 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLP-ICP: General Localizability-Aware Point Cloud Registration for Robust Localization in Extreme Unstructured Environments
Jan 05, 2025



The Iterative Closest Point (ICP) algorithm is a crucial component of LiDAR-based SLAM algorithms. However, its performance can be negatively affected in unstructured environments that lack features and geometric structures, leading to low accuracy and poor robustness in localization and mapping. It is known that degeneracy caused by the lack of geometric constraints can lead to errors in 6-DOF pose estimation along ill-conditioned directions. Therefore, there is a need for a broader and more fine-grained degeneracy detection and handling method. This paper proposes a new point cloud registration framework, LP-ICP, that combines point-to-line and point-to-plane distance metrics in the ICP algorithm, with localizability detection and handling. LP-ICP consists of a localizability detection module and an optimization module. The localizability detection module performs localizability analysis by utilizing the correspondences between edge points (with low local smoothness) to lines and planar points (with high local smoothness) to planes between the scan and the map. The localizability contribution of individual correspondence constraints can be applied to a broader range. The optimization module adds additional soft and hard constraints to the optimization equations based on the localizability category. This allows the pose to be constrained along ill-conditioned directions, with updates either tending towards the constraint value or leaving the initial estimate unchanged. This improves accuracy and reduces fluctuations. The proposed method is extensively evaluated through experiments on both simulation and real-world datasets, demonstrating higher or comparable accuracy than the state-of-the-art methods. The dataset and code of this paper will also be open-sourced at https://github.com/xuqingyuan2000/LP-ICP.
