the guestroom"). Extensive experiments simulated in complex household environments show strong zero-shot generalization and multi-task learning abilities of LOVMM. Moreover, our approach can also generalize to multiple tabletop manipulation tasks and achieve better success rates compared to other state-of-the-art methods.
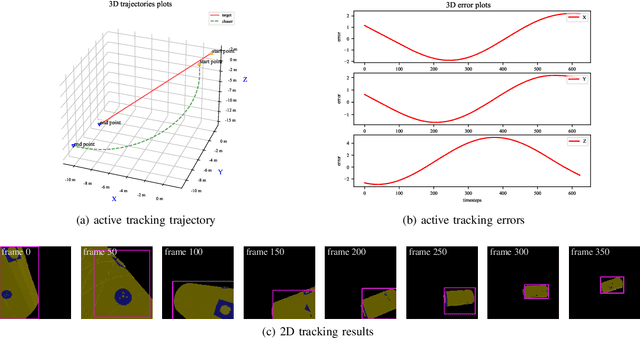
On Deep Recurrent Reinforcement Learning for Active Visual Tracking of Space Noncooperative Objects
Dec 29, 2022Active tracking of space noncooperative object that merely relies on vision camera is greatly significant for autonomous rendezvous and debris removal. Considering its Partial Observable Markov Decision Process (POMDP) property, this paper proposes a novel tracker based on deep recurrent reinforcement learning, named as RAMAVT which drives the chasing spacecraft to follow arbitrary space noncooperative object with high-frequency and near-optimal velocity control commands. To further improve the active tracking performance, we introduce Multi-Head Attention (MHA) module and Squeeze-and-Excitation (SE) layer into RAMAVT, which remarkably improve the representative ability of neural network with almost no extra computational cost. Extensive experiments and ablation study implemented on SNCOAT benchmark show the effectiveness and robustness of our method compared with other state-of-the-art algorithm. The source codes are available on https://github.com/Dongzhou-1996/RAMAVT.
Space Non-cooperative Object Active Tracking with Deep Reinforcement Learning
Dec 18, 2021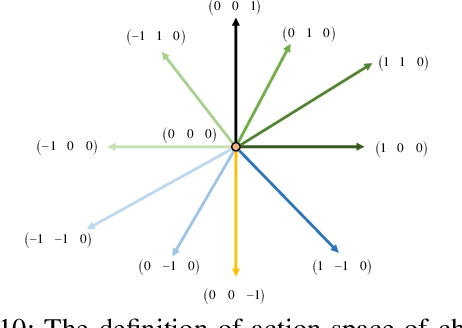
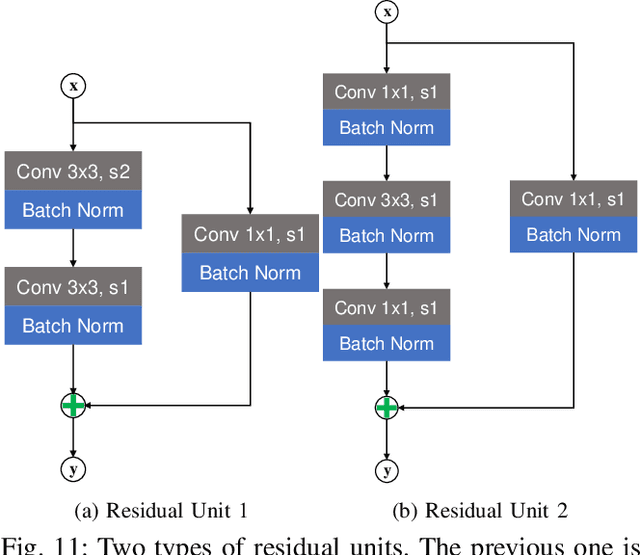
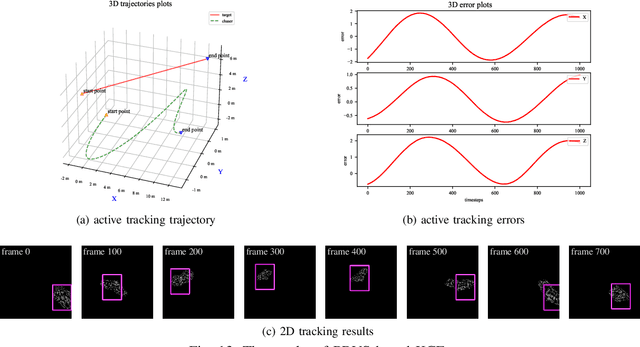
Active visual tracking of space non-cooperative object is significant for future intelligent spacecraft to realise space debris removal, asteroid exploration, autonomous rendezvous and docking. However, existing works often consider this task into different subproblems (e.g. image preprocessing, feature extraction and matching, position and pose estimation, control law design) and optimize each module alone, which are trivial and sub-optimal. To this end, we propose an end-to-end active visual tracking method based on DQN algorithm, named as DRLAVT. It can guide the chasing spacecraft approach to arbitrary space non-cooperative target merely relied on color or RGBD images, which significantly outperforms position-based visual servoing baseline algorithm that adopts state-of-the-art 2D monocular tracker, SiamRPN. Extensive experiments implemented with diverse network architectures, different perturbations and multiple targets demonstrate the advancement and robustness of DRLAVT. In addition, We further prove our method indeed learnt the motion patterns of target with deep reinforcement learning through hundreds of trial-and-errors.