Real-time Local Feature with Global Visual Information Enhancement
Nov 20, 2022



Local feature provides compact and invariant image representation for various visual tasks. Current deep learning-based local feature algorithms always utilize convolution neural network (CNN) architecture with limited receptive field. Besides, even with high-performance GPU devices, the computational efficiency of local features cannot be satisfactory. In this paper, we tackle such problems by proposing a CNN-based local feature algorithm. The proposed method introduces a global enhancement module to fuse global visual clues in a light-weight network, and then optimizes the network by novel deep reinforcement learning scheme from the perspective of local feature matching task. Experiments on the public benchmarks demonstrate that the proposal can achieve considerable robustness against visual interference and meanwhile run in real time.
Center-of-Mass-based Robust Grasp Pose Adaptation Using RGBD Camera and Force/Torque Sensing
May 02, 2022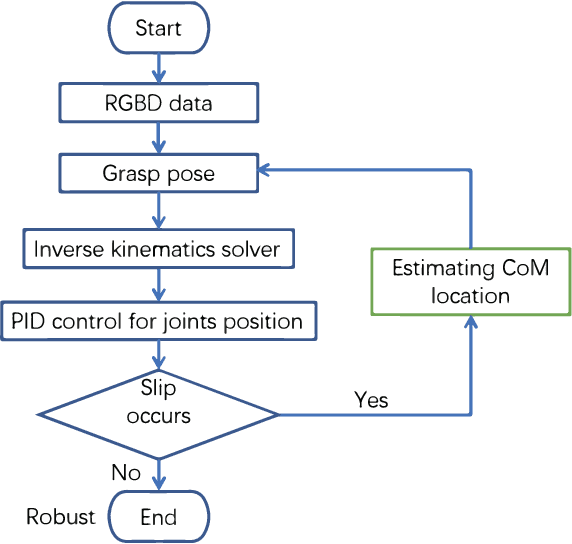
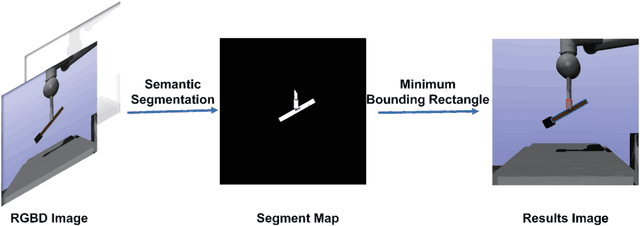
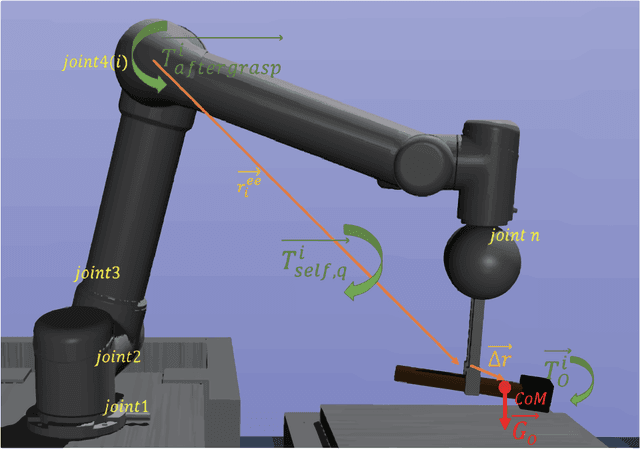
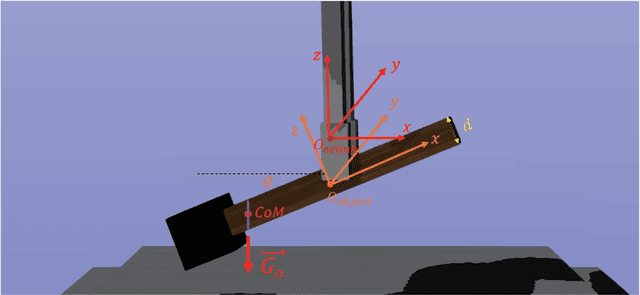
Object dropping may occur when the robotic arm grasps objects with uneven mass distribution due to additional moments generated by objects' gravity. To solve this problem, we present a novel work that does not require extra wrist and tactile sensors and large amounts of experiments for learning. First, we obtain the center-of-mass position of the rod object using the widely fixed joint torque sensors on the robot arm and RGBD camera. Further, we give the strategy of grasping to improve grasp stability. Simulation experiments are performed in "Mujoco". Results demonstrate that our work is effective in enhancing grasping robustness.
Automatic Vocabulary and Graph Verification for Accurate Loop Closure Detection
Jul 30, 2021
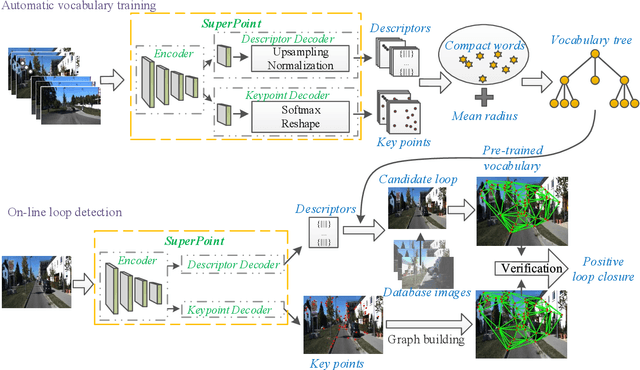
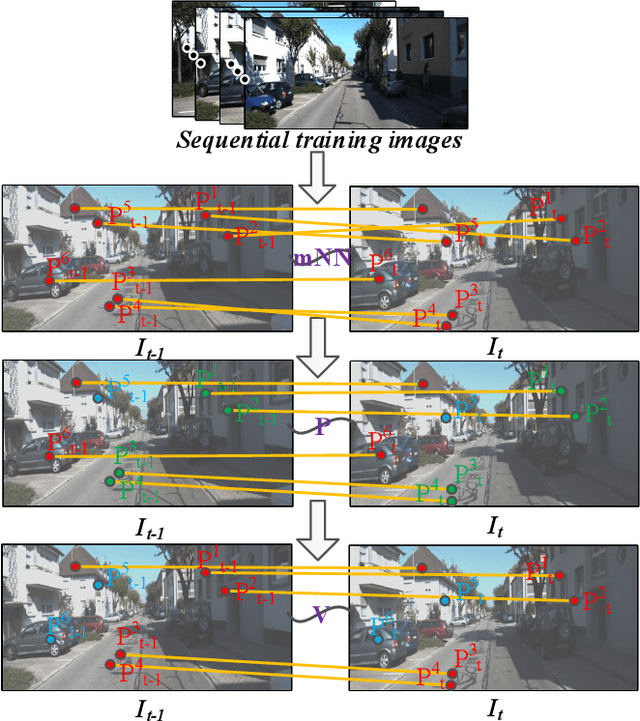
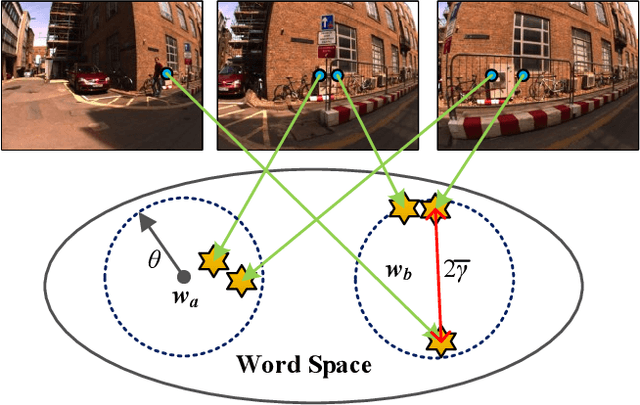
Localizing pre-visited places during long-term simultaneous localization and mapping, i.e. loop closure detection (LCD), is a crucial technique to correct accumulated inconsistencies. As one of the most effective and efficient solutions, Bag-of-Words (BoW) builds a visual vocabulary to associate features and then detect loops. Most existing approaches that build vocabularies off-line determine scales of the vocabulary by trial-and-error, which often results in unreasonable feature association. Moreover, the accuracy of the algorithm usually declines due to perceptual aliasing, as the BoW-based method ignores the positions of visual features. To overcome these disadvantages, we propose a natural convergence criterion based on the comparison between the radii of nodes and the drifts of feature descriptors, which is then utilized to build the optimal vocabulary automatically. Furthermore, we present a novel topological graph verification method for validating candidate loops so that geometrical positions of the words can be involved with a negligible increase in complexity, which can significantly improve the accuracy of LCD. Experiments on various public datasets and comparisons against several state-of-the-art algorithms verify the performance of our proposed approach.
Discriminative and Semantic Feature Selection for Place Recognition towards Dynamic Environments
Mar 21, 2021
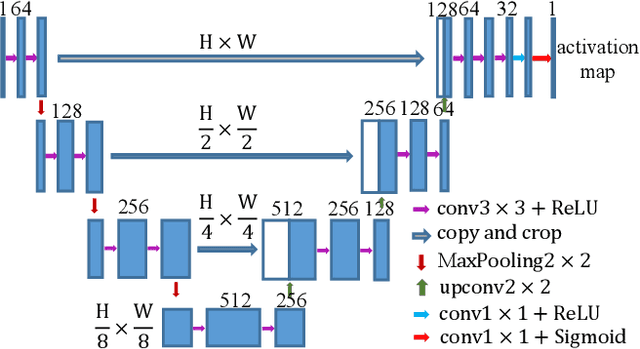
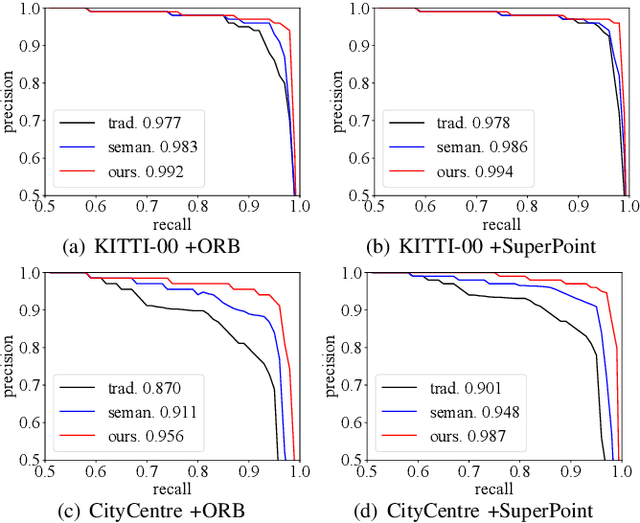
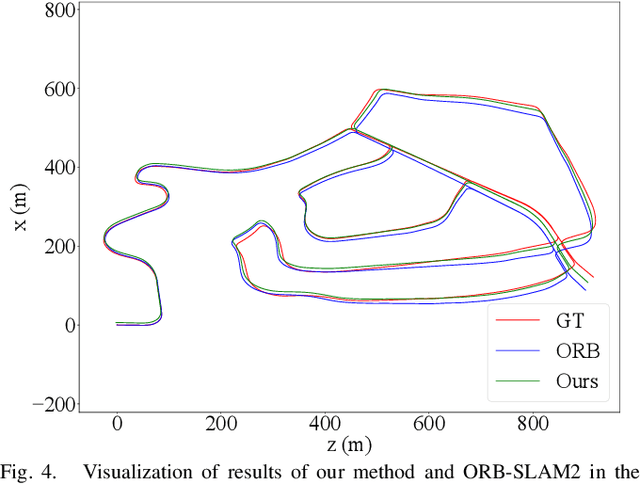
Features play an important role in various visual tasks, especially in visual place recognition applied in perceptual changing environments. In this paper, we address the challenges of place recognition due to dynamics and confusable patterns by proposing a discriminative and semantic feature selection