A General Framework for Lifelong Localization and Mapping in Changing Environment
Nov 22, 2021
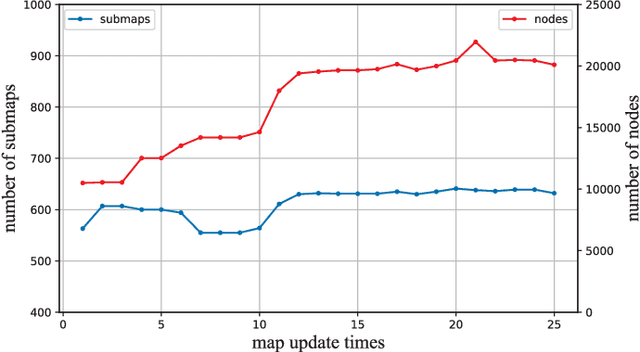
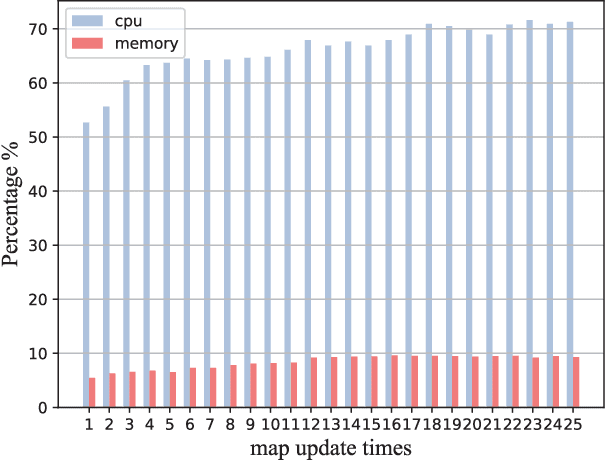
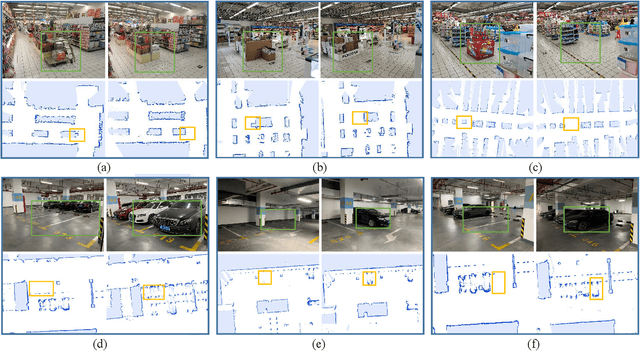
The environment of most real-world scenarios such as malls and supermarkets changes at all times. A pre-built map that does not account for these changes becomes out-of-date easily. Therefore, it is necessary to have an up-to-date model of the environment to facilitate long-term operation of a robot. To this end, this paper presents a general lifelong simultaneous localization and mapping (SLAM) framework. Our framework uses a multiple session map representation, and exploits an efficient map updating strategy that includes map building, pose graph refinement and sparsification. To mitigate the unbounded increase of memory usage, we propose a map-trimming method based on the Chow-Liu maximum-mutual-information spanning tree. The proposed SLAM framework has been comprehensively validated by over a month of robot deployment in real supermarket environment. Furthermore, we release the dataset collected from the indoor and outdoor changing environment with the hope to accelerate lifelong SLAM research in the community. Our dataset is available at https://github.com/sanduan168/lifelong-SLAM-dataset.