network, dubbed as DSFeat. Supervised by both semantic information and attention mechanism, we can estimate pixel-wise stability of features, indicating the probability of a static and stable region from which features are extracted, and then select features that are insensitive to dynamic interference and distinguishable to be correctly matched. The designed feature selection model is evaluated in place recognition and SLAM system in several public datasets with varying appearances and viewpoints. Experimental results conclude that the effectiveness of the proposed method. It should be noticed that our proposal can be readily pluggable into any feature-based SLAM system.
RaP-Net: A Region-wise and Point-wise Weighting Network to Extract Robust Keypoints for Indoor Localization
Dec 01, 2020

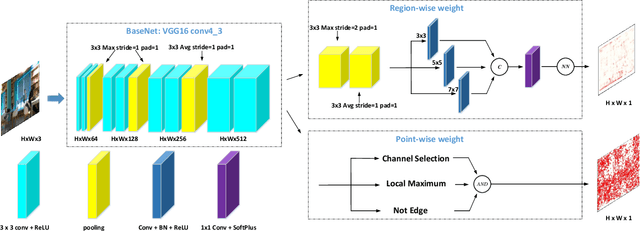
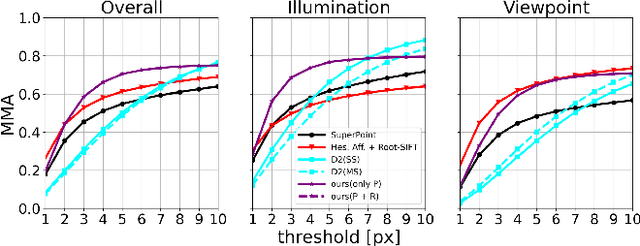
Image keypoint extraction is an important step for visual localization. The localization in indoor environment is challenging for that there may be many unreliable features on dynamic or repetitive objects. Such kind of reliability cannot be well learned by existing Convolutional Neural Network (CNN) based feature extractors. We propose a novel network, RaP-Net, which explicitly addresses feature invariability with a region-wise predictor, and combines it with a point-wise predictor to select reliable keypoints in an image. We also build a new dataset, OpenLORIS-Location, to train this network. The dataset contains 1553 indoor images with location labels. There are various scene changes between images on the same location, which can help a network to learn the invariability in typical indoor scenes. Experimental results show that the proposed RaP-Net trained with the OpenLORIS-Location dataset significantly outperforms existing CNN-based keypoint extraction algorithms for indoor localization. The code and data are available at https://github.com/ivipsourcecode/RaP-Net.